 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB SwinT: A Dual-Branch Swin Transformer Network for Road Extraction in Optical Remote Sensing Imagery
Mar 25, 2026With the continuous improvement in the spatial resolution of optical remote sensing imagery, accurate road extraction has become increasingly important for applications such as urban planning, traffic monitoring, and disaster management. However, road extraction in complex urban and rural environments remains challenging, as roads are often occluded by trees, buildings, and other objects, leading to fragmented structures and reduced extraction accuracy. To address this problem, this paper proposes a Dual-Branch Swin Transformer network (DB SwinT) for road extraction. The proposed framework combines the long-range dependency modeling capability of the Swin Transformer with the multi-scale feature fusion strategy of U-Net, and employs a dual-branch encoder to learn complementary local and global representations. Specifically, the local branch focuses on recovering fine structural details in occluded areas, while the global branch captures broader semantic context to preserve the overall continuity of road networks. In addition, an Attentional Feature Fusion (AFF) module is introduced to adaptively fuse features from the two branches, further enhancing the representation of occluded road segments. Experimental results on the Massachusetts and DeepGlobe datasets show that DB SwinT achieves Intersection over Union (IoU) scores of 79.35\% and 74.84\%, respectively, demonstrating its effectiveness for road extraction from optical remote sensing imagery.
Enhancing robustness of data-driven SHM models: adversarial training with circle loss
Jun 20, 2024



Structural health monitoring (SHM) is critical to safeguarding the safety and reliability of aerospace, civil, and mechanical infrastructure. Machine learning-based data-driven approaches have gained popularity in SHM due to advancements in sensors and computational power. However, machine learning models used in SHM are vulnerable to adversarial examples -- even small changes in input can lead to different model outputs. This paper aims to address this problem by discussing adversarial defenses in SHM. In this paper, we propose an adversarial training method for defense, which uses circle loss to optimize the distance between features in training to keep examples away from the decision boundary. Through this simple yet effective constraint, our method demonstrates substantial improvements in model robustness, surpassing existing defense mechanisms.
Generalized Category Discovery with Clustering Assignment Consistency
Oct 30, 2023Generalized category discovery (GCD) is a recently proposed open-world task. Given a set of images consisting of labeled and unlabeled instances, the goal of GCD is to automatically cluster the unlabeled samples using information transferred from the labeled dataset. The unlabeled dataset comprises both known and novel classes. The main challenge is that unlabeled novel class samples and unlabeled known class samples are mixed together in the unlabeled dataset. To address the GCD without knowing the class number of unlabeled dataset, we propose a co-training-based framework that encourages clustering consistency. Specifically, we first introduce weak and strong augmentation transformations to generate two sufficiently different views for the same sample. Then, based on the co-training assumption, we propose a consistency representation learning strategy, which encourages consistency between feature-prototype similarity and clustering assignment. Finally, we use the discriminative embeddings learned from the semi-supervised representation learning process to construct an original sparse network and use a community detection method to obtain the clustering results and the number of categories simultaneously. Extensive experiments show that our method achieves state-of-the-art performance on three generic benchmarks and three fine-grained visual recognition datasets. Especially in the ImageNet-100 data set, our method significantly exceeds the best baseline by 15.5\% and 7.0\% on the \texttt{Novel} and \texttt{All} classes, respectively.
Gradient Imitation Reinforcement Learning for General Low-Resource Information Extraction
Nov 14, 2022



Information Extraction (IE) aims to extract structured information from heterogeneous sources. IE from natural language texts include sub-tasks such as Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE). Most IE systems require comprehensive understandings of sentence structure, implied semantics, and domain knowledge to perform well; thus, IE tasks always need adequate external resources and annotations. However, it takes time and effort to obtain more human annotations. Low-Resource Information Extraction (LRIE) strives to use unsupervised data, reducing the required resources and human annotation. In practice, existing systems either utilize self-training schemes to generate pseudo labels that will cause the gradual drift problem, or leverage consistency regularization methods which inevitably possess confirmation bias. To alleviate confirmation bias due to the lack of feedback loops in existing LRIE learning paradigms, we develop a Gradient Imitation Reinforcement Learning (GIRL) method to encourage pseudo-labeled data to imitate the gradient descent direction on labeled data, which can force pseudo-labeled data to achieve better optimization capabilities similar to labeled data. Based on how well the pseudo-labeled data imitates the instructive gradient descent direction obtained from labeled data, we design a reward to quantify the imitation process and bootstrap the optimization capability of pseudo-labeled data through trial and error. In addition to learning paradigms, GIRL is not limited to specific sub-tasks, and we leverage GIRL to solve all IE sub-tasks (named entity recognition, relation extraction, and event extraction) in low-resource settings (semi-supervised IE and few-shot IE).
AutoFT: Automatic Fine-Tune for Parameters Transfer Learning in Click-Through Rate Prediction
Jun 09, 2021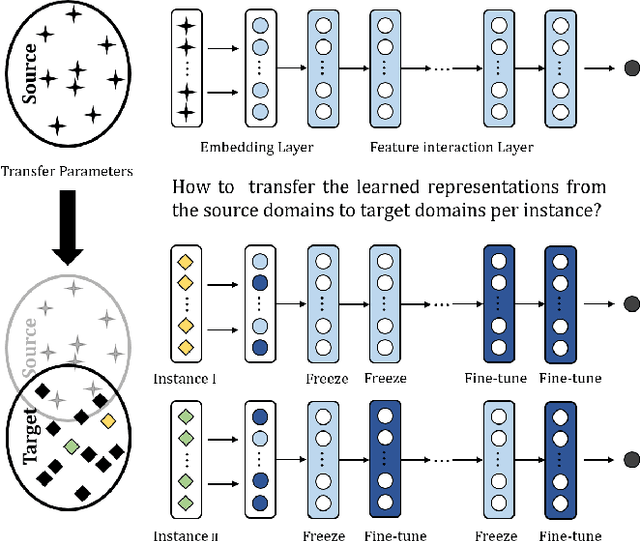

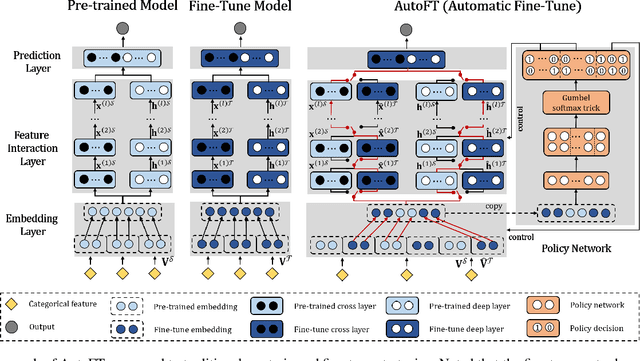
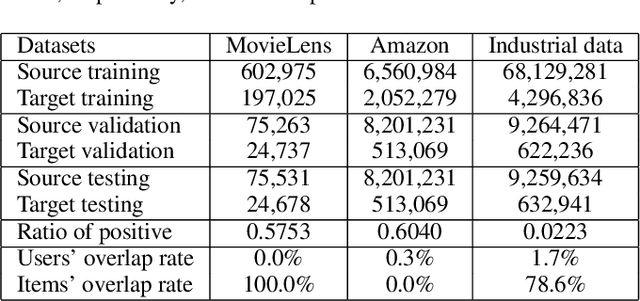
Recommender systems are often asked to serve multiple recommendation scenarios or domains. Fine-tuning a pre-trained CTR model from source domains and adapting it to a target domain allows knowledge transferring. However, optimizing all the parameters of the pre-trained network may result in over-fitting if the target dataset is small and the number of parameters is large. This leads us to think of directly reusing parameters in the pre-trained model which represent more general features learned from multiple domains. However, the design of freezing or fine-tuning layers of parameters requires much manual effort since the decision highly depends on the pre-trained model and target instances. In this work, we propose an end-to-end transfer learning framework, called Automatic Fine-Tuning (AutoFT), for CTR prediction. AutoFT consists of a field-wise transfer policy and a layer-wise transfer policy. The field-wise transfer policy decides how the pre-trained embedding representations are frozen or fine-tuned based on the given instance from the target domain. The layer-wise transfer policy decides how the high?order feature representations are transferred layer by layer. Extensive experiments on two public benchmark datasets and one private industrial dataset demonstrate that AutoFT can significantly improve the performance of CTR prediction compared with state-of-the-art transferring approaches.
A Survey on Deep Semi-supervised Learning
Feb 28, 2021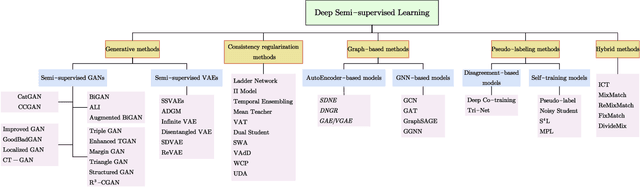

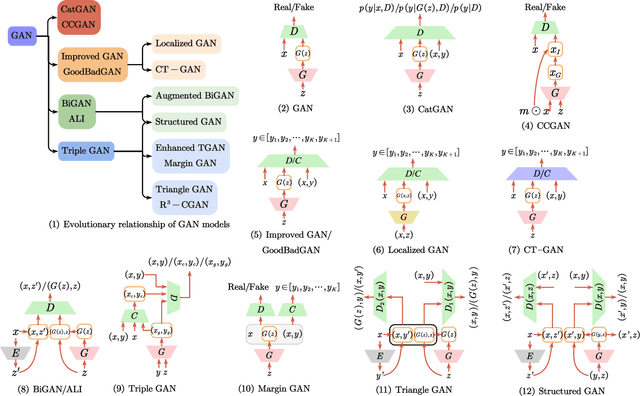
Deep semi-supervised learning is a fast-growing field with a range of practical applications. This paper provides a comprehensive survey on both fundamentals and recent advances in deep semi-supervised learning methods from model design perspectives and unsupervised loss functions. We first present a taxonomy for deep semi-supervised learning that categorizes existing methods, including deep generative methods, consistency regularization methods, graph-based methods, pseudo-labeling methods, and hybrid methods. Then we offer a detailed comparison of these methods in terms of the type of losses, contributions, and architecture differences. In addition to the past few years' progress, we further discuss some shortcomings of existing methods and provide some tentative heuristic solutions for solving these open problems.
Graph-based Semi-supervised Learning: A Comprehensive Review
Feb 26, 2021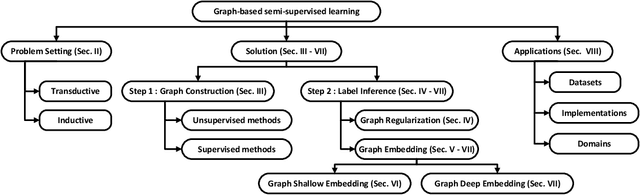
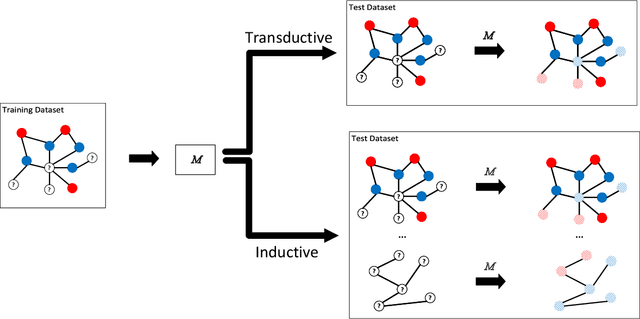
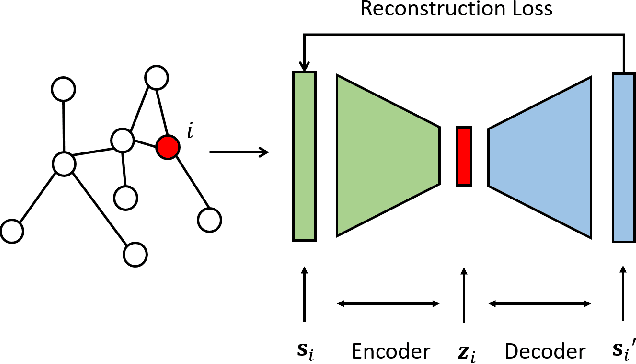
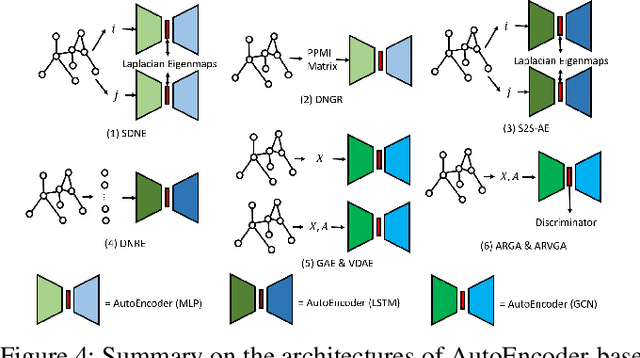
Semi-supervised learning (SSL) has tremendous value in practice due to its ability to utilize both labeled data and unlabelled data. An important class of SSL methods is to naturally represent data as graphs such that the label information of unlabelled samples can be inferred from the graphs, which corresponds to graph-based semi-supervised learning (GSSL) methods. GSSL methods have demonstrated their advantages in various domains due to their uniqueness of structure, the universality of applications, and their scalability to large scale data. Focusing on this class of methods, this work aims to provide both researchers and practitioners with a solid and systematic understanding of relevant advances as well as the underlying connections among them. This makes our paper distinct from recent surveys that cover an overall picture of SSL methods while neglecting fundamental understanding of GSSL methods. In particular, a major contribution of this paper lies in a new generalized taxonomy for GSSL, including graph regularization and graph embedding methods, with the most up-to-date references and useful resources such as codes, datasets, and applications. Furthermore, we present several potential research directions as future work with insights into this rapidly growing field.
SAR Image Despeckling by Deep Neural Networks: from a pre-trained model to an end-to-end training strategy
Jul 02, 2020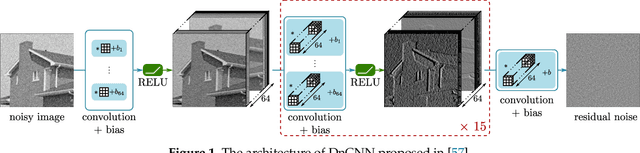
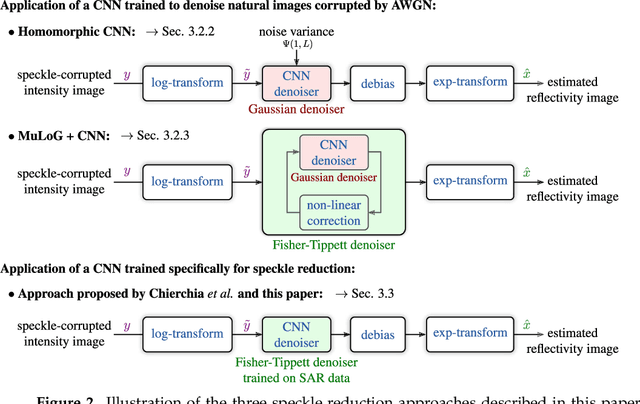
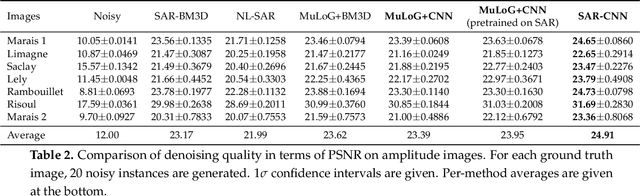
Speckle reduction is a longstanding topic in synthetic aperture radar (SAR) images. Many different schemes have been proposed for the restoration of intensity SAR images. Among the different possible approaches, methods based on convolutional neural networks (CNNs) have recently shown to reach state-of-the-art performance for SAR image restoration. CNN training requires good training data: many pairs of speckle-free / speckle-corrupted images. This is an issue in SAR applications, given the inherent scarcity of speckle-free images. To handle this problem, this paper analyzes different strategies one can adopt, depending on the speckle removal task one wishes to perform and the availability of multitemporal stacks of SAR data. The first strategy applies a CNN model, trained to remove additive white Gaussian noise from natural images, to a recently proposed SAR speckle removal framework: MuLoG (MUlti-channel LOgarithm with Gaussian denoising). No training on SAR images is performed, the network is readily applied to speckle reduction tasks. The second strategy considers a novel approach to construct a reliable dataset of speckle-free SAR images necessary to train a CNN model. Finally, a hybrid approach is also analyzed: the CNN used to remove additive white Gaussian noise is trained on speckle-free SAR images. The proposed methods are compared to other state-of-the-art speckle removal filters, to evaluate the quality of denoising and to discuss the pros and cons of the different strategies. Along with the paper, we make available the weights of the trained network to allow its usage by other researchers.