 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Consistency Matters: Elegant Latent Transition Discrepancy for Generalizable Synthetic Image Detection
Mar 11, 2026Recent rapid advancement of generative models has significantly improved the fidelity and accessibility of AI-generated synthetic images. While enabling various innovative applications, the unprecedented realism of these synthetics makes them increasingly indistinguishable from authentic photographs, posing serious security risks, such as media credibility and content manipulation. Although extensive efforts have been dedicated to detecting synthetic images, most existing approaches suffer from poor generalization to unseen data due to their reliance on model-specific artifacts or low-level statistical cues. In this work, we identify a previously unexplored distinction that real images maintain consistent semantic attention and structural coherence in their latent representations, exhibiting more stable feature transitions across network layers, whereas synthetic ones present discernible distinct patterns. Therefore, we propose a novel approach termed latent transition discrepancy (LTD), which captures the inter-layer consistency differences of real and synthetic images. LTD adaptively identifies the most discriminative layers and assesses the transition discrepancies across layers. Benefiting from the proposed inter-layer discriminative modeling, our approach exceeds the base model by 14.35\% in mean Acc across three datasets containing diverse GANs and DMs. Extensive experiments demonstrate that LTD outperforms recent state-of-the-art methods, achieving superior detection accuracy, generalizability, and robustness. The code is available at https://github.com/yywencs/LTD
On the Robustness of Document-Level Relation Extraction Models to Entity Name Variations
Jun 11, 2024
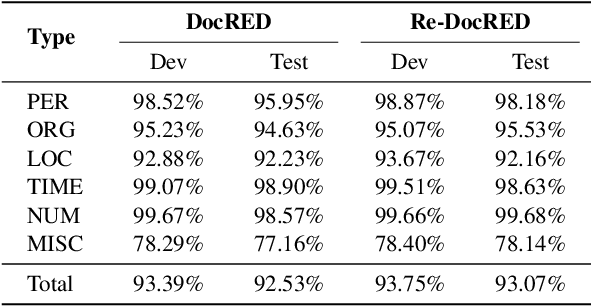

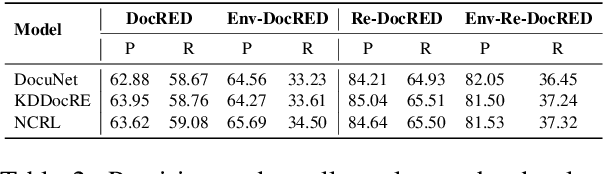
Driven by the demand for cross-sentence and large-scale relation extraction, document-level relation extraction (DocRE) has attracted increasing research interest. Despite the continuous improvement in performance, we find that existing DocRE models which initially perform well may make more mistakes when merely changing the entity names in the document, hindering the generalization to novel entity names. To this end, we systematically investigate the robustness of DocRE models to entity name variations in this work. We first propose a principled pipeline to generate entity-renamed documents by replacing the original entity names with names from Wikidata. By applying the pipeline to DocRED and Re-DocRED datasets, we construct two novel benchmarks named Env-DocRED and Env-Re-DocRED for robustness evaluation. Experimental results show that both three representative DocRE models and two in-context learned large language models consistently lack sufficient robustness to entity name variations, particularly on cross-sentence relation instances and documents with more entities. Finally, we propose an entity variation robust training method which not only improves the robustness of DocRE models but also enhances their understanding and reasoning capabilities. We further verify that the basic idea of this method can be effectively transferred to in-context learning for DocRE as well.
RAPL: A Relation-Aware Prototype Learning Approach for Few-Shot Document-Level Relation Extraction
Oct 24, 2023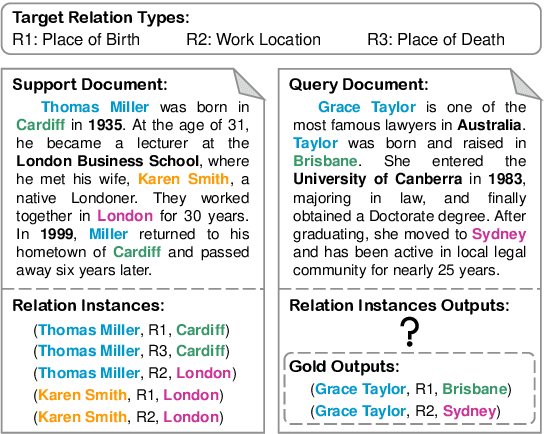
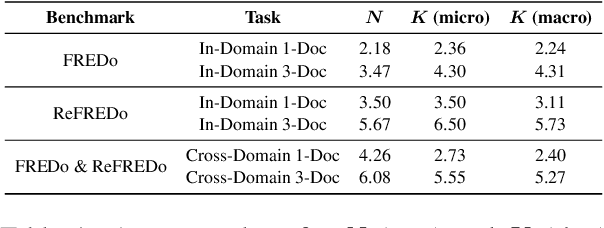
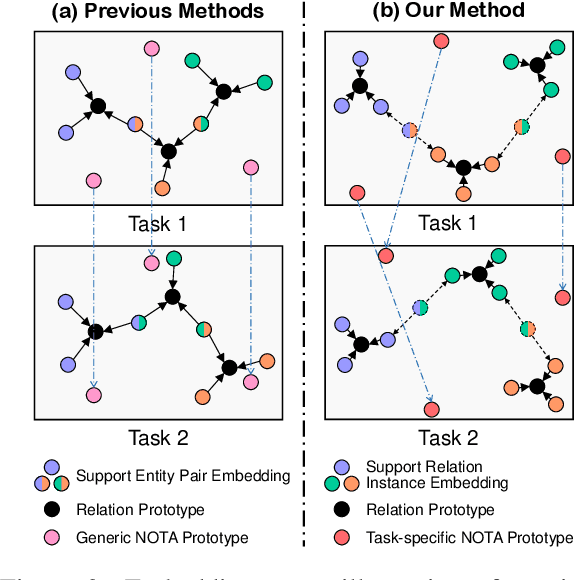

How to identify semantic relations among entities in a document when only a few labeled documents are available? Few-shot document-level relation extraction (FSDLRE) is crucial for addressing the pervasive data scarcity problem in real-world scenarios. Metric-based meta-learning is an effective framework widely adopted for FSDLRE, which constructs class prototypes for classification. However, existing works often struggle to obtain class prototypes with accurate relational semantics: 1) To build prototype for a target relation type, they aggregate the representations of all entity pairs holding that relation, while these entity pairs may also hold other relations, thus disturbing the prototype. 2) They use a set of generic NOTA (none-of-the-above) prototypes across all tasks, neglecting that the NOTA semantics differs in tasks with different target relation types. In this paper, we propose a relation-aware prototype learning method for FSDLRE to strengthen the relational semantics of prototype representations. By judiciously leveraging the relation descriptions and realistic NOTA instances as guidance, our method effectively refines the relation prototypes and generates task-specific NOTA prototypes. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches by average 2.61% $F_1$ across various settings of two FSDLRE benchmarks.
Exploring the Compositional Generalization in Context Dependent Text-to-SQL Parsing
May 29, 2023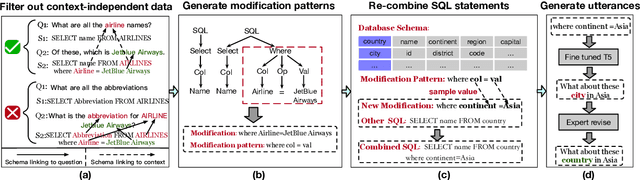
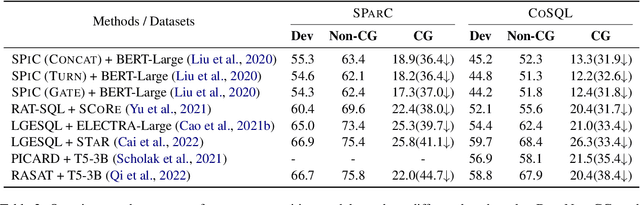
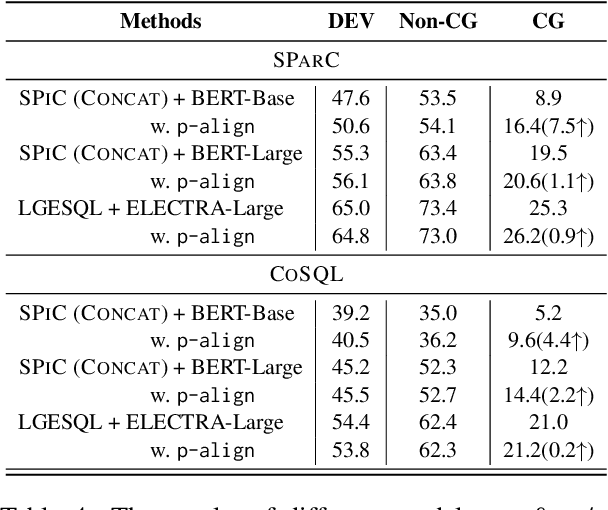

In the context-dependent Text-to-SQL task, the generated SQL statements are refined iteratively based on the user input utterance from each interaction. The input text from each interaction can be viewed as component modifications to the previous SQL statements, which could be further extracted as the modification patterns. Since these modification patterns could also be combined with other SQL statements, the models are supposed to have the compositional generalization to these novel combinations. This work is the first exploration of compositional generalization in context-dependent Text-to-SQL scenarios. To facilitate related studies, we constructed two challenging benchmarks named \textsc{CoSQL-CG} and \textsc{SParC-CG} by recombining the modification patterns and existing SQL statements. The following experiments show that all current models struggle on our proposed benchmarks. Furthermore, we found that better aligning the previous SQL statements with the input utterance could give models better compositional generalization ability. Based on these observations, we propose a method named \texttt{p-align} to improve the compositional generalization of Text-to-SQL models. Further experiments validate the effectiveness of our method. Source code and data are available.
Enhancing Cross-lingual Natural Language Inference by Soft Prompting with Multilingual Verbalizer
May 22, 2023Cross-lingual natural language inference is a fundamental problem in cross-lingual language understanding. Many recent works have used prompt learning to address the lack of annotated parallel corpora in XNLI. However, these methods adopt discrete prompting by simply translating the templates to the target language and need external expert knowledge to design the templates. Besides, discrete prompts of human-designed template words are not trainable vectors and can not be migrated to target languages in the inference stage flexibly. In this paper, we propose a novel Soft prompt learning framework with the Multilingual Verbalizer (SoftMV) for XNLI. SoftMV first constructs cloze-style question with soft prompts for the input sample. Then we leverage bilingual dictionaries to generate an augmented multilingual question for the original question. SoftMV adopts a multilingual verbalizer to align the representations of original and augmented multilingual questions into the same semantic space with consistency regularization. Experimental results on XNLI demonstrate that SoftMV can achieve state-of-the-art performance and significantly outperform the previous methods under the few-shot and full-shot cross-lingual transfer settings.
Gaussian Prior Reinforcement Learning for Nested Named Entity Recognition
May 12, 2023Named Entity Recognition (NER) is a well and widely studied task in natural language processing. Recently, the nested NER has attracted more attention since its practicality and difficulty. Existing works for nested NER ignore the recognition order and boundary position relation of nested entities. To address these issues, we propose a novel seq2seq model named GPRL, which formulates the nested NER task as an entity triplet sequence generation process. GPRL adopts the reinforcement learning method to generate entity triplets decoupling the entity order in gold labels and expects to learn a reasonable recognition order of entities via trial and error. Based on statistics of boundary distance for nested entities, GPRL designs a Gaussian prior to represent the boundary distance distribution between nested entities and adjust the output probability distribution of nested boundary tokens. Experiments on three nested NER datasets demonstrate that GPRL outperforms previous nested NER models.
Character-level White-Box Adversarial Attacks against Transformers via Attachable Subwords Substitution
Oct 31, 2022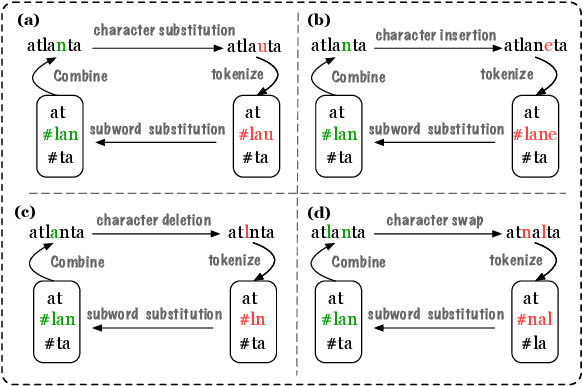
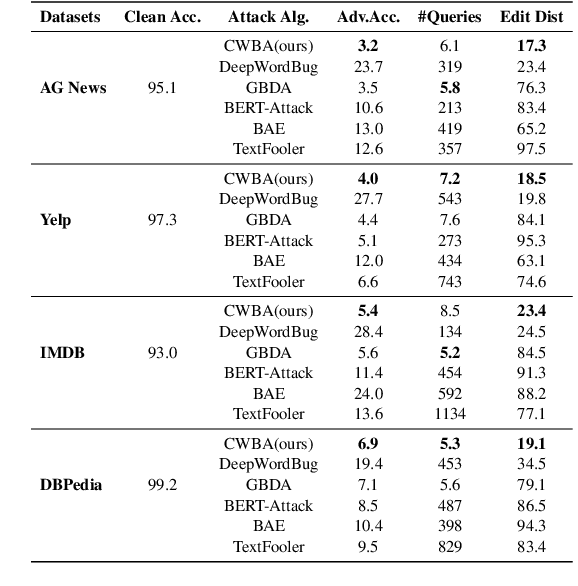
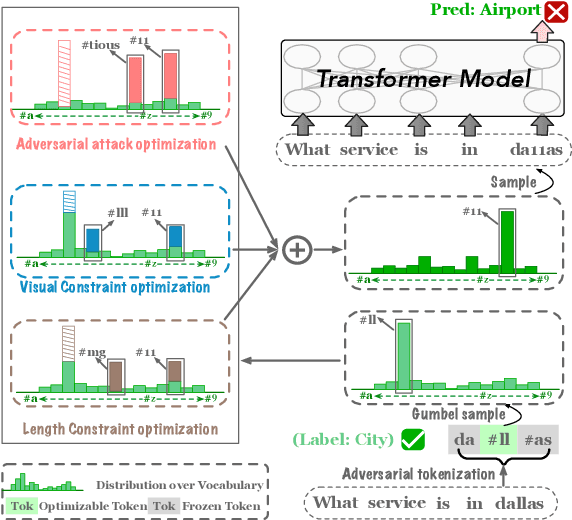
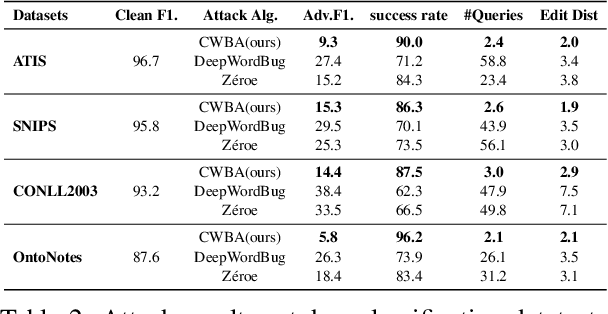
We propose the first character-level white-box adversarial attack method against transformer models. The intuition of our method comes from the observation that words are split into subtokens before being fed into the transformer models and the substitution between two close subtokens has a similar effect to the character modification. Our method mainly contains three steps. First, a gradient-based method is adopted to find the most vulnerable words in the sentence. Then we split the selected words into subtokens to replace the origin tokenization result from the transformer tokenizer. Finally, we utilize an adversarial loss to guide the substitution of attachable subtokens in which the Gumbel-softmax trick is introduced to ensure gradient propagation. Meanwhile, we introduce the visual and length constraint in the optimization process to achieve minimum character modifications. Extensive experiments on both sentence-level and token-level tasks demonstrate that our method could outperform the previous attack methods in terms of success rate and edit distance. Furthermore, human evaluation verifies our adversarial examples could preserve their origin labels.
* 13 pages, 3 figures. EMNLP 2022
Gradient Imitation Reinforcement Learning for Low Resource Relation Extraction
Sep 14, 2021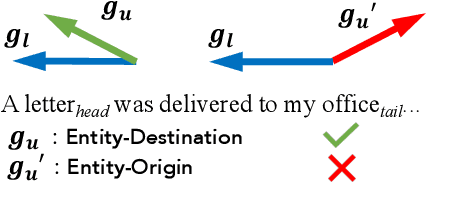
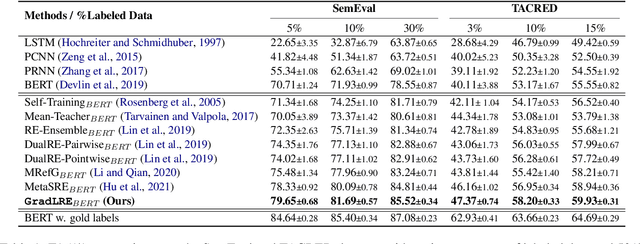
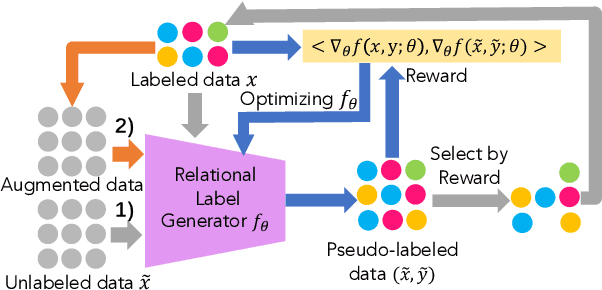

Low-resource Relation Extraction (LRE) aims to extract relation facts from limited labeled corpora when human annotation is scarce. Existing works either utilize self-training scheme to generate pseudo labels that will cause the gradual drift problem, or leverage meta-learning scheme which does not solicit feedback explicitly. To alleviate selection bias due to the lack of feedback loops in existing LRE learning paradigms, we developed a Gradient Imitation Reinforcement Learning method to encourage pseudo label data to imitate the gradient descent direction on labeled data and bootstrap its optimization capability through trial and error. We also propose a framework called GradLRE, which handles two major scenarios in low-resource relation extraction. Besides the scenario where unlabeled data is sufficient, GradLRE handles the situation where no unlabeled data is available, by exploiting a contextualized augmentation method to generate data. Experimental results on two public datasets demonstrate the effectiveness of GradLRE on low resource relation extraction when comparing with baselines.