 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Document-Level Relation Extraction Models to Entity Name Variations
Jun 11, 2024
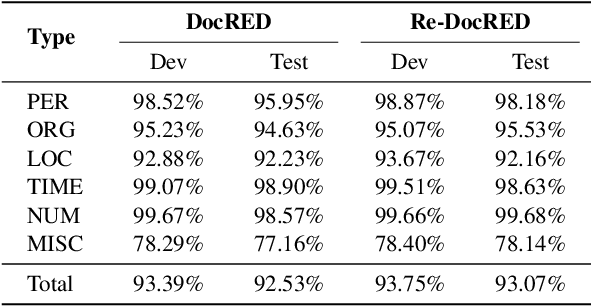

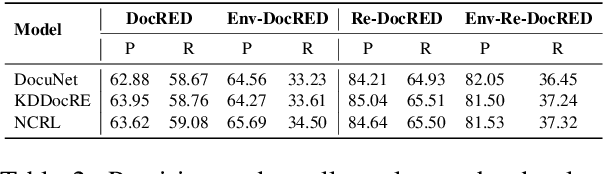
Driven by the demand for cross-sentence and large-scale relation extraction, document-level relation extraction (DocRE) has attracted increasing research interest. Despite the continuous improvement in performance, we find that existing DocRE models which initially perform well may make more mistakes when merely changing the entity names in the document, hindering the generalization to novel entity names. To this end, we systematically investigate the robustness of DocRE models to entity name variations in this work. We first propose a principled pipeline to generate entity-renamed documents by replacing the original entity names with names from Wikidata. By applying the pipeline to DocRED and Re-DocRED datasets, we construct two novel benchmarks named Env-DocRED and Env-Re-DocRED for robustness evaluation. Experimental results show that both three representative DocRE models and two in-context learned large language models consistently lack sufficient robustness to entity name variations, particularly on cross-sentence relation instances and documents with more entities. Finally, we propose an entity variation robust training method which not only improves the robustness of DocRE models but also enhances their understanding and reasoning capabilities. We further verify that the basic idea of this method can be effectively transferred to in-context learning for DocRE as well.
Prompt Me Up: Unleashing the Power of Alignments for Multimodal Entity and Relation Extraction
Oct 25, 2023



How can we better extract entities and relations from text? Using multimodal extraction with images and text obtains more signals for entities and relations, and aligns them through graphs or hierarchical fusion, aiding in extraction. Despite attempts at various fusions, previous works have overlooked many unlabeled image-caption pairs, such as NewsCLIPing. This paper proposes innovative pre-training objectives for entity-object and relation-image alignment, extracting objects from images and aligning them with entity and relation prompts for soft pseudo-labels. These labels are used as self-supervised signals for pre-training, enhancing the ability to extract entities and relations. Experiments on three datasets show an average 3.41% F1 improvement over prior SOTA. Additionally, our method is orthogonal to previous multimodal fusions, and using it on prior SOTA fusions further improves 5.47% F1.
RAPL: A Relation-Aware Prototype Learning Approach for Few-Shot Document-Level Relation Extraction
Oct 24, 2023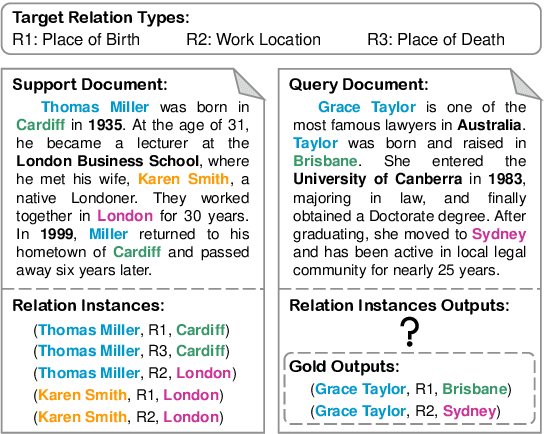
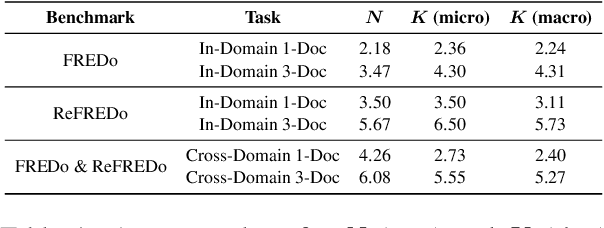
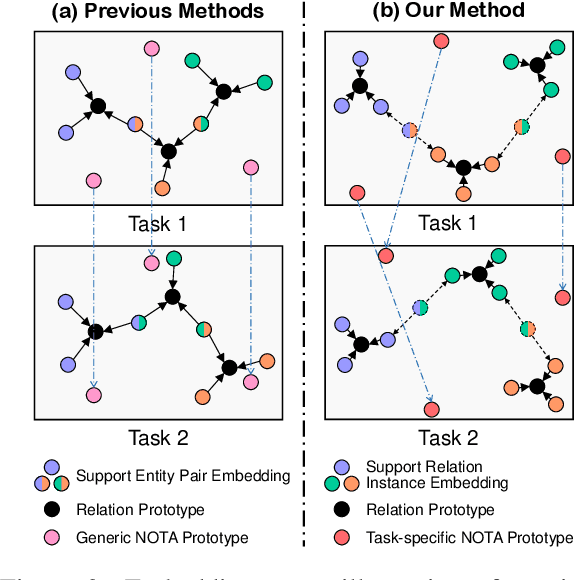

How to identify semantic relations among entities in a document when only a few labeled documents are available? Few-shot document-level relation extraction (FSDLRE) is crucial for addressing the pervasive data scarcity problem in real-world scenarios. Metric-based meta-learning is an effective framework widely adopted for FSDLRE, which constructs class prototypes for classification. However, existing works often struggle to obtain class prototypes with accurate relational semantics: 1) To build prototype for a target relation type, they aggregate the representations of all entity pairs holding that relation, while these entity pairs may also hold other relations, thus disturbing the prototype. 2) They use a set of generic NOTA (none-of-the-above) prototypes across all tasks, neglecting that the NOTA semantics differs in tasks with different target relation types. In this paper, we propose a relation-aware prototype learning method for FSDLRE to strengthen the relational semantics of prototype representations. By judiciously leveraging the relation descriptions and realistic NOTA instances as guidance, our method effectively refines the relation prototypes and generates task-specific NOTA prototypes. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches by average 2.61% $F_1$ across various settings of two FSDLRE benchmarks.
A Semantic Invariant Robust Watermark for Large Language Models
Oct 10, 2023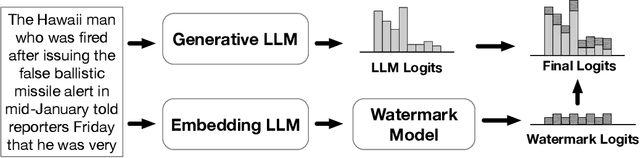
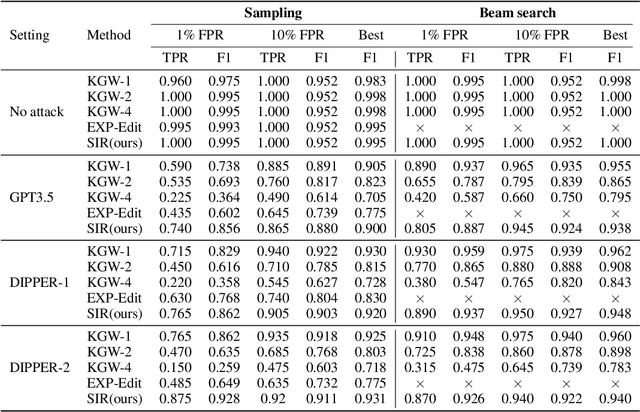
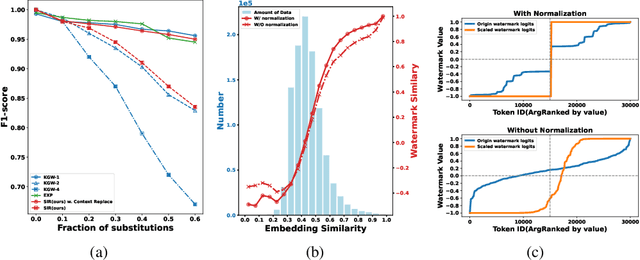
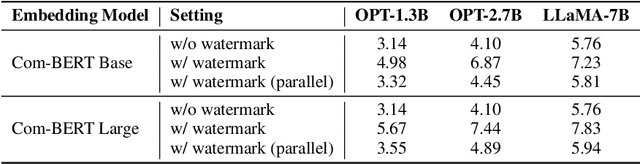
Watermark algorithms for large language models (LLMs) have achieved extremely high accuracy in detecting text generated by LLMs. Such algorithms typically involve adding extra watermark logits to the LLM's logits at each generation step. However, prior algorithms face a trade-off between attack robustness and security robustness. This is because the watermark logits for a token are determined by a certain number of preceding tokens; a small number leads to low security robustness, while a large number results in insufficient attack robustness. In this work, we propose a semantic invariant watermarking method for LLMs that provides both attack robustness and security robustness. The watermark logits in our work are determined by the semantics of all preceding tokens. Specifically, we utilize another embedding LLM to generate semantic embeddings for all preceding tokens, and then these semantic embeddings are transformed into the watermark logits through our trained watermark model. Subsequent analyses and experiments demonstrated the attack robustness of our method in semantically invariant settings: synonym substitution and text paraphrasing settings. Finally, we also show that our watermark possesses adequate security robustness. Our code and data are available at https://github.com/THU-BPM/Robust_Watermark.
Gradient Imitation Reinforcement Learning for General Low-Resource Information Extraction
Nov 14, 2022



Information Extraction (IE) aims to extract structured information from heterogeneous sources. IE from natural language texts include sub-tasks such as Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE). Most IE systems require comprehensive understandings of sentence structure, implied semantics, and domain knowledge to perform well; thus, IE tasks always need adequate external resources and annotations. However, it takes time and effort to obtain more human annotations. Low-Resource Information Extraction (LRIE) strives to use unsupervised data, reducing the required resources and human annotation. In practice, existing systems either utilize self-training schemes to generate pseudo labels that will cause the gradual drift problem, or leverage consistency regularization methods which inevitably possess confirmation bias. To alleviate confirmation bias due to the lack of feedback loops in existing LRIE learning paradigms, we develop a Gradient Imitation Reinforcement Learning (GIRL) method to encourage pseudo-labeled data to imitate the gradient descent direction on labeled data, which can force pseudo-labeled data to achieve better optimization capabilities similar to labeled data. Based on how well the pseudo-labeled data imitates the instructive gradient descent direction obtained from labeled data, we design a reward to quantify the imitation process and bootstrap the optimization capability of pseudo-labeled data through trial and error. In addition to learning paradigms, GIRL is not limited to specific sub-tasks, and we leverage GIRL to solve all IE sub-tasks (named entity recognition, relation extraction, and event extraction) in low-resource settings (semi-supervised IE and few-shot IE).