 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Sales Lead Scoring with LLM-based Hierarchical Preference Ranking
Jun 03, 2026Sales lead conversion in high-stakes domains (e.g., automotive, real estate) differs fundamentally from e-commerce recommendation due to prolonged decision cycles and multi-stage funnels. Traditional lead scoring methods rule-based scorecards, machine learning, or pointwise CTR models face severe challenges: sparse supervision, a semantic gap in unstructured CRM logs, and inability to capture relative lead priority. While Large Language Models(LLMs) offer superior semantic understanding of customer interactions, general-purpose LLMs are ill-suited for lead ranking: they generate text rather than comparable scores, and lack alignment with the hierarchical priorities of sales funnels. We introduce an LLM-based discriminative framework for sales lead scoring, which supports joint modeling of structured CRM features and unstructured customer interactions. On top of this framework, we propose HPRO (Hierarchical Preference Ranking Optimization), which augments sales lead scoring with a hierarchical preference ranking objective. HPRO employs a margin-aware Bradley-Terry formulation to transform sparse binary labels into dense, funnel-aware preference pairs, enabling lead scoring to leverage both pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand demonstrate state-of-the-art classification (AUC 0.8161) and ranking performance (+39.7% precision among top-ranked leads). A 132-day online A/B test validates 9.5% sales volume uplift, confirming real-world commercial impact.
An interpretable and trustworthy AI framework for large-scale longitudinal structure-pain association studies using data from the Osteoarthritis Initiative (OAI)
Jun 03, 2026Purpose: To develop an interpretable and trustworthy AI framework that combines deep learning based MRI Osteoarthritis Knee Score (MOAKS) prediction with interpretable statistical modeling to study structure-pain relationships at scale using data from the Osteoarthritis Initiative (OAI). Materials and Methods: We first developed a deep learning framework to predict MOAKS features directly from knee MRIs and incorporated conformal prediction to provide prediction uncertainty quantification. This uncertainty-aware strategy enables explicit filtering of model outputs, retaining only high-confidence MOAKS predictions at the knee level. Second, we applied a longitudinal latent class mixed model (LCMM) to examine associations between key structural abnormalities and four complementary knee pain measurements. Results: Among the three MRI-defined abnormalities (i.e., bone marrow lesions (BML), cartilage loss (CART), and meniscal extrusion (ME)), our framework substantially improved the Matthews correlation coefficient (MCC) and some other metrics. For example, MCC increased from 0.69 to 0.91 for BML, from 0.45 to 0.80 for CART, and from 0.59 to 0.89 for ME. Using these high-confidence predictions, we expanded the sample size to 2,175 knees for the LCMM analysis. Two distinct pain trajectories were identified (rapid and stable pain progression). The estimated odds ratios (95% CI) for the rapid progression group were 1.62 (1.12-2.35) for BML, 1.83 (1.24-2.70) for CART loss, and 2.50 (1.75-3.57) for ME. Conclusion: These results highlight the importance of these structural abnormalities as risk factors for pain and functional progression in osteoarthritis.
SoDa2: Single-Stage Open-Set Domain Adaptation via Decoupled Alignment for Cross-Scene Hyperspectral Image Classification
May 05, 2026Cross-scene hyperspectral image (HSI) classification stands as a fundamental research topic in remote sensing, with extensive applications spanning various fields. Owing to the inclusion of unknown categories in the target domain and the existence of domain shift across different scenes, open-set domain adaptation techniques are commonly employed to address cross-scene HSI classification. However, existing open-set cross-scene HSI classification methods still face two critical challenges: (1) domain shift issues arising from the direct alignment of mixed spectral-spatial features; (2) high computational costs caused by two-stage training strategies. To address these issues, this paper proposes a single-stage open-set domain adaptation method with decoupled alignment (SoDa$^2$) for cross-scene HSI classification. A contribution-aware dual-modality feature extraction is customized to disentangle the characteristics from spectral sequence signals and spatial details, selectively and adaptively enhancing discriminative features. The decoupled alignment module minimizes the Maximum Mean Discrepancy to independently reduce the spectral discrepancy and the spatial discrepancy between the source and target domains, extracting more fine-grained domain-invariant features. A cost-effective single-stage dual-branch framework is designed to learn MMD-constrainted aligned features and constraint-free intrinsic features for adaptive distinction between known and unknown classes. This framework employs a Gaussian Mixture Model to model the squared cosine similarity distribution between the two feature types, enabling open-set recognition without prior knowledge of unknown classes. Extensive experiments on three groups of HSI datasets demonstrate that SoDa$^2$ outperforms state-of-the-art methods, achieving superior classification accuracy and model transferability for open-set cross-scene tasks.
Balancing Rewards in Text Summarization: Multi-Objective Reinforcement Learning via HyperVolume Optimization
Oct 22, 2025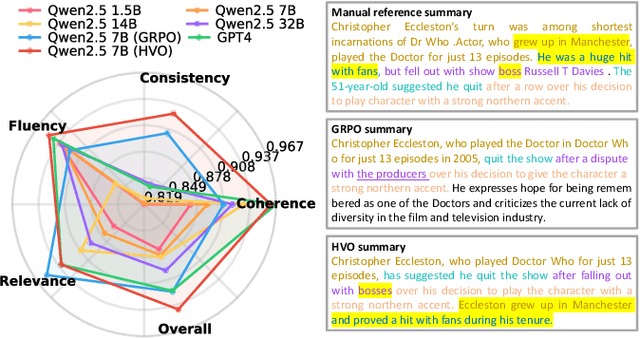
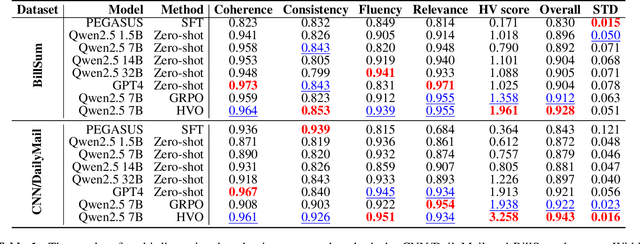
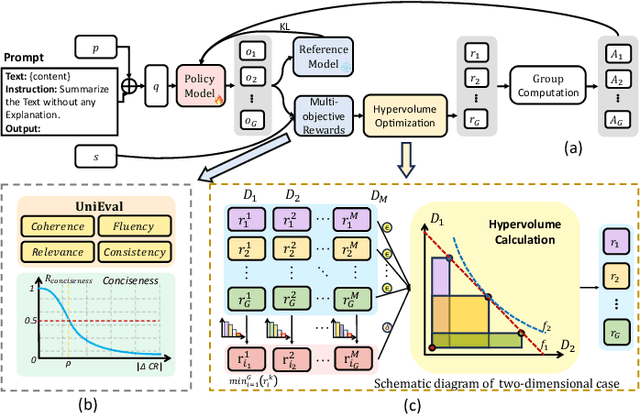

Text summarization is a crucial task that requires the simultaneous optimization of multiple objectives, including consistency, coherence, relevance, and fluency, which presents considerable challenges. Although large language models (LLMs) have demonstrated remarkable performance, enhanced by reinforcement learning (RL), few studies have focused on optimizing the multi-objective problem of summarization through RL based on LLMs. In this paper, we introduce hypervolume optimization (HVO), a novel optimization strategy that dynamically adjusts the scores between groups during the reward process in RL by using the hypervolume method. This method guides the model's optimization to progressively approximate the pareto front, thereby generating balanced summaries across multiple objectives. Experimental results on several representative summarization datasets demonstrate that our method outperforms group relative policy optimization (GRPO) in overall scores and shows more balanced performance across different dimensions. Moreover, a 7B foundation model enhanced by HVO performs comparably to GPT-4 in the summarization task, while maintaining a shorter generation length. Our code is publicly available at https://github.com/ai4business-LiAuto/HVO.git
MoFE-Time: Mixture of Frequency Domain Experts for Time-Series Forecasting Models
Jul 09, 2025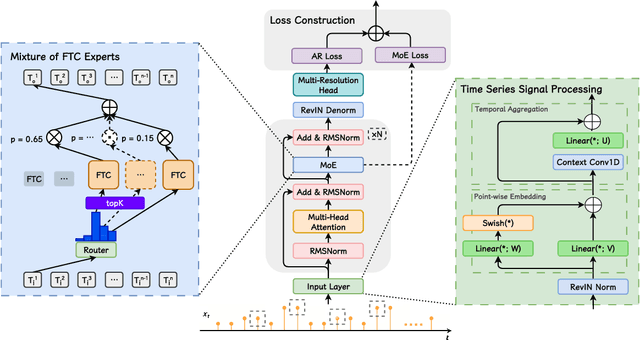



As a prominent data modality task, time series forecasting plays a pivotal role in diverse applications. With the remarkable advancements in Large Language Models (LLMs), the adoption of LLMs as the foundational architecture for time series modeling has gained significant attention. Although existing models achieve some success, they rarely both model time and frequency characteristics in a pretraining-finetuning paradigm leading to suboptimal performance in predictions of complex time series, which requires both modeling periodicity and prior pattern knowledge of signals. We propose MoFE-Time, an innovative time series forecasting model that integrates time and frequency domain features within a Mixture of Experts (MoE) network. Moreover, we use the pretraining-finetuning paradigm as our training framework to effectively transfer prior pattern knowledge across pretraining and finetuning datasets with different periodicity distributions. Our method introduces both frequency and time cells as experts after attention modules and leverages the MoE routing mechanism to construct multidimensional sparse representations of input signals. In experiments on six public benchmarks, MoFE-Time has achieved new state-of-the-art performance, reducing MSE and MAE by 6.95% and 6.02% compared to the representative methods Time-MoE. Beyond the existing evaluation benchmarks, we have developed a proprietary dataset, NEV-sales, derived from real-world business scenarios. Our method achieves outstanding results on this dataset, underscoring the effectiveness of the MoFE-Time model in practical commercial applications.
Does Feasibility Matter? Understanding the Impact of Feasibility on Synthetic Training Data
May 15, 2025With the development of photorealistic diffusion models, models trained in part or fully on synthetic data achieve progressively better results. However, diffusion models still routinely generate images that would not exist in reality, such as a dog floating above the ground or with unrealistic texture artifacts. We define the concept of feasibility as whether attributes in a synthetic image could realistically exist in the real-world domain; synthetic images containing attributes that violate this criterion are considered infeasible. Intuitively, infeasible images are typically considered out-of-distribution; thus, training on such images is expected to hinder a model's ability to generalize to real-world data, and they should therefore be excluded from the training set whenever possible. However, does feasibility really matter? In this paper, we investigate whether enforcing feasibility is necessary when generating synthetic training data for CLIP-based classifiers, focusing on three target attributes: background, color, and texture. We introduce VariReal, a pipeline that minimally edits a given source image to include feasible or infeasible attributes given by the textual prompt generated by a large language model. Our experiments show that feasibility minimally affects LoRA-fine-tuned CLIP performance, with mostly less than 0.3% difference in top-1 accuracy across three fine-grained datasets. Also, the attribute matters on whether the feasible/infeasible images adversarially influence the classification performance. Finally, mixing feasible and infeasible images in training datasets does not significantly impact performance compared to using purely feasible or infeasible datasets.
JPEG Inspired Deep Learning
Oct 09, 2024



Although it is traditionally believed that lossy image compression, such as JPEG compression, has a negative impact on the performance of deep neural networks (DNNs), it is shown by recent works that well-crafted JPEG compression can actually improve the performance of deep learning (DL). Inspired by this, we propose JPEG-DL, a novel DL framework that prepends any underlying DNN architecture with a trainable JPEG compression layer. To make the quantization operation in JPEG compression trainable, a new differentiable soft quantizer is employed at the JPEG layer, and then the quantization operation and underlying DNN are jointly trained. Extensive experiments show that in comparison with the standard DL, JPEG-DL delivers significant accuracy improvements across various datasets and model architectures while enhancing robustness against adversarial attacks. Particularly, on some fine-grained image classification datasets, JPEG-DL can increase prediction accuracy by as much as 20.9%. Our code is available on https://github.com/JpegInspiredDl/JPEG-Inspired-DL.git.
ClearDepth: Enhanced Stereo Perception of Transparent Objects for Robotic Manipulation
Sep 13, 2024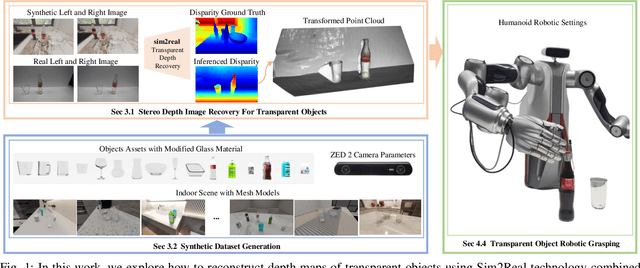
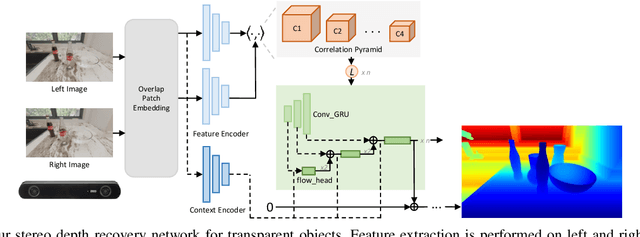
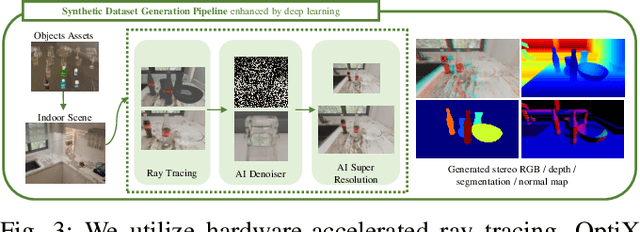

Transparent object depth perception poses a challenge in everyday life and logistics, primarily due to the inability of standard 3D sensors to accurately capture depth on transparent or reflective surfaces. This limitation significantly affects depth map and point cloud-reliant applications, especially in robotic manipulation. We developed a vision transformer-based algorithm for stereo depth recovery of transparent objects. This approach is complemented by an innovative feature post-fusion module, which enhances the accuracy of depth recovery by structural features in images. To address the high costs associated with dataset collection for stereo camera-based perception of transparent objects, our method incorporates a parameter-aligned, domain-adaptive, and physically realistic Sim2Real simulation for efficient data generation, accelerated by AI algorithm. Our experimental results demonstrate the model's exceptional Sim2Real generalizability in real-world scenarios, enabling precise depth mapping of transparent objects to assist in robotic manipulation. Project details are available at https://sites.google.com/view/cleardepth/ .
A Self-supervised Contrastive Learning Method for Grasp Outcomes Prediction
Jun 26, 2023

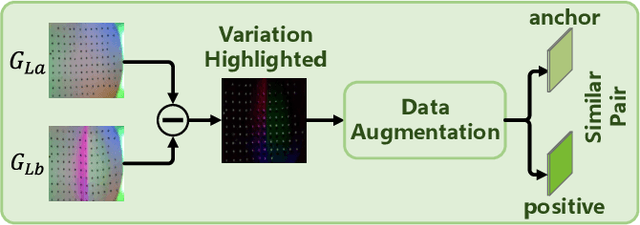
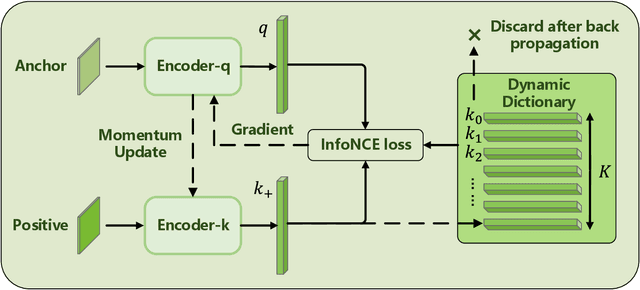
In this paper, we investigate the effectiveness of contrastive learning methods for predicting grasp outcomes in an unsupervised manner. By utilizing a publicly available dataset, we demonstrate that contrastive learning methods perform well on the task of grasp outcomes prediction. Specifically, the dynamic-dictionary-based method with the momentum updating technique achieves a satisfactory accuracy of 81.83% using data from one single tactile sensor, outperforming other unsupervised methods. Our results reveal the potential of contrastive learning methods for applications in the field of robot grasping and highlight the importance of accurate grasp prediction for achieving stable grasps.
Using contrastive learning to improve the performance of steganalysis schemes
Mar 01, 2021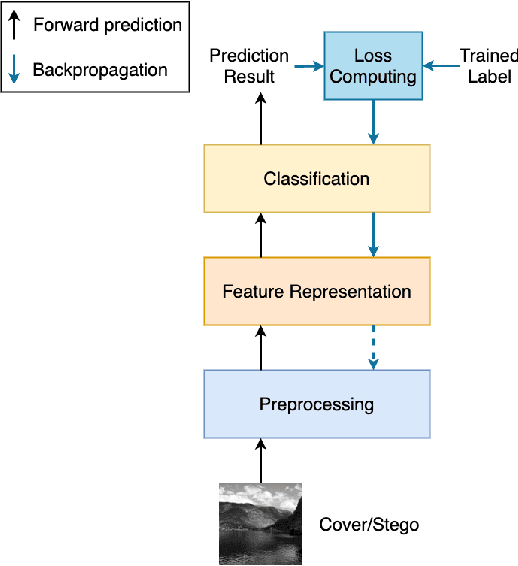

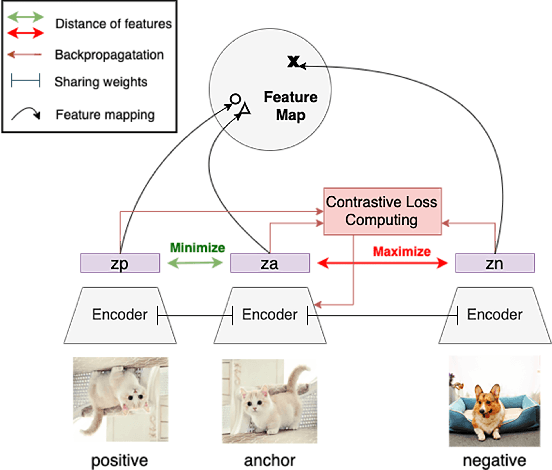

To improve the detection accuracy and generalization of steganalysis, this paper proposes the Steganalysis Contrastive Framework (SCF) based on contrastive learning. The SCF improves the feature representation of steganalysis by maximizing the distance between features of samples of different categories and minimizing the distance between features of samples of the same category. To decrease the computing complexity of the contrastive loss in supervised learning, we design a novel Steganalysis Contrastive Loss (StegCL) based on the equivalence and transitivity of similarity. The StegCL eliminates the redundant computing in the existing contrastive loss. The experimental results show that the SCF improves the generalization and detection accuracy of existing steganalysis DNNs, and the maximum promotion is 2% and 3% respectively. Without decreasing the detection accuracy, the training time of using the StegCL is 10% of that of using the contrastive loss in supervised learning.