 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Diffusion Models for Inverse Problems with Covariance-Aware Posterior Sampling
Dec 28, 2024



Inverse problems exist in many disciplines of science and engineering. In computer vision, for example, tasks such as inpainting, deblurring, and super resolution can be effectively modeled as inverse problems. Recently, denoising diffusion probabilistic models (DDPMs) are shown to provide a promising solution to noisy linear inverse problems without the need for additional task specific training. Specifically, with the prior provided by DDPMs, one can sample from the posterior by approximating the likelihood. In the literature, approximations of the likelihood are often based on the mean of conditional densities of the reverse process, which can be obtained using Tweedie formula. To obtain a better approximation to the likelihood, in this paper we first derive a closed form formula for the covariance of the reverse process. Then, we propose a method based on finite difference method to approximate this covariance such that it can be readily obtained from the existing pretrained DDPMs, thereby not increasing the complexity compared to existing approaches. Finally, based on the mean and approximated covariance of the reverse process, we present a new approximation to the likelihood. We refer to this method as covariance-aware diffusion posterior sampling (CA-DPS). Experimental results show that CA-DPS significantly improves reconstruction performance without requiring hyperparameter tuning. The code for the paper is put in the supplementary materials.
Going Beyond Feature Similarity: Effective Dataset distillation based on Class-aware Conditional Mutual Information
Dec 13, 2024



Dataset distillation (DD) aims to minimize the time and memory consumption needed for training deep neural networks on large datasets, by creating a smaller synthetic dataset that has similar performance to that of the full real dataset. However, current dataset distillation methods often result in synthetic datasets that are excessively difficult for networks to learn from, due to the compression of a substantial amount of information from the original data through metrics measuring feature similarity, e,g., distribution matching (DM). In this work, we introduce conditional mutual information (CMI) to assess the class-aware complexity of a dataset and propose a novel method by minimizing CMI. Specifically, we minimize the distillation loss while constraining the class-aware complexity of the synthetic dataset by minimizing its empirical CMI from the feature space of pre-trained networks, simultaneously. Conducting on a thorough set of experiments, we show that our method can serve as a general regularization method to existing DD methods and improve the performance and training efficiency.
JPEG Inspired Deep Learning
Oct 09, 2024



Although it is traditionally believed that lossy image compression, such as JPEG compression, has a negative impact on the performance of deep neural networks (DNNs), it is shown by recent works that well-crafted JPEG compression can actually improve the performance of deep learning (DL). Inspired by this, we propose JPEG-DL, a novel DL framework that prepends any underlying DNN architecture with a trainable JPEG compression layer. To make the quantization operation in JPEG compression trainable, a new differentiable soft quantizer is employed at the JPEG layer, and then the quantization operation and underlying DNN are jointly trained. Extensive experiments show that in comparison with the standard DL, JPEG-DL delivers significant accuracy improvements across various datasets and model architectures while enhancing robustness against adversarial attacks. Particularly, on some fine-grained image classification datasets, JPEG-DL can increase prediction accuracy by as much as 20.9%. Our code is available on https://github.com/JpegInspiredDl/JPEG-Inspired-DL.git.
Knowledge Distillation Based on Transformed Teacher Matching
Feb 17, 2024



As a technique to bridge logit matching and probability distribution matching, temperature scaling plays a pivotal role in knowledge distillation (KD). Conventionally, temperature scaling is applied to both teacher's logits and student's logits in KD. Motivated by some recent works, in this paper, we drop instead temperature scaling on the student side, and systematically study the resulting variant of KD, dubbed transformed teacher matching (TTM). By reinterpreting temperature scaling as a power transform of probability distribution, we show that in comparison with the original KD, TTM has an inherent R\'enyi entropy term in its objective function, which serves as an extra regularization term. Extensive experiment results demonstrate that thanks to this inherent regularization, TTM leads to trained students with better generalization than the original KD. To further enhance student's capability to match teacher's power transformed probability distribution, we introduce a sample-adaptive weighting coefficient into TTM, yielding a novel distillation approach dubbed weighted TTM (WTTM). It is shown, by comprehensive experiments, that although WTTM is simple, it is effective, improves upon TTM, and achieves state-of-the-art accuracy performance. Our source code is available at https://github.com/zkxufo/TTM.
Bayes Conditional Distribution Estimation for Knowledge Distillation Based on Conditional Mutual Information
Jan 16, 2024It is believed that in knowledge distillation (KD), the role of the teacher is to provide an estimate for the unknown Bayes conditional probability distribution (BCPD) to be used in the student training process. Conventionally, this estimate is obtained by training the teacher using maximum log-likelihood (MLL) method. To improve this estimate for KD, in this paper we introduce the concept of conditional mutual information (CMI) into the estimation of BCPD and propose a novel estimator called the maximum CMI (MCMI) method. Specifically, in MCMI estimation, both the log-likelihood and CMI of the teacher are simultaneously maximized when the teacher is trained. Through Eigen-CAM, it is further shown that maximizing the teacher's CMI value allows the teacher to capture more contextual information in an image cluster. Via conducting a thorough set of experiments, we show that by employing a teacher trained via MCMI estimation rather than one trained via MLL estimation in various state-of-the-art KD frameworks, the student's classification accuracy consistently increases, with the gain of up to 3.32\%. This suggests that the teacher's BCPD estimate provided by MCMI method is more accurate than that provided by MLL method. In addition, we show that such improvements in the student's accuracy are more drastic in zero-shot and few-shot settings. Notably, the student's accuracy increases with the gain of up to 5.72\% when 5\% of the training samples are available to the student (few-shot), and increases from 0\% to as high as 84\% for an omitted class (zero-shot). The code is available at \url{https://github.com/iclr2024mcmi/ICLRMCMI}.
AdaFed: Fair Federated Learning via Adaptive Common Descent Direction
Jan 10, 2024Federated learning (FL) is a promising technology via which some edge devices/clients collaboratively train a machine learning model orchestrated by a server. Learning an unfair model is known as a critical problem in federated learning, where the trained model may unfairly advantage or disadvantage some of the devices. To tackle this problem, in this work, we propose AdaFed. The goal of AdaFed is to find an updating direction for the server along which (i) all the clients' loss functions are decreasing; and (ii) more importantly, the loss functions for the clients with larger values decrease with a higher rate. AdaFed adaptively tunes this common direction based on the values of local gradients and loss functions. We validate the effectiveness of AdaFed on a suite of federated datasets, and demonstrate that AdaFed outperforms state-of-the-art fair FL methods.
Conditional Mutual Information Constrained Deep Learning for Classification
Sep 17, 2023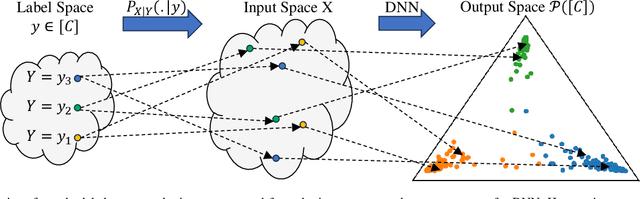
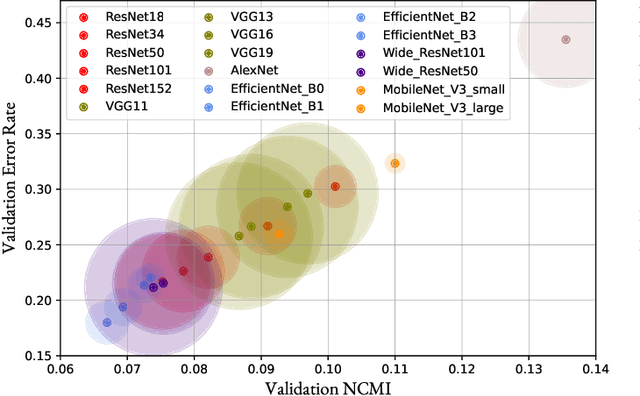
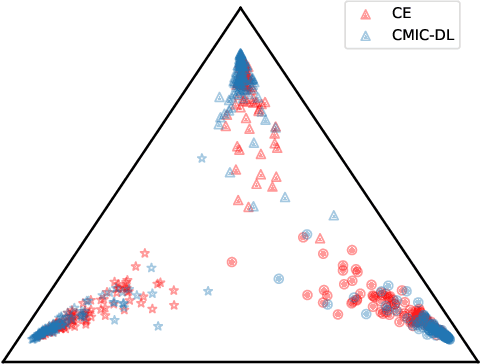
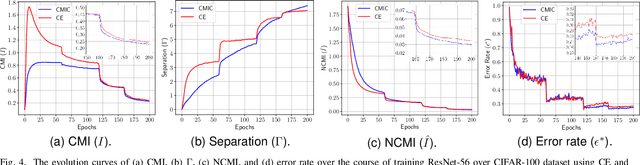
The concepts of conditional mutual information (CMI) and normalized conditional mutual information (NCMI) are introduced to measure the concentration and separation performance of a classification deep neural network (DNN) in the output probability distribution space of the DNN, where CMI and the ratio between CMI and NCMI represent the intra-class concentration and inter-class separation of the DNN, respectively. By using NCMI to evaluate popular DNNs pretrained over ImageNet in the literature, it is shown that their validation accuracies over ImageNet validation data set are more or less inversely proportional to their NCMI values. Based on this observation, the standard deep learning (DL) framework is further modified to minimize the standard cross entropy function subject to an NCMI constraint, yielding CMI constrained deep learning (CMIC-DL). A novel alternating learning algorithm is proposed to solve such a constrained optimization problem. Extensive experiment results show that DNNs trained within CMIC-DL outperform the state-of-the-art models trained within the standard DL and other loss functions in the literature in terms of both accuracy and robustness against adversarial attacks. In addition, visualizing the evolution of learning process through the lens of CMI and NCMI is also advocated.