 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient State Representation Learning for Dynamic Robotic Scenarios
Paper and Code
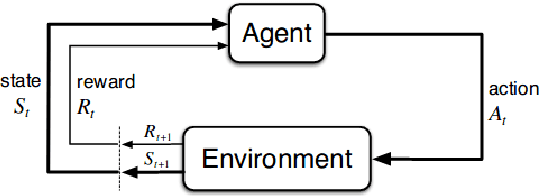
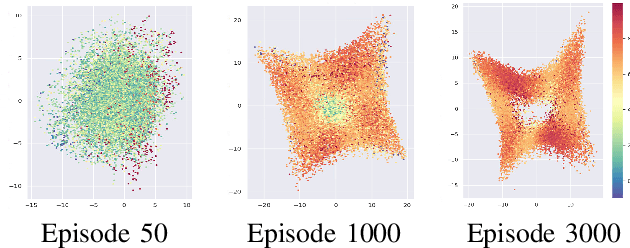
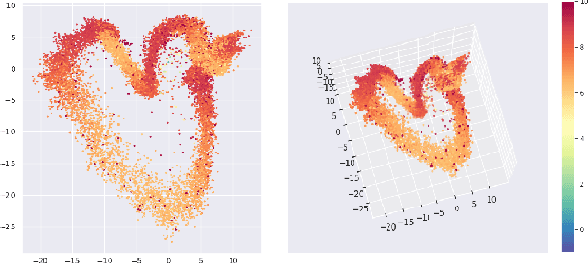
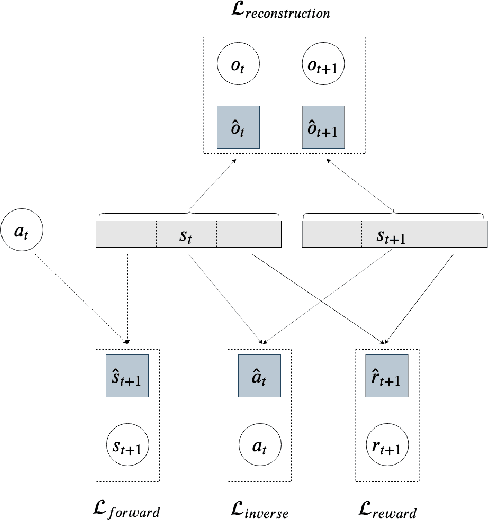
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.