 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Adaptive Chance-Constrained Safeguards for Reinforcement Learning
Oct 05, 2023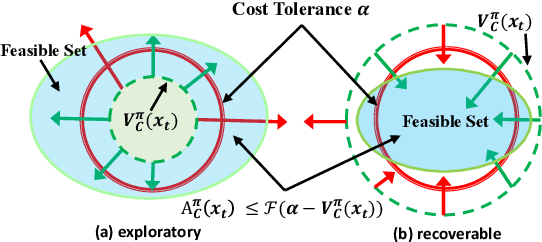
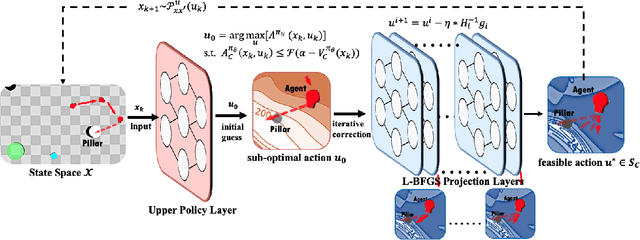


Safety assurance of Reinforcement Learning (RL) is critical for exploration in real-world scenarios. In handling the Constrained Markov Decision Process, current approaches experience intrinsic difficulties in trading-off between optimality and feasibility. Direct optimization methods cannot strictly guarantee state-wise in-training safety while projection-based methods are usually inefficient and correct actions through lengthy iterations. To address these two challenges, this paper proposes an adaptive surrogate chance constraint for the safety cost, and a hierarchical architecture that corrects actions produced by the upper policy layer via a fast Quasi-Newton method. Theoretical analysis indicates that the relaxed probabilistic constraint can sufficiently guarantee forward invariance to the safe set. We validate the proposed method on 4 simulated and real-world safety-critical robotic tasks. Results indicate that the proposed method can efficiently enforce safety (nearly zero-violation), while preserving optimality (+23.8%), robustness and generalizability to stochastic real-world settings.
FLYOVER: A Model-Driven Method to Generate Diverse Highway Interchanges for Autonomous Vehicle Testing
Jan 30, 2023



It has become a consensus that autonomous vehicles (AVs) will first be widely deployed on highways. However, the complexity of highway interchanges becomes the bottleneck for deploying AVs. An AV should be sufficiently tested under different highway interchanges, which is still challenging due to the lack of available datasets containing diverse highway interchanges. In this paper, we propose a model-driven method, FLYOVER, to generate a dataset consisting of diverse interchanges with measurable diversity coverage. First, FLYOVER proposes a labeled digraph to model the topology of an interchange. Second, FLYOVER takes real-world interchanges as input to guarantee topology practicality and extracts different topology equivalence classes by classifying the corresponding topology models. Third, for each topology class, FLYOVER identifies the corresponding geometrical features for the ramps and generates concrete interchanges using k-way combinatorial coverage and differential evolution. To illustrate the diversity and applicability of the generated interchange dataset, we test the built-in traffic flow control algorithm in SUMO and the fuel-optimization trajectory tracking algorithm deployed to Alibaba's autonomous trucks on the dataset. The results show that except for the geometrical difference, the interchanges are diverse in throughput and fuel consumption under the traffic flow control and trajectory tracking algorithms, respectively.
Efficiently Training On-Policy Actor-Critic Networks in Robotic Deep Reinforcement Learning with Demonstration-like Sampled Exploration
Sep 27, 2021

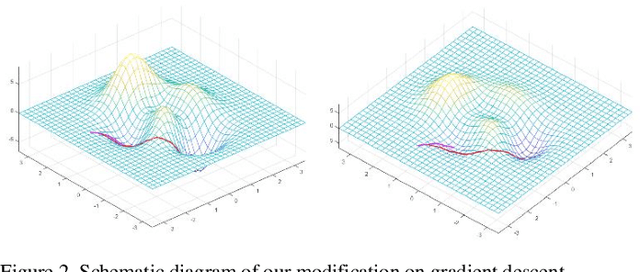
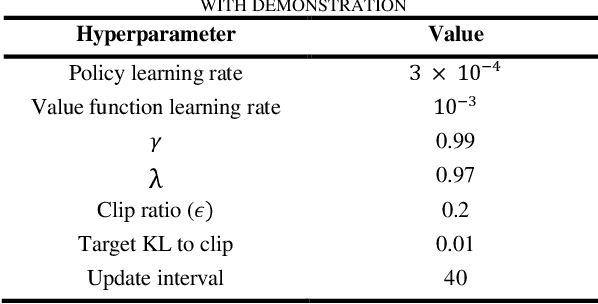
In complex environments with high dimension, training a reinforcement learning (RL) model from scratch often suffers from lengthy and tedious collection of agent-environment interactions. Instead, leveraging expert demonstration to guide RL agent can boost sample efficiency and improve final convergence. In order to better integrate expert prior with on-policy RL models, we propose a generic framework for Learning from Demonstration (LfD) based on actor-critic algorithms. Technically, we first employ K-Means clustering to evaluate the similarity of sampled exploration with demonstration data. Then we increase the likelihood of actions in similar frames by modifying the gradient update strategy to leverage demonstration. We conduct experiments on 4 standard benchmark environments in Mujoco and 2 self-designed robotic environments. Results show that, under certain condition, our algorithm can improve sample efficiency by 20% ~ 40%. By combining our framework with on-policy algorithms, RL models can accelerate convergence and obtain better final mean episode rewards especially in complex robotic context where interactions are expensive.
Efficient State Representation Learning for Dynamic Robotic Scenarios
Sep 17, 2021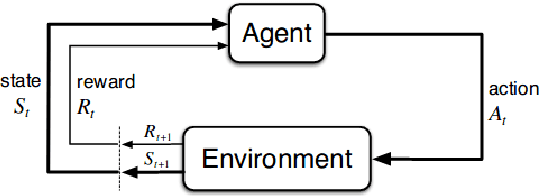
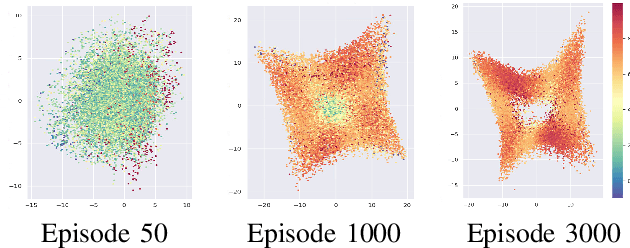
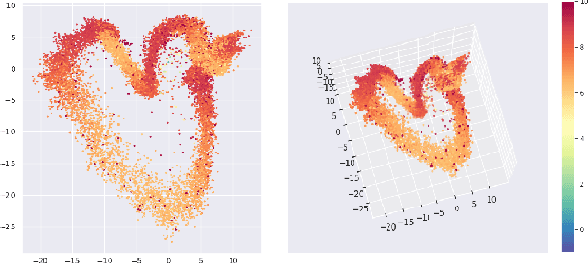
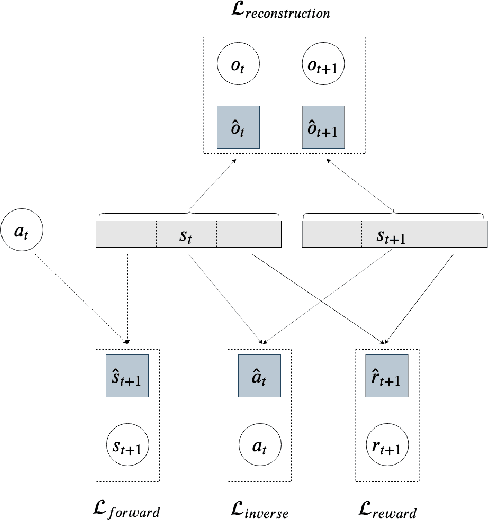
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
Exploration-efficient Deep Reinforcement Learning with Demonstration Guidance for Robot Control
Feb 27, 2020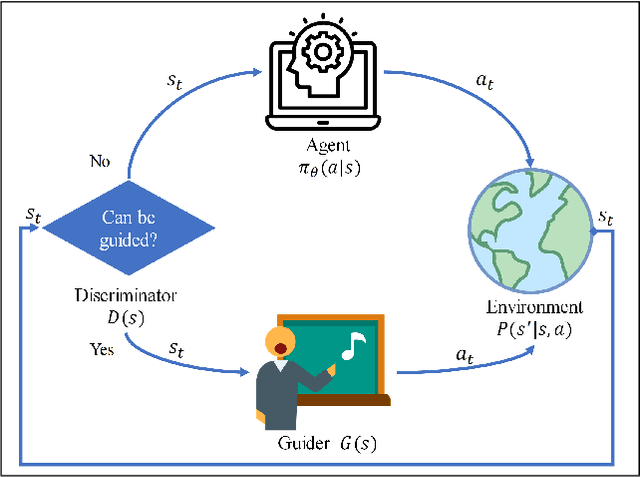

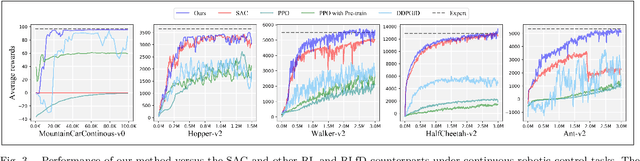
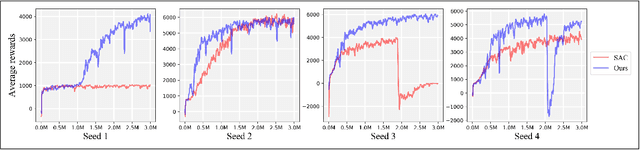
Although deep reinforcement learning (DRL) algorithms have made important achievements in many control tasks, they still suffer from the problems of sample inefficiency and unstable training process, which are usually caused by sparse rewards. Recently, some reinforcement learning from demonstration (RLfD) methods have shown to be promising in overcoming these problems. However, they usually require considerable demonstrations. In order to tackle these challenges, on the basis of the SAC algorithm we propose a sample efficient DRL-EG (DRL with efficient guidance) algorithm, in which a discriminator D(s) and a guider G(s) are modeled by a small number of expert demonstrations. The discriminator will determine the appropriate guidance states and the guider will guide agents to better exploration in the training phase. Empirical evaluation results from several continuous control tasks verify the effectiveness and performance improvements of our method over other RL and RLfD counterparts. Experiments results also show that DRL-EG can help the agent to escape from a local optimum.