 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHard instance learning for quantum adiabatic prime factorization
Oct 10, 2021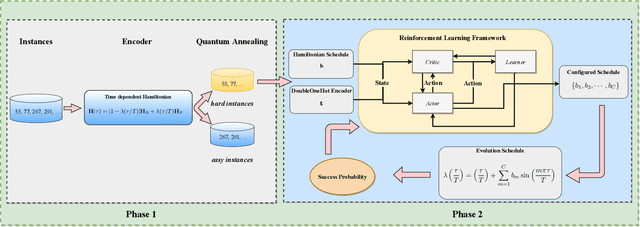
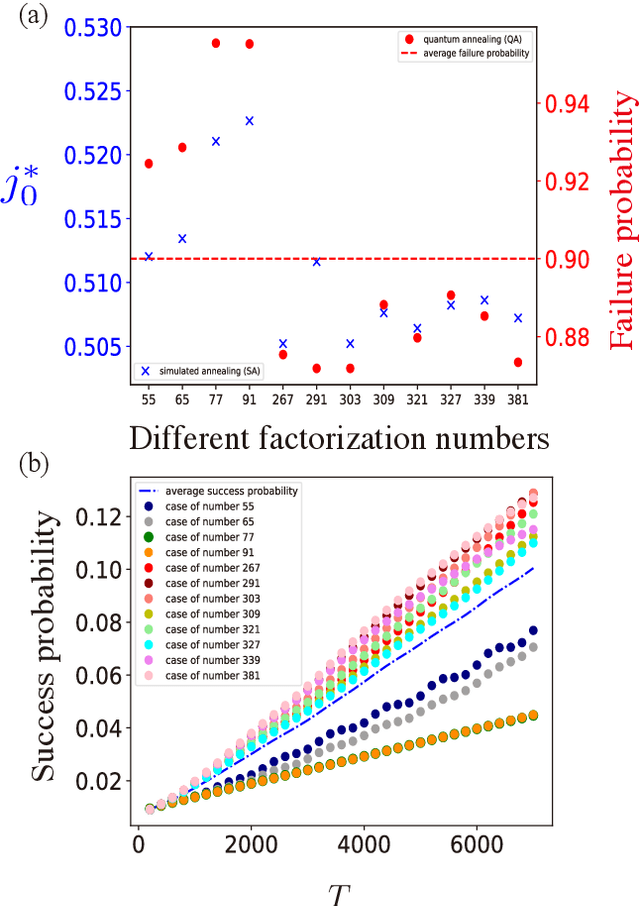
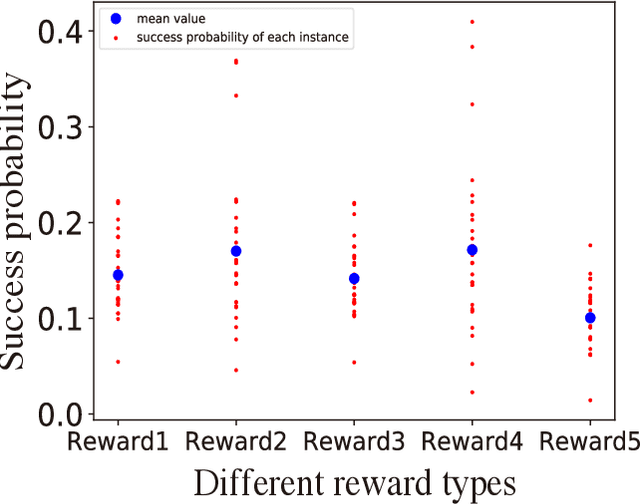
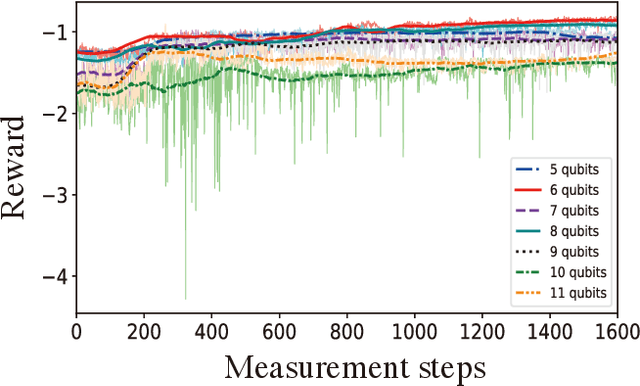
Prime factorization is a difficult problem with classical computing, whose exponential hardness is the foundation of Rivest-Shamir-Adleman (RSA) cryptography. With programmable quantum devices, adiabatic quantum computing has been proposed as a plausible approach to solve prime factorization, having promising advantage over classical computing. Here, we find there are certain hard instances that are consistently intractable for both classical simulated annealing and un-configured adiabatic quantum computing (AQC). Aiming at an automated architecture for optimal configuration of quantum adiabatic factorization, we apply a deep reinforcement learning (RL) method to configure the AQC algorithm. By setting the success probability of the worst-case problem instances as the reward to RL, we show the AQC performance on the hard instances is dramatically improved by RL configuration. The success probability also becomes more evenly distributed over different problem instances, meaning the configured AQC is more stable as compared to the un-configured case. Through a technique of transfer learning, we find prominent evidence that the framework of AQC configuration is scalable -- the configured AQC as trained on five qubits remains working efficiently on nine qubits with a minimal amount of additional training cost.
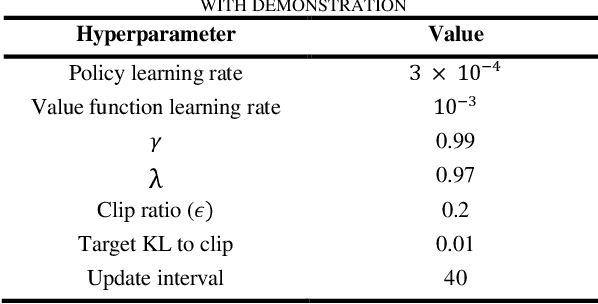
Efficiently Training On-Policy Actor-Critic Networks in Robotic Deep Reinforcement Learning with Demonstration-like Sampled Exploration
Sep 27, 2021

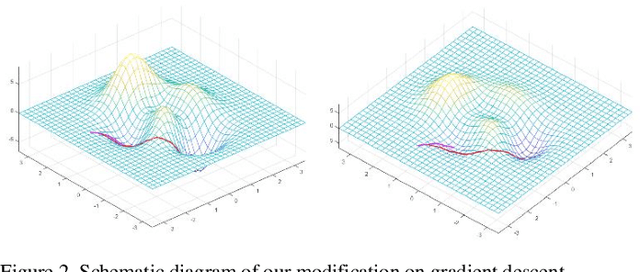
In complex environments with high dimension, training a reinforcement learning (RL) model from scratch often suffers from lengthy and tedious collection of agent-environment interactions. Instead, leveraging expert demonstration to guide RL agent can boost sample efficiency and improve final convergence. In order to better integrate expert prior with on-policy RL models, we propose a generic framework for Learning from Demonstration (LfD) based on actor-critic algorithms. Technically, we first employ K-Means clustering to evaluate the similarity of sampled exploration with demonstration data. Then we increase the likelihood of actions in similar frames by modifying the gradient update strategy to leverage demonstration. We conduct experiments on 4 standard benchmark environments in Mujoco and 2 self-designed robotic environments. Results show that, under certain condition, our algorithm can improve sample efficiency by 20% ~ 40%. By combining our framework with on-policy algorithms, RL models can accelerate convergence and obtain better final mean episode rewards especially in complex robotic context where interactions are expensive.
Exploration-efficient Deep Reinforcement Learning with Demonstration Guidance for Robot Control
Feb 27, 2020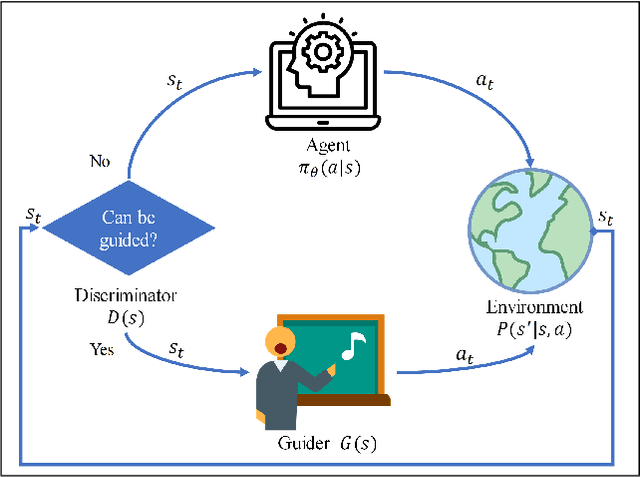

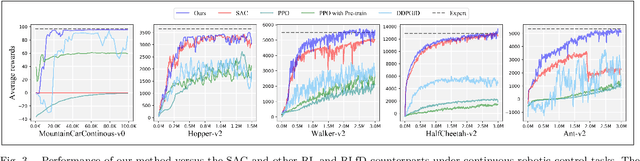
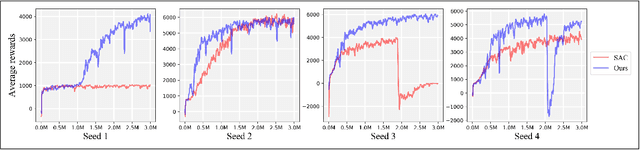
Although deep reinforcement learning (DRL) algorithms have made important achievements in many control tasks, they still suffer from the problems of sample inefficiency and unstable training process, which are usually caused by sparse rewards. Recently, some reinforcement learning from demonstration (RLfD) methods have shown to be promising in overcoming these problems. However, they usually require considerable demonstrations. In order to tackle these challenges, on the basis of the SAC algorithm we propose a sample efficient DRL-EG (DRL with efficient guidance) algorithm, in which a discriminator D(s) and a guider G(s) are modeled by a small number of expert demonstrations. The discriminator will determine the appropriate guidance states and the guider will guide agents to better exploration in the training phase. Empirical evaluation results from several continuous control tasks verify the effectiveness and performance improvements of our method over other RL and RLfD counterparts. Experiments results also show that DRL-EG can help the agent to escape from a local optimum.