 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train the Teacher Model for Effective Knowledge Distillation
Jul 25, 2024Recently, it was shown that the role of the teacher in knowledge distillation (KD) is to provide the student with an estimate of the true Bayes conditional probability density (BCPD). Notably, the new findings propose that the student's error rate can be upper-bounded by the mean squared error (MSE) between the teacher's output and BCPD. Consequently, to enhance KD efficacy, the teacher should be trained such that its output is close to BCPD in MSE sense. This paper elucidates that training the teacher model with MSE loss equates to minimizing the MSE between its output and BCPD, aligning with its core responsibility of providing the student with a BCPD estimate closely resembling it in MSE terms. In this respect, through a comprehensive set of experiments, we demonstrate that substituting the conventional teacher trained with cross-entropy loss with one trained using MSE loss in state-of-the-art KD methods consistently boosts the student's accuracy, resulting in improvements of up to 2.6\%.
Bayes Conditional Distribution Estimation for Knowledge Distillation Based on Conditional Mutual Information
Jan 16, 2024It is believed that in knowledge distillation (KD), the role of the teacher is to provide an estimate for the unknown Bayes conditional probability distribution (BCPD) to be used in the student training process. Conventionally, this estimate is obtained by training the teacher using maximum log-likelihood (MLL) method. To improve this estimate for KD, in this paper we introduce the concept of conditional mutual information (CMI) into the estimation of BCPD and propose a novel estimator called the maximum CMI (MCMI) method. Specifically, in MCMI estimation, both the log-likelihood and CMI of the teacher are simultaneously maximized when the teacher is trained. Through Eigen-CAM, it is further shown that maximizing the teacher's CMI value allows the teacher to capture more contextual information in an image cluster. Via conducting a thorough set of experiments, we show that by employing a teacher trained via MCMI estimation rather than one trained via MLL estimation in various state-of-the-art KD frameworks, the student's classification accuracy consistently increases, with the gain of up to 3.32\%. This suggests that the teacher's BCPD estimate provided by MCMI method is more accurate than that provided by MLL method. In addition, we show that such improvements in the student's accuracy are more drastic in zero-shot and few-shot settings. Notably, the student's accuracy increases with the gain of up to 5.72\% when 5\% of the training samples are available to the student (few-shot), and increases from 0\% to as high as 84\% for an omitted class (zero-shot). The code is available at \url{https://github.com/iclr2024mcmi/ICLRMCMI}.
Conditional Mutual Information Constrained Deep Learning for Classification
Sep 17, 2023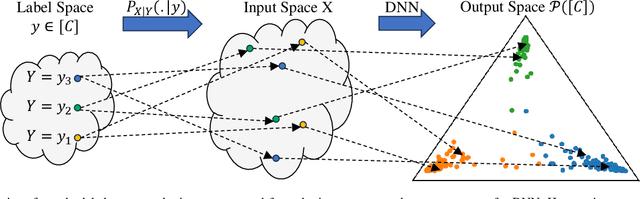
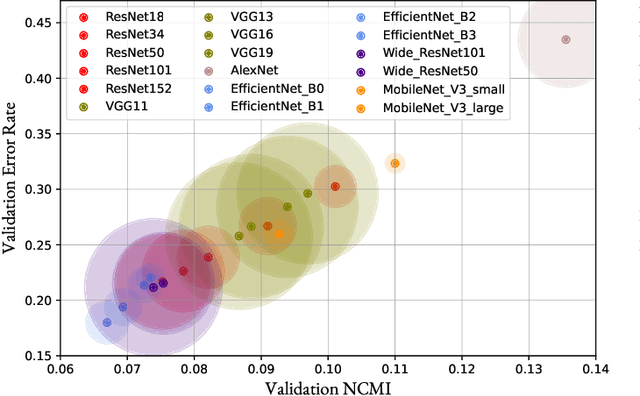
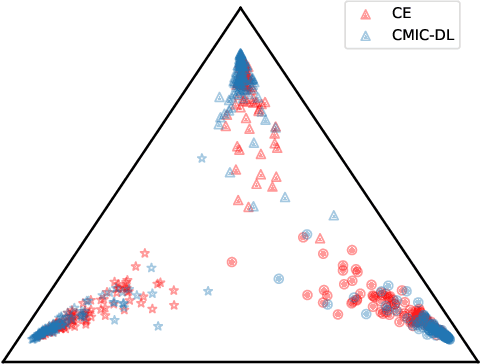
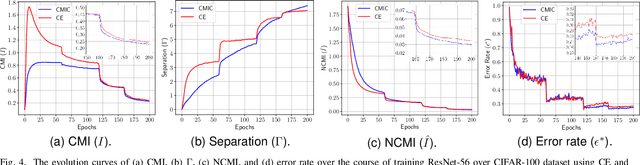
The concepts of conditional mutual information (CMI) and normalized conditional mutual information (NCMI) are introduced to measure the concentration and separation performance of a classification deep neural network (DNN) in the output probability distribution space of the DNN, where CMI and the ratio between CMI and NCMI represent the intra-class concentration and inter-class separation of the DNN, respectively. By using NCMI to evaluate popular DNNs pretrained over ImageNet in the literature, it is shown that their validation accuracies over ImageNet validation data set are more or less inversely proportional to their NCMI values. Based on this observation, the standard deep learning (DL) framework is further modified to minimize the standard cross entropy function subject to an NCMI constraint, yielding CMI constrained deep learning (CMIC-DL). A novel alternating learning algorithm is proposed to solve such a constrained optimization problem. Extensive experiment results show that DNNs trained within CMIC-DL outperform the state-of-the-art models trained within the standard DL and other loss functions in the literature in terms of both accuracy and robustness against adversarial attacks. In addition, visualizing the evolution of learning process through the lens of CMI and NCMI is also advocated.
Dual Graph enhanced Embedding Neural Network for CTR Prediction
Jun 08, 2021



CTR prediction, which aims to estimate the probability that a user will click an item, plays a crucial role in online advertising and recommender system. Feature interaction modeling based and user interest mining based methods are the two kinds of most popular techniques that have been extensively explored for many years and have made great progress for CTR prediction. However, (1) feature interaction based methods which rely heavily on the co-occurrence of different features, may suffer from the feature sparsity problem (i.e., many features appear few times); (2) user interest mining based methods which need rich user behaviors to obtain user's diverse interests, are easy to encounter the behavior sparsity problem (i.e., many users have very short behavior sequences). To solve these problems, we propose a novel module named Dual Graph enhanced Embedding, which is compatible with various CTR prediction models to alleviate these two problems. We further propose a Dual Graph enhanced Embedding Neural Network (DG-ENN) for CTR prediction. Dual Graph enhanced Embedding exploits the strengths of graph representation with two carefully designed learning strategies (divide-and-conquer, curriculum-learning-inspired organized learning) to refine the embedding. We conduct comprehensive experiments on three real-world industrial datasets. The experimental results show that our proposed DG-ENN significantly outperforms state-of-the-art CTR prediction models. Moreover, when applying to state-of-the-art CTR prediction models, Dual graph enhanced embedding always obtains better performance. Further case studies prove that our proposed dual graph enhanced embedding could alleviate the feature sparsity and behavior sparsity problems. Our framework will be open-source based on MindSpore in the near future.