 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifficulty-guided Sampling: Bridging the Target Gap between Dataset Distillation and Downstream Tasks
Jan 15, 2026In this paper, we propose difficulty-guided sampling (DGS) to bridge the target gap between the distillation objective and the downstream task, therefore improving the performance of dataset distillation. Deep neural networks achieve remarkable performance but have time and storage-consuming training processes. Dataset distillation is proposed to generate compact, high-quality distilled datasets, enabling effective model training while maintaining downstream performance. Existing approaches typically focus on features extracted from the original dataset, overlooking task-specific information, which leads to a target gap between the distillation objective and the downstream task. We propose leveraging characteristics that benefit the downstream training into data distillation to bridge this gap. Focusing on the downstream task of image classification, we introduce the concept of difficulty and propose DGS as a plug-in post-stage sampling module. Following the specific target difficulty distribution, the final distilled dataset is sampled from image pools generated by existing methods. We also propose difficulty-aware guidance (DAG) to explore the effect of difficulty in the generation process. Extensive experiments across multiple settings demonstrate the effectiveness of the proposed methods. It also highlights the broader potential of difficulty for diverse downstream tasks.
Normalized Conditional Mutual Information Surrogate Loss for Deep Neural Classifiers
Jan 05, 2026In this paper, we propose a novel information theoretic surrogate loss; normalized conditional mutual information (NCMI); as a drop in alternative to the de facto cross-entropy (CE) for training deep neural network (DNN) based classifiers. We first observe that the model's NCMI is inversely proportional to its accuracy. Building on this insight, we introduce an alternating algorithm to efficiently minimize the NCMI. Across image recognition and whole-slide imaging (WSI) subtyping benchmarks, NCMI-trained models surpass state of the art losses by substantial margins at a computational cost comparable to that of CE. Notably, on ImageNet, NCMI yields a 2.77% top-1 accuracy improvement with ResNet-50 comparing to the CE; on CAMELYON-17, replacing CE with NCMI improves the macro-F1 by 8.6% over the strongest baseline. Gains are consistent across various architectures and batch sizes, suggesting that NCMI is a practical and competitive alternative to CE.
Widget2Code: From Visual Widgets to UI Code via Multimodal LLMs
Dec 22, 2025User interface to code (UI2Code) aims to generate executable code that can faithfully reconstruct a given input UI. Prior work focuses largely on web pages and mobile screens, leaving app widgets underexplored. Unlike web or mobile UIs with rich hierarchical context, widgets are compact, context-free micro-interfaces that summarize key information through dense layouts and iconography under strict spatial constraints. Moreover, while (image, code) pairs are widely available for web or mobile UIs, widget designs are proprietary and lack accessible markup. We formalize this setting as the Widget-to-Code (Widget2Code) and introduce an image-only widget benchmark with fine-grained, multi-dimensional evaluation metrics. Benchmarking shows that although generalized multimodal large language models (MLLMs) outperform specialized UI2Code methods, they still produce unreliable and visually inconsistent code. To address these limitations, we develop a baseline that jointly advances perceptual understanding and structured code generation. At the perceptual level, we follow widget design principles to assemble atomic components into complete layouts, equipped with icon retrieval and reusable visualization modules. At the system level, we design an end-to-end infrastructure, WidgetFactory, which includes a framework-agnostic widget-tailored domain-specific language (WidgetDSL) and a compiler that translates it into multiple front-end implementations (e.g., React, HTML/CSS). An adaptive rendering module further refines spatial dimensions to satisfy compactness constraints. Together, these contributions substantially enhance visual fidelity, establishing a strong baseline and unified infrastructure for future Widget2Code research.
JPEG Compliant Compression for Both Human and Machine, A Report
Mar 13, 2025Deep Neural Networks (DNNs) have become an integral part of our daily lives, especially in vision-related applications. However, the conventional lossy image compression algorithms are primarily designed for the Human Vision System (HVS), which can non-trivially compromise the DNNs' validation accuracy after compression, as noted in \cite{liu2018deepn}. Thus developing an image compression algorithm for both human and machine (DNNs) is on the horizon. To address the challenge mentioned above, in this paper, we first formulate the image compression as a multi-objective optimization problem which take both human and machine prespectives into account, then we solve it by linear combination, and proposed a novel distortion measure for both human and machine, dubbed Human and Machine-Oriented Error (HMOE). After that, we develop Human And Machine Oriented Soft Decision Quantization (HMOSDQ) based on HMOE, a lossy image compression algorithm for both human and machine (DNNs), and fully complied with JPEG format. In order to evaluate the performance of HMOSDQ, finally we conduct the experiments for two pre-trained well-known DNN-based image classifiers named Alexnet \cite{Alexnet} and VGG-16 \cite{simonyan2014VGG} on two subsets of the ImageNet \cite{deng2009imagenet} validation set: one subset included images with shorter side in the range of 496 to 512, while the other included images with shorter side in the range of 376 to 384. Our results demonstrate that HMOSDQ outperforms the default JPEG algorithm in terms of rate-accuracy and rate-distortion performance. For the Alexnet comparing with the default JPEG algorithm, HMOSDQ can improve the validation accuracy by more than $0.81\%$ at $0.61$ BPP, or equivalently reduce the compression rate of default JPEG by $9.6\times$ while maintaining the same validation accuracy.
Distributed Quasi-Newton Method for Fair and Fast Federated Learning
Jan 18, 2025Federated learning (FL) is a promising technology that enables edge devices/clients to collaboratively and iteratively train a machine learning model under the coordination of a central server. The most common approach to FL is first-order methods, where clients send their local gradients to the server in each iteration. However, these methods often suffer from slow convergence rates. As a remedy, second-order methods, such as quasi-Newton, can be employed in FL to accelerate its convergence. Unfortunately, similarly to the first-order FL methods, the application of second-order methods in FL can lead to unfair models, achieving high average accuracy while performing poorly on certain clients' local datasets. To tackle this issue, in this paper we introduce a novel second-order FL framework, dubbed \textbf{d}istributed \textbf{q}uasi-\textbf{N}ewton \textbf{fed}erated learning (DQN-Fed). This approach seeks to ensure fairness while leveraging the fast convergence properties of quasi-Newton methods in the FL context. Specifically, DQN-Fed helps the server update the global model in such a way that (i) all local loss functions decrease to promote fairness, and (ii) the rate of change in local loss functions aligns with that of the quasi-Newton method. We prove the convergence of DQN-Fed and demonstrate its \textit{linear-quadratic} convergence rate. Moreover, we validate the efficacy of DQN-Fed across a range of federated datasets, showing that it surpasses state-of-the-art fair FL methods in fairness, average accuracy and convergence speed.
How to Train the Teacher Model for Effective Knowledge Distillation
Jul 25, 2024Recently, it was shown that the role of the teacher in knowledge distillation (KD) is to provide the student with an estimate of the true Bayes conditional probability density (BCPD). Notably, the new findings propose that the student's error rate can be upper-bounded by the mean squared error (MSE) between the teacher's output and BCPD. Consequently, to enhance KD efficacy, the teacher should be trained such that its output is close to BCPD in MSE sense. This paper elucidates that training the teacher model with MSE loss equates to minimizing the MSE between its output and BCPD, aligning with its core responsibility of providing the student with a BCPD estimate closely resembling it in MSE terms. In this respect, through a comprehensive set of experiments, we demonstrate that substituting the conventional teacher trained with cross-entropy loss with one trained using MSE loss in state-of-the-art KD methods consistently boosts the student's accuracy, resulting in improvements of up to 2.6\%.
Adversarial Training via Adaptive Knowledge Amalgamation of an Ensemble of Teachers
May 22, 2024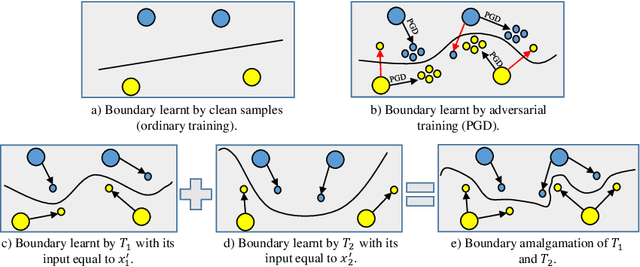

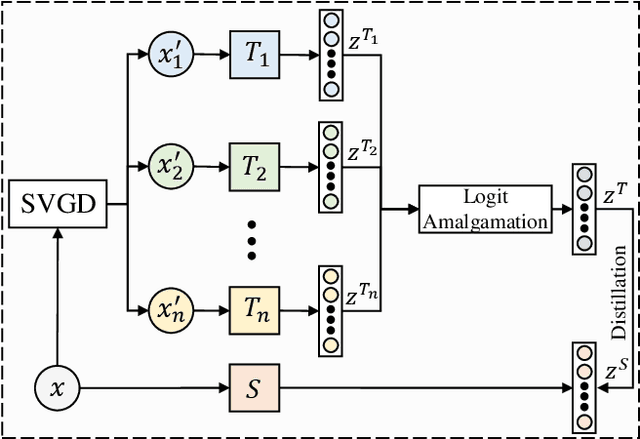
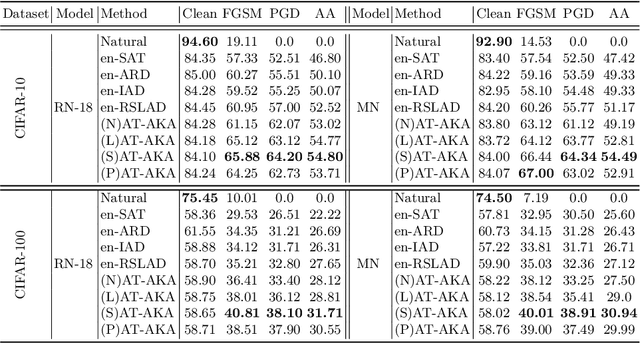
Adversarial training (AT) is a popular method for training robust deep neural networks (DNNs) against adversarial attacks. Yet, AT suffers from two shortcomings: (i) the robustness of DNNs trained by AT is highly intertwined with the size of the DNNs, posing challenges in achieving robustness in smaller models; and (ii) the adversarial samples employed during the AT process exhibit poor generalization, leaving DNNs vulnerable to unforeseen attack types. To address these dual challenges, this paper introduces adversarial training via adaptive knowledge amalgamation of an ensemble of teachers (AT-AKA). In particular, we generate a diverse set of adversarial samples as the inputs to an ensemble of teachers; and then, we adaptively amalgamate the logtis of these teachers to train a generalized-robust student. Through comprehensive experiments, we illustrate the superior efficacy of AT-AKA over existing AT methods and adversarial robustness distillation techniques against cutting-edge attacks, including AutoAttack.
Robustness Against Adversarial Attacks via Learning Confined Adversarial Polytopes
Jan 20, 2024Deep neural networks (DNNs) could be deceived by generating human-imperceptible perturbations of clean samples. Therefore, enhancing the robustness of DNNs against adversarial attacks is a crucial task. In this paper, we aim to train robust DNNs by limiting the set of outputs reachable via a norm-bounded perturbation added to a clean sample. We refer to this set as adversarial polytope, and each clean sample has a respective adversarial polytope. Indeed, if the respective polytopes for all the samples are compact such that they do not intersect the decision boundaries of the DNN, then the DNN is robust against adversarial samples. Hence, the inner-working of our algorithm is based on learning \textbf{c}onfined \textbf{a}dversarial \textbf{p}olytopes (CAP). By conducting a thorough set of experiments, we demonstrate the effectiveness of CAP over existing adversarial robustness methods in improving the robustness of models against state-of-the-art attacks including AutoAttack.
Bayes Conditional Distribution Estimation for Knowledge Distillation Based on Conditional Mutual Information
Jan 16, 2024It is believed that in knowledge distillation (KD), the role of the teacher is to provide an estimate for the unknown Bayes conditional probability distribution (BCPD) to be used in the student training process. Conventionally, this estimate is obtained by training the teacher using maximum log-likelihood (MLL) method. To improve this estimate for KD, in this paper we introduce the concept of conditional mutual information (CMI) into the estimation of BCPD and propose a novel estimator called the maximum CMI (MCMI) method. Specifically, in MCMI estimation, both the log-likelihood and CMI of the teacher are simultaneously maximized when the teacher is trained. Through Eigen-CAM, it is further shown that maximizing the teacher's CMI value allows the teacher to capture more contextual information in an image cluster. Via conducting a thorough set of experiments, we show that by employing a teacher trained via MCMI estimation rather than one trained via MLL estimation in various state-of-the-art KD frameworks, the student's classification accuracy consistently increases, with the gain of up to 3.32\%. This suggests that the teacher's BCPD estimate provided by MCMI method is more accurate than that provided by MLL method. In addition, we show that such improvements in the student's accuracy are more drastic in zero-shot and few-shot settings. Notably, the student's accuracy increases with the gain of up to 5.72\% when 5\% of the training samples are available to the student (few-shot), and increases from 0\% to as high as 84\% for an omitted class (zero-shot). The code is available at \url{https://github.com/iclr2024mcmi/ICLRMCMI}.
Conditional Mutual Information Constrained Deep Learning for Classification
Sep 17, 2023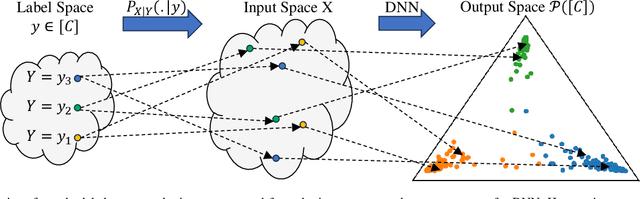
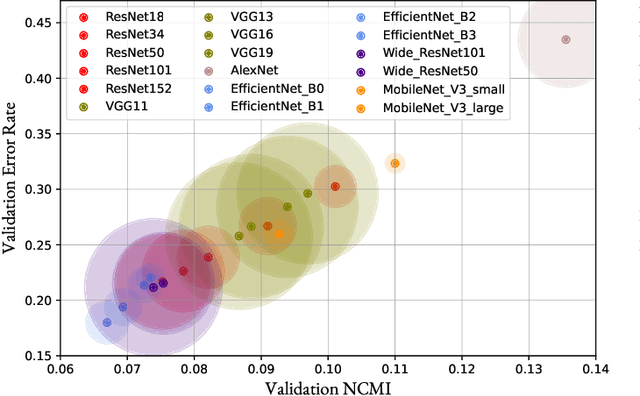
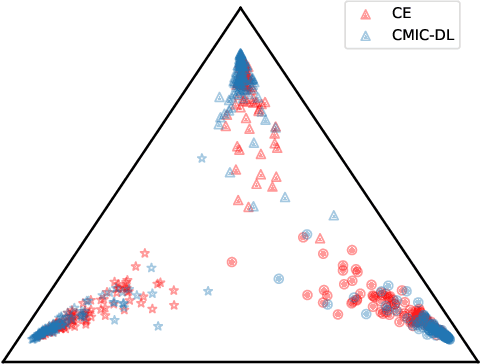
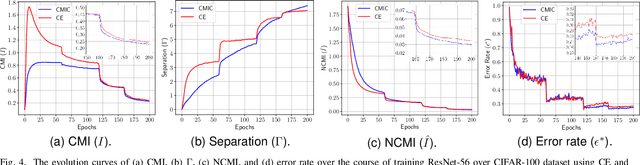
The concepts of conditional mutual information (CMI) and normalized conditional mutual information (NCMI) are introduced to measure the concentration and separation performance of a classification deep neural network (DNN) in the output probability distribution space of the DNN, where CMI and the ratio between CMI and NCMI represent the intra-class concentration and inter-class separation of the DNN, respectively. By using NCMI to evaluate popular DNNs pretrained over ImageNet in the literature, it is shown that their validation accuracies over ImageNet validation data set are more or less inversely proportional to their NCMI values. Based on this observation, the standard deep learning (DL) framework is further modified to minimize the standard cross entropy function subject to an NCMI constraint, yielding CMI constrained deep learning (CMIC-DL). A novel alternating learning algorithm is proposed to solve such a constrained optimization problem. Extensive experiment results show that DNNs trained within CMIC-DL outperform the state-of-the-art models trained within the standard DL and other loss functions in the literature in terms of both accuracy and robustness against adversarial attacks. In addition, visualizing the evolution of learning process through the lens of CMI and NCMI is also advocated.