 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNull-Space Constrained Low-Rank Adaptation for Response-Specified Large Language Model Unlearning
Jun 09, 2026Large language model unlearning aims to suppress designated undesirable knowledge while preserving benign capabilities. Many unlearning objectives focus on suppressing undesired answers, while recent target-guided variants specify replacement behavior but still leave update locality largely unconstrained. This paper introduces \emph{Null-Space Constrained Response-Specified Unlearning} (NSRU), a projection-constrained low-rank framework for controlled LLM unlearning. NSRU uses an explicitly structured safe target response to specify the desired behavior for each forget query, while suppressing the original undesired content. To localize adaptation, NSRU estimates per-module retain subspaces from benign hidden representations and uses an orthogonal-projected low-rank parameterization to confine LoRA updates to the null space of the retain subspace. The resulting objective jointly optimizes safe-target learning, undesired-response suppression, and retention preservation under this constrained parameterization. We provide a local first-order analysis showing that the projected update reduces retain-side perturbations while preserving editable directions for shaping forget-query behavior. Experiments on TOFU show that NSRU effectively suppresses extractable forget-set knowledge while improving retain QA performance, model utility, and safe-target alignment over representative baselines. On WMDP, NSRU keeps hazardous-domain accuracy near the random-choice region while preserving broad and domain-adjacent MMLU utility. Ablation studies support the complementary roles of safe-target supervision, undesired-response suppression, retention loss, and null-space projected updates, while sensitivity and robustness analyses indicate stable behavior across the tested hyperparameter and prompt variations.
Inference Cost Attacks for Retrieval-Augmented Large Language Models
May 31, 2026Retrieval-Augmented Generation (RAG)-enhanced LLM systems, while powerful, introduce substantial inference costs due to the inclusion of an extra multi-stage pipeline that dynamically retrieves and synthesizes information from external knowledge sources. This high operational cost exposes a critical vulnerability to Inference Cost Attacks (ICAs). However, existing ICAs often rely on the impractical assumption of direct prompt manipulation. We argue that a more feasible and potent threat to RAG-enhanced LLM systems arises from poisoning external knowledge bases (e.g., web knowledge from the Internet). In this work, we introduce the Retrieval-Augmented Inference Cost Attack (RA-ICA), a novel attacking paradigm that targets the computational cost of RAG-enhanced LLM systems by injecting malicious documents into external knowledge corpus. To operationalize this attack, we propose Computational Resource Exhaustion via External Poisoning (CREEP), a novel framework that leverages LLM agents to automatically craft malicious documents that are both semantically relevant for retrieval and potent for inducing an abnormal increase in token consumption during the inference phase. To enhance the attack's effectiveness, we introduce Memory-Augmented Group Relative Policy Optimization (MA-GRPO), a novel reinforcement learning algorithm that fine-tunes the agents by learning from a dynamic memory of historical best adversarial documents. Extensive experiments across three real-world datasets demonstrate that RA-ICA increases token consumption by up to 13.12 times with an over 90% success rate, without degrading the integrity of the generated answer.
* Accepted at The ACM Web Conference 2026 (WWW '26)
Physiology and Anatomy Aware Inverse Inference of Myocardial Infarction for Cardiac Digital Twin
May 21, 2026Accurate localization of myocardial infarction is essential for risk stratification. While LGE-MRI remains the gold standard, it is resource-intensive. Integrating cine MRI with ECG enables a more detailed representation of infarct properties. Existing inverse MI inference methods overlook realistic scar morphology and cardiac repolarization, reducing sensitivity to subtle ECG variations and interpretability of infarct-induced electrophysiological changes. In this paper, we propose a novel framework for noninvasive MI localization using cardiac digital twins. To bridge the domain gap between simulation and reality, we introduce an anatomy-aware stochastic infarct synthesis strategy to synthesize realistic, irregular scars with border zones, mimicking ischemic transmural progression. We then construct a virtual cohort to simulate QRS-T waveforms, capturing both depolarization and repolarization dynamics. Furthermore, we design a Physiology and Anatomy Aware Network (PAA-Net) that jointly encodes 3D myocardial geometry and multi-lead ECGs to infer infarct areas with varying localizations, sizes, spatial extents, and transmuralities. Experimental results demonstrate that our framework significantly outperforms existing methods in inverse inference, achieving Dice scores of 0.7391 and 0.5503 for scar and border zone segmentation, respectively, while further enhancing the interpretability of the ECG-infarct relationship. Our code will be released upon acceptance.
Text-to-CAD Retrieval: a Strong Baseline
May 07, 2026Text-based retrieval of Computer-Aided Design (CAD) models is a critical yet underexplored task for the reuse of legacy industrial designs. Existing CAD repositories are typically searched using filenames or directories, which limits the efficiency, scalability, and accuracy of design retrieval. In this paper, we formally introduce text-to-CAD retrieval as a new cross-modal retrieval task, aiming to retrieve semantically relevant CAD models from large-scale databases given natural language queries. Leveraging paired text-CAD annotations from the Text2CAD dataset, we establish a practical benchmark for this task. To achieve text-based retrieval, we propose a unified framework that learns multi-modal CAD embeddings from both procedural sequences and geometric point clouds. Specifically, a sequence encoder captures the construction logic of CAD models, while a point encoder extracts explicit geometric features. A text encoder is used to learn semantic representations of textual queries. During training, we introduce a novel feature decoder that reconstructs masked sequence features via cross-attention with text and point features, encouraging implicit multi-modal alignment. At inference time, we remove this auxiliary decoder to enable efficient retrieval using concatenated sequence-point features. Our framework serves as a strong baseline for text-to-CAD retrieval and lays the foundation for downstream CAD generation paradigms, such as retrieval-augmented generation. The source code will be released.
Generative Data-engine Foundation Model for Universal Few-shot 2D Vascular Image Segmentation
Apr 12, 2026The segmentation of 2D vascular structures via deep learning holds significant clinical value but is hindered by the scarcity of annotated data, severely limiting its widespread application. Developing a universal few-shot vascular segmentation model is highly desirable, yet remains challenging due to the need for extensive training and the inherent complexities of vascular imaging. In this work, we propose UniVG (Generative Data-engine Foundation Model for Universal Few-shot 2D Vascular Image Segmentation), a novel approach that learns the compositionality of vascular images and constructing a generative foundation model for robust vascular segmentation. UniVG enables the synthesis and learning of diverse and realistic vascular images through two key innovations: 1) Compositional learning for flexible and diverse vascular synthesis: It decomposes and recombines vascular structures with varying morphological features and diverse foreground-background configurations to generate richly diverse synthetic image-label pairs. 2) Few-shot generative adaptation for transferable segmentation: It fine-tunes pre-trained models with minimal annotated data to bridge the gap between synthetic and real vascular domains, synthesizing authentic and diverse vessel images for downstream few-shot vascular segmentation learning. To support our approach, we develop UniVG-58K, a large dataset comprising 58,689 vascular images across five imaging modalities, facilitating robust large-scale generative pre-training. Extensive experiments on 11 vessel segmentation tasks cross 5 modalties (only with 5 labeled images on each task) demonstrate that UniVG achieves performance comparable to fully supervised models, significantly reducing data collection and annotation costs. All code and datasets will be made publicly available at https://github.com/XinAloha/UniVG.
Multi-Condition Digital Twin Calibration for Axial Piston Pumps : Compound Fault Simulation
Feb 27, 2026Axial piston pumps are indispensable power sources in high-stakes fluid power systems, including aerospace, marine, and heavy machinery applications. Their operational reliability is frequently compromised by compound faults that simultaneously affect multiple friction pairs. Conventional data-driven diagnosis methods suffer from severe data scarcity for compound faults and poor generalization across varying operating conditions. This paper proposes a novel multi-condition physics-data coupled digital twin calibration framework that explicitly resolves the fundamental uncertainty of pump outlet flow ripple. The framework comprises three synergistic stages: in-situ virtual high-frequency flow sensing on a dedicated rigid metallic segment, surrogate model-assisted calibration of the 3D CFD source model using physically estimated ripple amplitudes, and multi-objective inverse transient analysis for viscoelastic unsteady-friction pipeline parameter identification. Comprehensive experiments on a test rig demonstrate that the calibrated digital twin accurately reproduces both single-fault and two representative compound-fault. These results establish a high-fidelity synthetic fault-generation capability that directly enables robust zero-shot fault diagnosis under previously unseen operating regimes and fault combinations, thereby advancing predictive maintenance in complex hydraulic systems.
Reason-IAD: Knowledge-Guided Dynamic Latent Reasoning for Explainable Industrial Anomaly Detection
Feb 10, 2026Industrial anomaly detection demands precise reasoning over fine-grained defect patterns. However, existing multimodal large language models (MLLMs), pretrained on general-domain data, often struggle to capture category-specific anomalies, thereby limiting both detection accuracy and interpretability. To address these limitations, we propose Reason-IAD, a knowledge-guided dynamic latent reasoning framework for explainable industrial anomaly detection. Reason-IAD comprises two core components. First, a retrieval-augmented knowledge module incorporates category-specific textual descriptions into the model input, enabling context-aware reasoning over domain-specific defects. Second, an entropy-driven latent reasoning mechanism conducts iterative exploration within a compact latent space using optimizable latent think tokens, guided by an entropy-based reward that encourages confident and stable predictions. Furthermore, a dynamic visual injection strategy selectively incorporates the most informative image patches into the latent sequence, directing the reasoning process toward regions critical for anomaly detection. Extensive experimental results demonstrate that Reason-IAD consistently outperforms state-of-the-art methods. The code will be publicly available at https://github.com/chenpeng052/Reason-IAD.
Multi-modal cross-domain mixed fusion model with dual disentanglement for fault diagnosis under unseen working conditions
Dec 31, 2025Intelligent fault diagnosis has become an indispensable technique for ensuring machinery reliability. However, existing methods suffer significant performance decline in real-world scenarios where models are tested under unseen working conditions, while domain adaptation approaches are limited to their reliance on target domain samples. Moreover, most existing studies rely on single-modal sensing signals, overlooking the complementary nature of multi-modal information for improving model generalization. To address these limitations, this paper proposes a multi-modal cross-domain mixed fusion model with dual disentanglement for fault diagnosis. A dual disentanglement framework is developed to decouple modality-invariant and modality-specific features, as well as domain-invariant and domain-specific representations, enabling both comprehensive multi-modal representation learning and robust domain generalization. A cross-domain mixed fusion strategy is designed to randomly mix modality information across domains for modality and domain diversity augmentation. Furthermore, a triple-modal fusion mechanism is introduced to adaptively integrate multi-modal heterogeneous information. Extensive experiments are conducted on induction motor fault diagnosis under both unseen constant and time-varying working conditions. The results demonstrate that the proposed method consistently outperforms advanced methods and comprehensive ablation studies further verify the effectiveness of each proposed component and multi-modal fusion. The code is available at: https://github.com/xiapc1996/MMDG.
Digital Twin-Driven Zero-Shot Fault Diagnosis of Axial Piston Pumps Using Fluid-Borne Noise Signals
Dec 22, 2025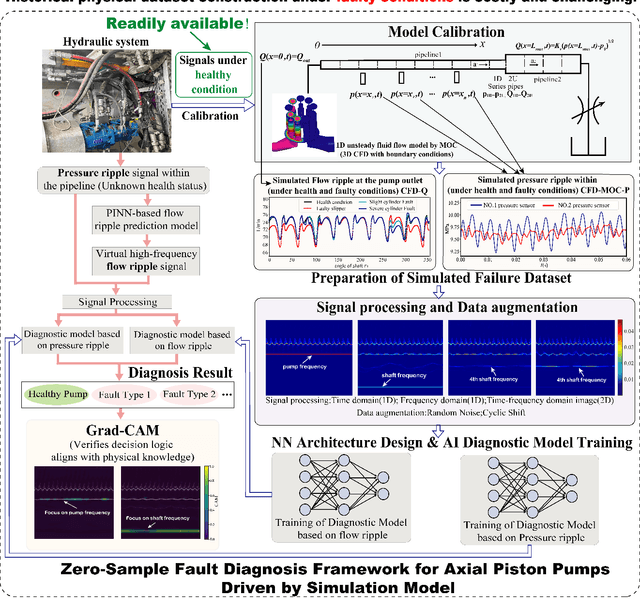



Axial piston pumps are crucial components in fluid power systems, where reliable fault diagnosis is essential for ensuring operational safety and efficiency. Traditional data-driven methods require extensive labeled fault data, which is often impractical to obtain, while model-based approaches suffer from parameter uncertainties. This paper proposes a digital twin (DT)-driven zero-shot fault diagnosis framework utilizing fluid-borne noise (FBN) signals. The framework calibrates a high-fidelity DT model using only healthy-state data, generates synthetic fault signals for training deep learning classifiers, and employs a physics-informed neural network (PINN) as a virtual sensor for flow ripple estimation. Gradient-weighted class activation mapping (Grad-CAM) is integrated to visualize the decision-making process of neural networks, revealing that large kernels matching the subsequence length in time-domain inputs and small kernels in time-frequency domain inputs enable higher diagnostic accuracy by focusing on physically meaningful features. Experimental validations demonstrate that training on signals from the calibrated DT model yields diagnostic accuracies exceeding 95\% on real-world benchmarks, while uncalibrated models result in significantly lower performance, highlighting the framework's effectiveness in data-scarce scenarios.
Enhancing Multimodal Protein Function Prediction Through Dual-Branch Dynamic Selection with Reconstructive Pre-Training
Nov 06, 2025Multimodal protein features play a crucial role in protein function prediction. However, these features encompass a wide range of information, ranging from structural data and sequence features to protein attributes and interaction networks, making it challenging to decipher their complex interconnections. In this work, we propose a multimodal protein function prediction method (DSRPGO) by utilizing dynamic selection and reconstructive pre-training mechanisms. To acquire complex protein information, we introduce reconstructive pre-training to mine more fine-grained information with low semantic levels. Moreover, we put forward the Bidirectional Interaction Module (BInM) to facilitate interactive learning among multimodal features. Additionally, to address the difficulty of hierarchical multi-label classification in this task, a Dynamic Selection Module (DSM) is designed to select the feature representation that is most conducive to current protein function prediction. Our proposed DSRPGO model improves significantly in BPO, MFO, and CCO on human datasets, thereby outperforming other benchmark models.