 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegime-aware financial volatility forecasting via in-context learning
Mar 11, 2026This work introduces a regime-aware in-context learning framework that leverages large language models (LLMs) for financial volatility forecasting under nonstationary market conditions. The proposed approach deploys pretrained LLMs to reason over historical volatility patterns and adjust their predictions without parameter fine-tuning. We develop an oracle-guided refinement procedure that constructs regime-aware demonstrations from training data. An LLM is then deployed as an in-context learner that predicts the next-step volatility from the input sequence using demonstrations sampled conditional to the estimated market label. This conditional sampling strategy enables the LLM to adapt its predictions to regime-dependent volatility dynamics through contextual reasoning alone. Experiments with multiple financial datasets show that the proposed regime-aware in-context learning framework outperforms both classical volatility forecasting approaches and direct one-shot learning, especially during high-volatility periods.
Distributed Quasi-Newton Method for Fair and Fast Federated Learning
Jan 18, 2025Federated learning (FL) is a promising technology that enables edge devices/clients to collaboratively and iteratively train a machine learning model under the coordination of a central server. The most common approach to FL is first-order methods, where clients send their local gradients to the server in each iteration. However, these methods often suffer from slow convergence rates. As a remedy, second-order methods, such as quasi-Newton, can be employed in FL to accelerate its convergence. Unfortunately, similarly to the first-order FL methods, the application of second-order methods in FL can lead to unfair models, achieving high average accuracy while performing poorly on certain clients' local datasets. To tackle this issue, in this paper we introduce a novel second-order FL framework, dubbed \textbf{d}istributed \textbf{q}uasi-\textbf{N}ewton \textbf{fed}erated learning (DQN-Fed). This approach seeks to ensure fairness while leveraging the fast convergence properties of quasi-Newton methods in the FL context. Specifically, DQN-Fed helps the server update the global model in such a way that (i) all local loss functions decrease to promote fairness, and (ii) the rate of change in local loss functions aligns with that of the quasi-Newton method. We prove the convergence of DQN-Fed and demonstrate its \textit{linear-quadratic} convergence rate. Moreover, we validate the efficacy of DQN-Fed across a range of federated datasets, showing that it surpasses state-of-the-art fair FL methods in fairness, average accuracy and convergence speed.
Over-the-Air Fair Federated Learning via Multi-Objective Optimization
Jan 06, 2025

In federated learning (FL), heterogeneity among the local dataset distributions of clients can result in unsatisfactory performance for some, leading to an unfair model. To address this challenge, we propose an over-the-air fair federated learning algorithm (OTA-FFL), which leverages over-the-air computation to train fair FL models. By formulating FL as a multi-objective minimization problem, we introduce a modified Chebyshev approach to compute adaptive weighting coefficients for gradient aggregation in each communication round. To enable efficient aggregation over the multiple access channel, we derive analytical solutions for the optimal transmit scalars at the clients and the de-noising scalar at the parameter server. Extensive experiments demonstrate the superiority of OTA-FFL in achieving fairness and robust performance compared to existing methods.
Enhancing Diffusion Models for Inverse Problems with Covariance-Aware Posterior Sampling
Dec 28, 2024



Inverse problems exist in many disciplines of science and engineering. In computer vision, for example, tasks such as inpainting, deblurring, and super resolution can be effectively modeled as inverse problems. Recently, denoising diffusion probabilistic models (DDPMs) are shown to provide a promising solution to noisy linear inverse problems without the need for additional task specific training. Specifically, with the prior provided by DDPMs, one can sample from the posterior by approximating the likelihood. In the literature, approximations of the likelihood are often based on the mean of conditional densities of the reverse process, which can be obtained using Tweedie formula. To obtain a better approximation to the likelihood, in this paper we first derive a closed form formula for the covariance of the reverse process. Then, we propose a method based on finite difference method to approximate this covariance such that it can be readily obtained from the existing pretrained DDPMs, thereby not increasing the complexity compared to existing approaches. Finally, based on the mean and approximated covariance of the reverse process, we present a new approximation to the likelihood. We refer to this method as covariance-aware diffusion posterior sampling (CA-DPS). Experimental results show that CA-DPS significantly improves reconstruction performance without requiring hyperparameter tuning. The code for the paper is put in the supplementary materials.
GP-FL: Model-Based Hessian Estimation for Second-Order Over-the-Air Federated Learning
Dec 05, 2024Second-order methods are widely adopted to improve the convergence rate of learning algorithms. In federated learning (FL), these methods require the clients to share their local Hessian matrices with the parameter server (PS), which comes at a prohibitive communication cost. A classical solution to this issue is to approximate the global Hessian matrix from the first-order information. Unlike in idealized networks, this solution does not perform effectively in over-the-air FL settings, where the PS receives noisy versions of the local gradients. This paper introduces a novel second-order FL framework tailored for wireless channels. The pivotal innovation lies in the PS's capability to directly estimate the global Hessian matrix from the received noisy local gradients via a non-parametric method: the PS models the unknown Hessian matrix as a Gaussian process, and then uses the temporal relation between the gradients and Hessian along with the channel model to find a stochastic estimator for the global Hessian matrix. We refer to this method as Gaussian process-based Hessian modeling for wireless FL (GP-FL) and show that it exhibits a linear-quadratic convergence rate. Numerical experiments on various datasets demonstrate that GP-FL outperforms all classical baseline first and second order FL approaches.
Rate-Constrained Quantization for Communication-Efficient Federated Learning
Sep 10, 2024Quantization is a common approach to mitigate the communication cost of federated learning (FL). In practice, the quantized local parameters are further encoded via an entropy coding technique, such as Huffman coding, for efficient data compression. In this case, the exact communication overhead is determined by the bit rate of the encoded gradients. Recognizing this fact, this work deviates from the existing approaches in the literature and develops a novel quantized FL framework, called \textbf{r}ate-\textbf{c}onstrained \textbf{fed}erated learning (RC-FED), in which the gradients are quantized subject to both fidelity and data rate constraints. We formulate this scheme, as a joint optimization in which the quantization distortion is minimized while the rate of encoded gradients is kept below a target threshold. This enables for a tunable trade-off between quantization distortion and communication cost. We analyze the convergence behavior of RC-FED, and show its superior performance against baseline quantized FL schemes on several datasets.
How to Train the Teacher Model for Effective Knowledge Distillation
Jul 25, 2024Recently, it was shown that the role of the teacher in knowledge distillation (KD) is to provide the student with an estimate of the true Bayes conditional probability density (BCPD). Notably, the new findings propose that the student's error rate can be upper-bounded by the mean squared error (MSE) between the teacher's output and BCPD. Consequently, to enhance KD efficacy, the teacher should be trained such that its output is close to BCPD in MSE sense. This paper elucidates that training the teacher model with MSE loss equates to minimizing the MSE between its output and BCPD, aligning with its core responsibility of providing the student with a BCPD estimate closely resembling it in MSE terms. In this respect, through a comprehensive set of experiments, we demonstrate that substituting the conventional teacher trained with cross-entropy loss with one trained using MSE loss in state-of-the-art KD methods consistently boosts the student's accuracy, resulting in improvements of up to 2.6\%.
Adversarial Training via Adaptive Knowledge Amalgamation of an Ensemble of Teachers
May 22, 2024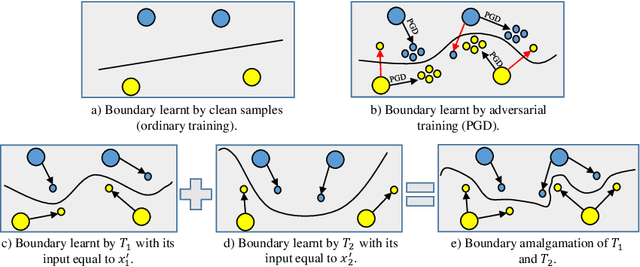

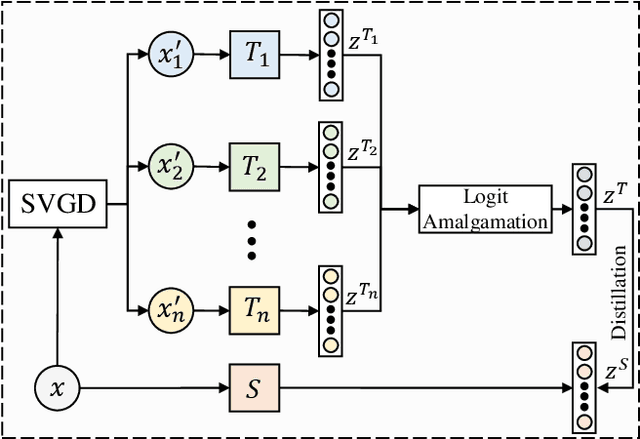
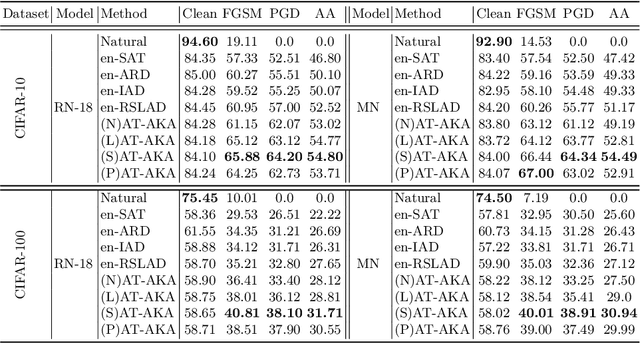
Adversarial training (AT) is a popular method for training robust deep neural networks (DNNs) against adversarial attacks. Yet, AT suffers from two shortcomings: (i) the robustness of DNNs trained by AT is highly intertwined with the size of the DNNs, posing challenges in achieving robustness in smaller models; and (ii) the adversarial samples employed during the AT process exhibit poor generalization, leaving DNNs vulnerable to unforeseen attack types. To address these dual challenges, this paper introduces adversarial training via adaptive knowledge amalgamation of an ensemble of teachers (AT-AKA). In particular, we generate a diverse set of adversarial samples as the inputs to an ensemble of teachers; and then, we adaptively amalgamate the logtis of these teachers to train a generalized-robust student. Through comprehensive experiments, we illustrate the superior efficacy of AT-AKA over existing AT methods and adversarial robustness distillation techniques against cutting-edge attacks, including AutoAttack.
Robustness Against Adversarial Attacks via Learning Confined Adversarial Polytopes
Jan 20, 2024Deep neural networks (DNNs) could be deceived by generating human-imperceptible perturbations of clean samples. Therefore, enhancing the robustness of DNNs against adversarial attacks is a crucial task. In this paper, we aim to train robust DNNs by limiting the set of outputs reachable via a norm-bounded perturbation added to a clean sample. We refer to this set as adversarial polytope, and each clean sample has a respective adversarial polytope. Indeed, if the respective polytopes for all the samples are compact such that they do not intersect the decision boundaries of the DNN, then the DNN is robust against adversarial samples. Hence, the inner-working of our algorithm is based on learning \textbf{c}onfined \textbf{a}dversarial \textbf{p}olytopes (CAP). By conducting a thorough set of experiments, we demonstrate the effectiveness of CAP over existing adversarial robustness methods in improving the robustness of models against state-of-the-art attacks including AutoAttack.
Bayes Conditional Distribution Estimation for Knowledge Distillation Based on Conditional Mutual Information
Jan 16, 2024It is believed that in knowledge distillation (KD), the role of the teacher is to provide an estimate for the unknown Bayes conditional probability distribution (BCPD) to be used in the student training process. Conventionally, this estimate is obtained by training the teacher using maximum log-likelihood (MLL) method. To improve this estimate for KD, in this paper we introduce the concept of conditional mutual information (CMI) into the estimation of BCPD and propose a novel estimator called the maximum CMI (MCMI) method. Specifically, in MCMI estimation, both the log-likelihood and CMI of the teacher are simultaneously maximized when the teacher is trained. Through Eigen-CAM, it is further shown that maximizing the teacher's CMI value allows the teacher to capture more contextual information in an image cluster. Via conducting a thorough set of experiments, we show that by employing a teacher trained via MCMI estimation rather than one trained via MLL estimation in various state-of-the-art KD frameworks, the student's classification accuracy consistently increases, with the gain of up to 3.32\%. This suggests that the teacher's BCPD estimate provided by MCMI method is more accurate than that provided by MLL method. In addition, we show that such improvements in the student's accuracy are more drastic in zero-shot and few-shot settings. Notably, the student's accuracy increases with the gain of up to 5.72\% when 5\% of the training samples are available to the student (few-shot), and increases from 0\% to as high as 84\% for an omitted class (zero-shot). The code is available at \url{https://github.com/iclr2024mcmi/ICLRMCMI}.