 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Adaptive Chance-Constrained Safeguards for Reinforcement Learning
Paper and Code
Oct 05, 2023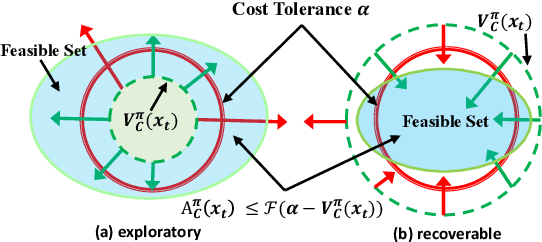
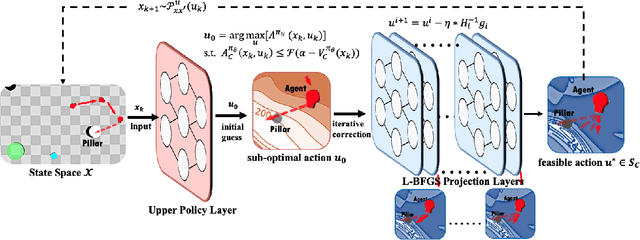


Safety assurance of Reinforcement Learning (RL) is critical for exploration in real-world scenarios. In handling the Constrained Markov Decision Process, current approaches experience intrinsic difficulties in trading-off between optimality and feasibility. Direct optimization methods cannot strictly guarantee state-wise in-training safety while projection-based methods are usually inefficient and correct actions through lengthy iterations. To address these two challenges, this paper proposes an adaptive surrogate chance constraint for the safety cost, and a hierarchical architecture that corrects actions produced by the upper policy layer via a fast Quasi-Newton method. Theoretical analysis indicates that the relaxed probabilistic constraint can sufficiently guarantee forward invariance to the safe set. We validate the proposed method on 4 simulated and real-world safety-critical robotic tasks. Results indicate that the proposed method can efficiently enforce safety (nearly zero-violation), while preserving optimality (+23.8%), robustness and generalizability to stochastic real-world settings.