 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIonopedia: an LLM agent orchestrating multimodal learning for ionic liquid discovery
Nov 14, 2025The discovery of novel Ionic Liquids (ILs) is hindered by critical challenges in property prediction, including limited data, poor model accuracy, and fragmented workflows. Leveraging the power of Large Language Models (LLMs), we introduce AIonopedia, to the best of our knowledge, the first LLM agent for IL discovery. Powered by an LLM-augmented multimodal domain foundation model for ILs, AIonopedia enables accurate property predictions and incorporates a hierarchical search architecture for molecular screening and design. Trained and evaluated on a newly curated and comprehensive IL dataset, our model delivers superior performance. Complementing these results, evaluations on literature-reported systems indicate that the agent can perform effective IL modification. Moving beyond offline tests, the practical efficacy was further confirmed through real-world wet-lab validation, in which the agent demonstrated exceptional generalization capabilities on challenging out-of-distribution tasks, underscoring its ability to accelerate real-world IL discovery.
SE3Set: Harnessing equivariant hypergraph neural networks for molecular representation learning
May 26, 2024In this paper, we develop SE3Set, an SE(3) equivariant hypergraph neural network architecture tailored for advanced molecular representation learning. Hypergraphs are not merely an extension of traditional graphs; they are pivotal for modeling high-order relationships, a capability that conventional equivariant graph-based methods lack due to their inherent limitations in representing intricate many-body interactions. To achieve this, we first construct hypergraphs via proposing a new fragmentation method that considers both chemical and three-dimensional spatial information of molecular system. We then design SE3Set, which incorporates equivariance into the hypergragh neural network. This ensures that the learned molecular representations are invariant to spatial transformations, thereby providing robustness essential for accurate prediction of molecular properties. SE3Set has shown performance on par with state-of-the-art (SOTA) models for small molecule datasets like QM9 and MD17. It excels on the MD22 dataset, achieving a notable improvement of approximately 20% in accuracy across all molecules, which highlights the prevalence of complex many-body interactions in larger molecules. This exceptional performance of SE3Set across diverse molecular structures underscores its transformative potential in computational chemistry, offering a route to more accurate and physically nuanced modeling.
Reversible Upper Confidence Bound Algorithm to Generate Diverse Optimized Candidates
Dec 30, 2021
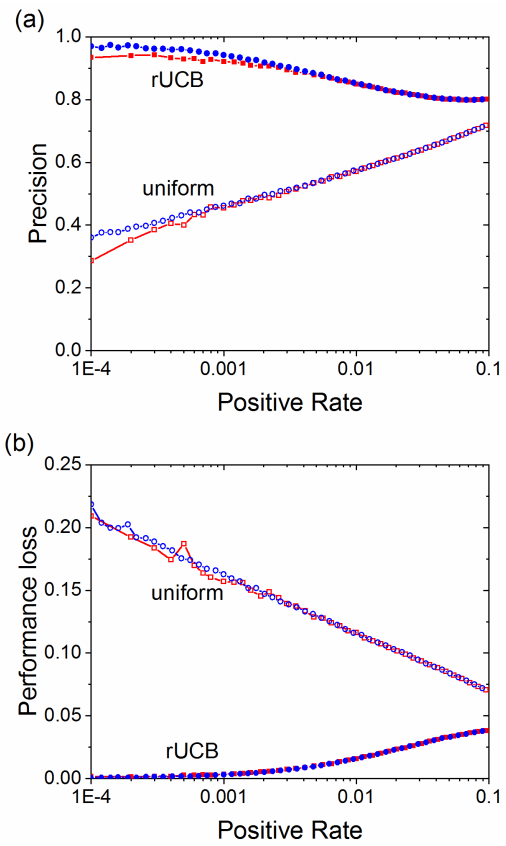
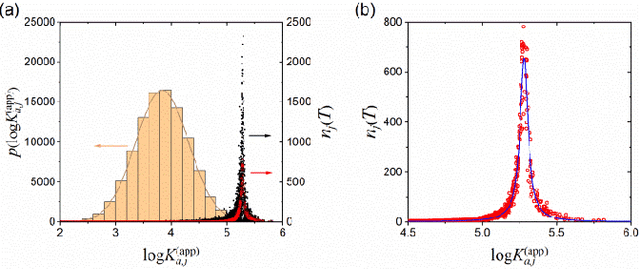
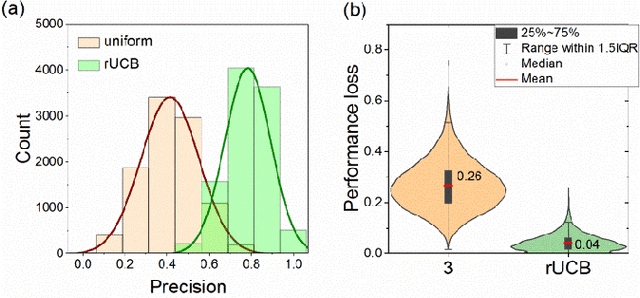
Most algorithms for the multi-armed bandit problem in reinforcement learning aimed to maximize the expected reward, which are thus useful in searching the optimized candidate with the highest reward (function value) for diverse applications (e.g., AlphaGo). However, in some typical application scenaios such as drug discovery, the aim is to search a diverse set of candidates with high reward. Here we propose a reversible upper confidence bound (rUCB) algorithm for such a purpose, and demonstrate its application in virtual screening upon intrinsically disordered proteins (IDPs). It is shown that rUCB greatly reduces the query times while achieving both high accuracy and low performance loss.The rUCB may have potential application in multipoint optimization and other reinforcement-learning cases.
* 10 pages, 10 figures
Retrieval & Interaction Machine for Tabular Data Prediction
Aug 11, 2021

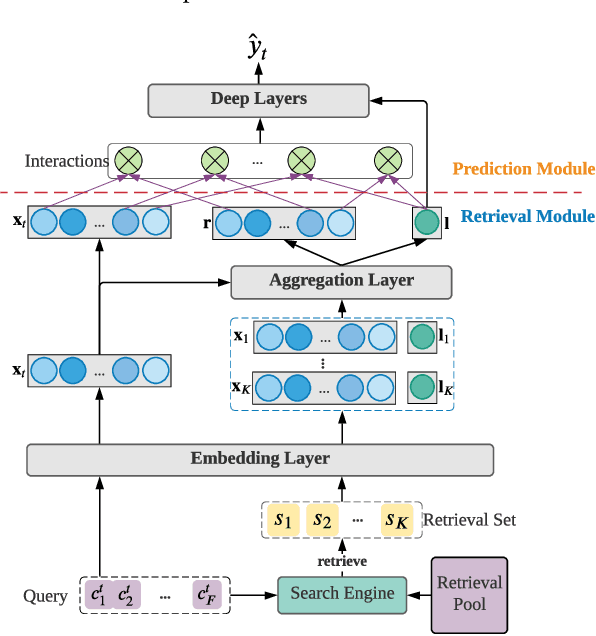

Prediction over tabular data is an essential task in many data science applications such as recommender systems, online advertising, medical treatment, etc. Tabular data is structured into rows and columns, with each row as a data sample and each column as a feature attribute. Both the columns and rows of the tabular data carry useful patterns that could improve the model prediction performance. However, most existing models focus on the cross-column patterns yet overlook the cross-row patterns as they deal with single samples independently. In this work, we propose a general learning framework named Retrieval & Interaction Machine (RIM) that fully exploits both cross-row and cross-column patterns among tabular data. Specifically, RIM first leverages search engine techniques to efficiently retrieve useful rows of the table to assist the label prediction of the target row, then uses feature interaction networks to capture the cross-column patterns among the target row and the retrieved rows so as to make the final label prediction. We conduct extensive experiments on 11 datasets of three important tasks, i.e., CTR prediction (classification), top-n recommendation (ranking) and rating prediction (regression). Experimental results show that RIM achieves significant improvements over the state-of-the-art and various baselines, demonstrating the superiority and efficacy of RIM.
AutoFT: Automatic Fine-Tune for Parameters Transfer Learning in Click-Through Rate Prediction
Jun 09, 2021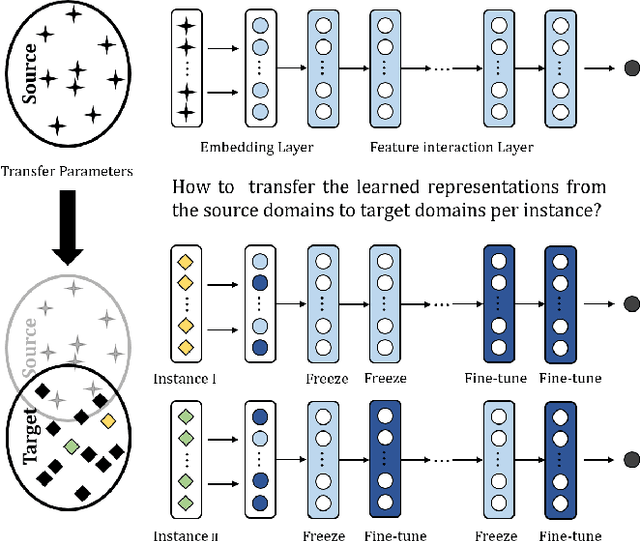

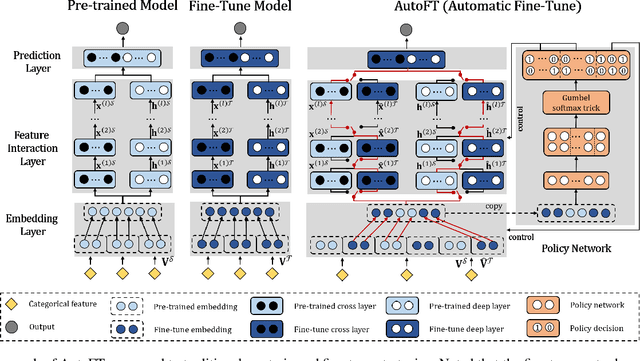
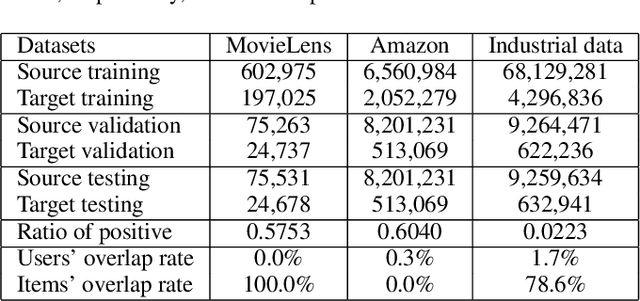
Recommender systems are often asked to serve multiple recommendation scenarios or domains. Fine-tuning a pre-trained CTR model from source domains and adapting it to a target domain allows knowledge transferring. However, optimizing all the parameters of the pre-trained network may result in over-fitting if the target dataset is small and the number of parameters is large. This leads us to think of directly reusing parameters in the pre-trained model which represent more general features learned from multiple domains. However, the design of freezing or fine-tuning layers of parameters requires much manual effort since the decision highly depends on the pre-trained model and target instances. In this work, we propose an end-to-end transfer learning framework, called Automatic Fine-Tuning (AutoFT), for CTR prediction. AutoFT consists of a field-wise transfer policy and a layer-wise transfer policy. The field-wise transfer policy decides how the pre-trained embedding representations are frozen or fine-tuned based on the given instance from the target domain. The layer-wise transfer policy decides how the high?order feature representations are transferred layer by layer. Extensive experiments on two public benchmark datasets and one private industrial dataset demonstrate that AutoFT can significantly improve the performance of CTR prediction compared with state-of-the-art transferring approaches.
Dual Graph enhanced Embedding Neural Network for CTR Prediction
Jun 08, 2021



CTR prediction, which aims to estimate the probability that a user will click an item, plays a crucial role in online advertising and recommender system. Feature interaction modeling based and user interest mining based methods are the two kinds of most popular techniques that have been extensively explored for many years and have made great progress for CTR prediction. However, (1) feature interaction based methods which rely heavily on the co-occurrence of different features, may suffer from the feature sparsity problem (i.e., many features appear few times); (2) user interest mining based methods which need rich user behaviors to obtain user's diverse interests, are easy to encounter the behavior sparsity problem (i.e., many users have very short behavior sequences). To solve these problems, we propose a novel module named Dual Graph enhanced Embedding, which is compatible with various CTR prediction models to alleviate these two problems. We further propose a Dual Graph enhanced Embedding Neural Network (DG-ENN) for CTR prediction. Dual Graph enhanced Embedding exploits the strengths of graph representation with two carefully designed learning strategies (divide-and-conquer, curriculum-learning-inspired organized learning) to refine the embedding. We conduct comprehensive experiments on three real-world industrial datasets. The experimental results show that our proposed DG-ENN significantly outperforms state-of-the-art CTR prediction models. Moreover, when applying to state-of-the-art CTR prediction models, Dual graph enhanced embedding always obtains better performance. Further case studies prove that our proposed dual graph enhanced embedding could alleviate the feature sparsity and behavior sparsity problems. Our framework will be open-source based on MindSpore in the near future.
A Practical Incremental Method to Train Deep CTR Models
Sep 04, 2020



Deep learning models in recommender systems are usually trained in the batch mode, namely iteratively trained on a fixed-size window of training data. Such batch mode training of deep learning models suffers from low training efficiency, which may lead to performance degradation when the model is not produced on time. To tackle this issue, incremental learning is proposed and has received much attention recently. Incremental learning has great potential in recommender systems, as two consecutive window of training data overlap most of the volume. It aims to update the model incrementally with only the newly incoming samples from the timestamp when the model is updated last time, which is much more efficient than the batch mode training. However, most of the incremental learning methods focus on the research area of image recognition where new tasks or classes are learned over time. In this work, we introduce a practical incremental method to train deep CTR models, which consists of three decoupled modules (namely, data, feature and model module). Our method can achieve comparable performance to the conventional batch mode training with much better training efficiency. We conduct extensive experiments on a public benchmark and a private dataset to demonstrate the effectiveness of our proposed method.
Uncovering Download Fraud Activities in Mobile App Markets
Jul 05, 2019

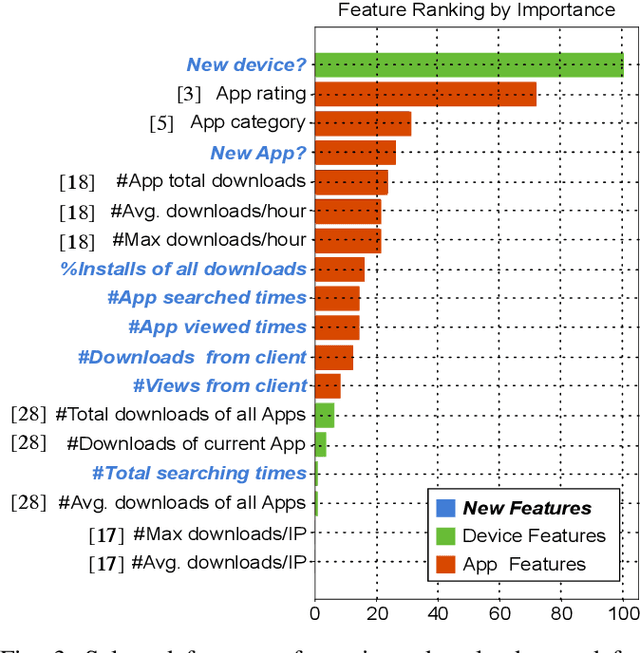

Download fraud is a prevalent threat in mobile App markets, where fraudsters manipulate the number of downloads of Apps via various cheating approaches. Purchased fake downloads can mislead recommendation and search algorithms and further lead to bad user experience in App markets. In this paper, we investigate download fraud problem based on a company's App Market, which is one of the most popular Android App markets. We release a honeypot App on the App Market and purchase fake downloads from fraudster agents to track fraud activities in the wild. Based on our interaction with the fraudsters, we categorize download fraud activities into three types according to their intentions: boosting front end downloads, optimizing App search ranking, and enhancing user acquisition&retention rate. For the download fraud aimed at optimizing App search ranking, we select, evaluate, and validate several features in identifying fake downloads based on billions of download data. To get a comprehensive understanding of download fraud, we further gather stances of App marketers, fraudster agencies, and market operators on download fraud. The followed analysis and suggestions shed light on the ways to mitigate download fraud in App markets and other social platforms. To the best of our knowledge, this is the first work that investigates the download fraud problem in mobile App markets.