 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCFE: A User-Centric Financial Expertise Benchmark for Large Language Models
Oct 22, 2024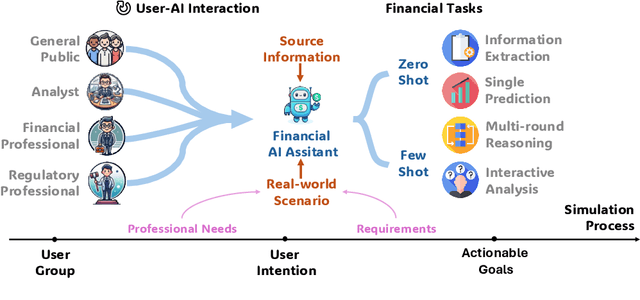
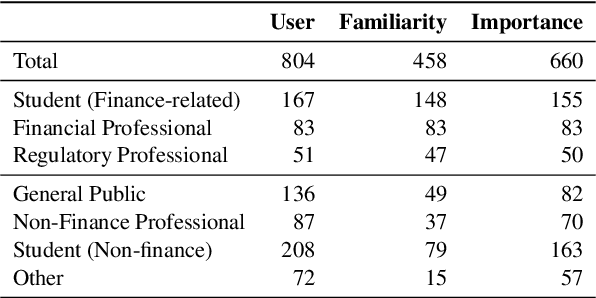
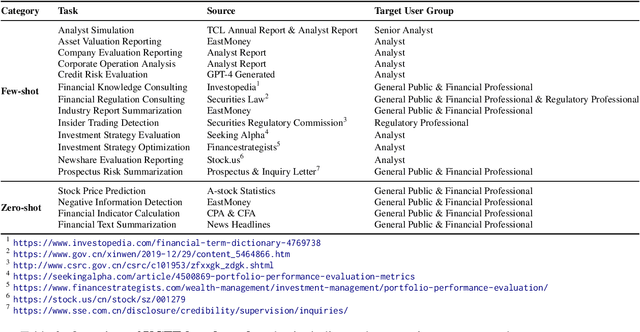
This paper introduces the UCFE: User-Centric Financial Expertise benchmark, an innovative framework designed to evaluate the ability of large language models (LLMs) to handle complex real-world financial tasks. UCFE benchmark adopts a hybrid approach that combines human expert evaluations with dynamic, task-specific interactions to simulate the complexities of evolving financial scenarios. Firstly, we conducted a user study involving 804 participants, collecting their feedback on financial tasks. Secondly, based on this feedback, we created our dataset that encompasses a wide range of user intents and interactions. This dataset serves as the foundation for benchmarking 12 LLM services using the LLM-as-Judge methodology. Our results show a significant alignment between benchmark scores and human preferences, with a Pearson correlation coefficient of 0.78, confirming the effectiveness of the UCFE dataset and our evaluation approach. UCFE benchmark not only reveals the potential of LLMs in the financial sector but also provides a robust framework for assessing their performance and user satisfaction. The benchmark dataset and evaluation code are available.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
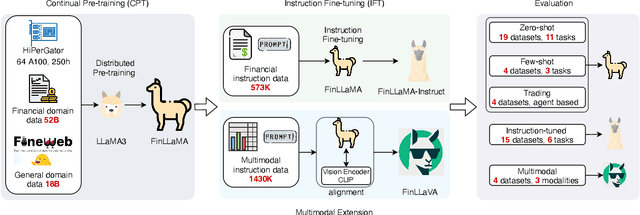
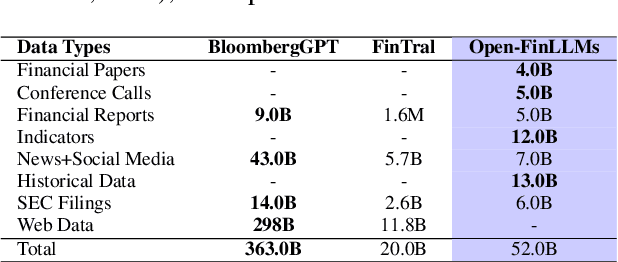
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
Character-level White-Box Adversarial Attacks against Transformers via Attachable Subwords Substitution
Oct 31, 2022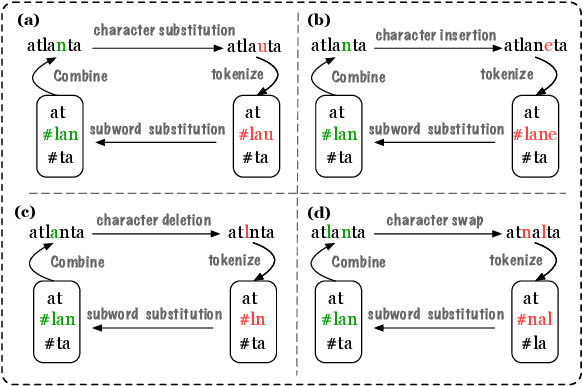
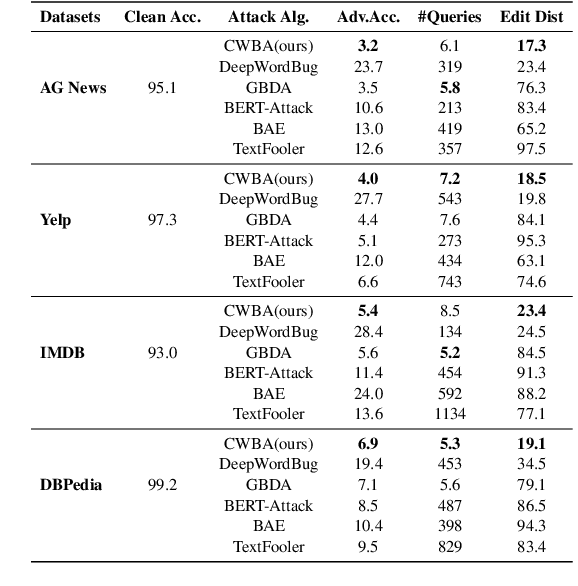
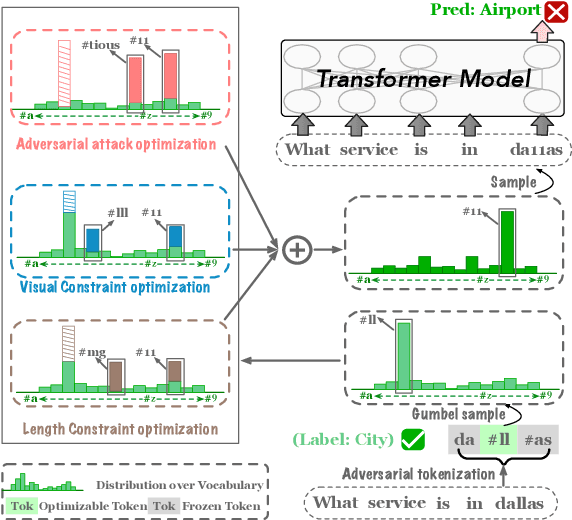
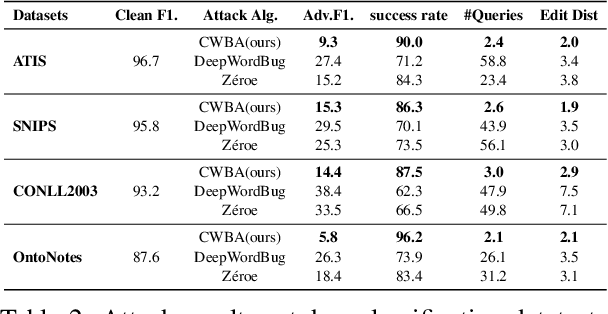
We propose the first character-level white-box adversarial attack method against transformer models. The intuition of our method comes from the observation that words are split into subtokens before being fed into the transformer models and the substitution between two close subtokens has a similar effect to the character modification. Our method mainly contains three steps. First, a gradient-based method is adopted to find the most vulnerable words in the sentence. Then we split the selected words into subtokens to replace the origin tokenization result from the transformer tokenizer. Finally, we utilize an adversarial loss to guide the substitution of attachable subtokens in which the Gumbel-softmax trick is introduced to ensure gradient propagation. Meanwhile, we introduce the visual and length constraint in the optimization process to achieve minimum character modifications. Extensive experiments on both sentence-level and token-level tasks demonstrate that our method could outperform the previous attack methods in terms of success rate and edit distance. Furthermore, human evaluation verifies our adversarial examples could preserve their origin labels.
* 13 pages, 3 figures. EMNLP 2022
Variable-Length Hashing
Mar 17, 2016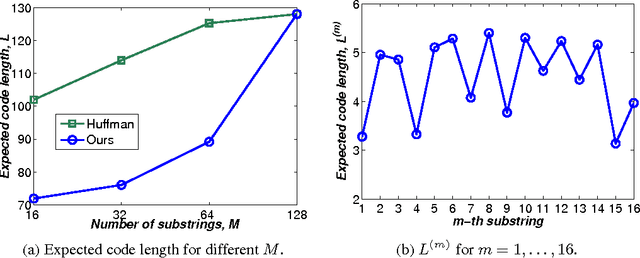



Hashing has emerged as a popular technique for large-scale similarity search. Most learning-based hashing methods generate compact yet correlated hash codes. However, this redundancy is storage-inefficient. Hence we propose a lossless variable-length hashing (VLH) method that is both storage- and search-efficient. Storage efficiency is achieved by converting the fixed-length hash code into a variable-length code. Search efficiency is obtained by using a multiple hash table structure. With VLH, we are able to deliberately add redundancy into hash codes to improve retrieval performance with little sacrifice in storage efficiency or search complexity. In particular, we propose a block K-means hashing (B-KMH) method to obtain significantly improved retrieval performance with no increase in storage and marginal increase in computational cost.