 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegime-aware financial volatility forecasting via in-context learning
Mar 11, 2026This work introduces a regime-aware in-context learning framework that leverages large language models (LLMs) for financial volatility forecasting under nonstationary market conditions. The proposed approach deploys pretrained LLMs to reason over historical volatility patterns and adjust their predictions without parameter fine-tuning. We develop an oracle-guided refinement procedure that constructs regime-aware demonstrations from training data. An LLM is then deployed as an in-context learner that predicts the next-step volatility from the input sequence using demonstrations sampled conditional to the estimated market label. This conditional sampling strategy enables the LLM to adapt its predictions to regime-dependent volatility dynamics through contextual reasoning alone. Experiments with multiple financial datasets show that the proposed regime-aware in-context learning framework outperforms both classical volatility forecasting approaches and direct one-shot learning, especially during high-volatility periods.
IRIS: Learning-Driven Task-Specific Cinema Robot Arm for Visuomotor Motion Control
Feb 19, 2026Robotic camera systems enable dynamic, repeatable motion beyond human capabilities, yet their adoption remains limited by the high cost and operational complexity of industrial-grade platforms. We present the Intelligent Robotic Imaging System (IRIS), a task-specific 6-DOF manipulator designed for autonomous, learning-driven cinematic motion control. IRIS integrates a lightweight, fully 3D-printed hardware design with a goal-conditioned visuomotor imitation learning framework based on Action Chunking with Transformers (ACT). The system learns object-aware and perceptually smooth camera trajectories directly from human demonstrations, eliminating the need for explicit geometric programming. The complete platform costs under $1,000 USD, supports a 1.5 kg payload, and achieves approximately 1 mm repeatability. Real-world experiments demonstrate accurate trajectory tracking, reliable autonomous execution, and generalization across diverse cinematic motions.
Energy-Efficient Over-the-Air Federated Learning via Pinching Antenna Systems
Feb 15, 2026Pinching antennas systems (PASSs) have recently been proposed as a novel flexible-antenna technology. These systems are implemented by attaching low-cost pinching elements to dielectric waveguides. As the direct link is bypassed through waveguides, PASSs can effectively compensate large-scale effects of the wireless channel. This work explores the potential gains of employing PASSs for over-the-air federated learning (OTA-FL). For a PASS-assisted server, we develop a low-complexity algorithmic approach, which jointly tunes the PASS parameters and schedules the mobile devices for minimal energy consumption in OTA-FL. We study the efficiency of the proposed design and compare it against the conventional OTA-FL setting with MIMO server. Numerical experiments demonstrate that using a single-waveguide PASS at the server within a moderately sized area, the required energy for model aggregation is drastically reduced as compared to the case with fully-digital MIMO server. This introduces PASS as a potential technology for energy-efficient distributed learning in next generations of wireless systems.
Dynamic and Static Energy Efficient Design of Pinching Antenna Systems
Nov 11, 2025We study the energy efficiency of pinching-antenna systems (PASSs) by developing a consistent formulation for power distribution in these systems. The per-antenna power distribution in PASSs is not controlled explicitly by a power allocation policy, but rather implicitly through tuning of pinching couplings and locations. Both these factors are tunable: (i) pinching locations are tuned using movable elements, and (ii) couplings can be tuned by varying the effective coupling length of the pinching elements. While the former is feasible to be addressed dynamically in settings with low user mobility, the latter cannot be addressed at a high rate. We thus develop a class of hybrid dynamic-static algorithms, which maximize the energy efficiency by updating the system parameters at different rates. Our experimental results depict that dynamic tuning of pinching locations can significantly boost energy efficiency of PASSs.
Coding for Computation: Efficient Compression of Neural Networks for Reconfigurable Hardware
Apr 24, 2025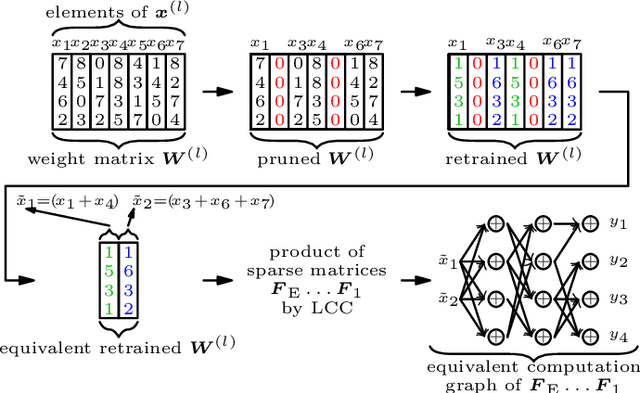
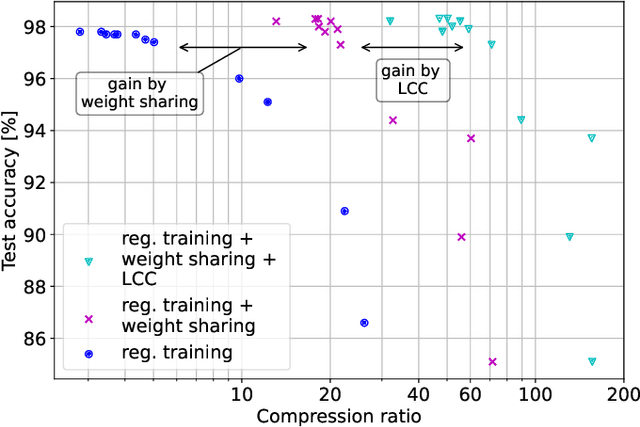
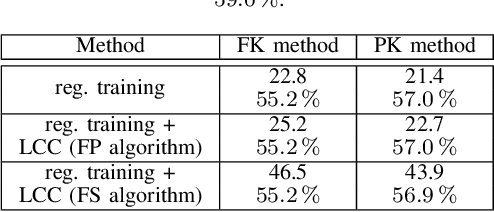
As state of the art neural networks (NNs) continue to grow in size, their resource-efficient implementation becomes ever more important. In this paper, we introduce a compression scheme that reduces the number of computations required for NN inference on reconfigurable hardware such as FPGAs. This is achieved by combining pruning via regularized training, weight sharing and linear computation coding (LCC). Contrary to common NN compression techniques, where the objective is to reduce the memory used for storing the weights of the NNs, our approach is optimized to reduce the number of additions required for inference in a hardware-friendly manner. The proposed scheme achieves competitive performance for simple multilayer perceptrons, as well as for large scale deep NNs such as ResNet-34.
MIMO-PASS: Uplink and Downlink Transmission via MIMO Pinching-Antenna Systems
Mar 05, 2025Pinching-antenna systems (PASSs) are a recent flexible-antenna technology that is realized by attaching simple components, referred to as pinching elements, to dielectric waveguides. This work explores the potential of deploying PASS for uplink and downlink transmission in multiuser MIMO settings. For downlink PASS-aided communication, we formulate the optimal hybrid beamforming, in which the digital precoding matrix at the access point and the location of pinching elements on the waveguides are jointly optimized to maximize the achievable weighted sum-rate. Invoking fractional programming and Gauss-Seidel approach, we propose two low-complexity algorithms to iteratively update the precoding matrix and activated locations of the pinching elements. We further study uplink transmission aided by a PASS, where an iterative scheme is designed to address the underlying hybrid multiuser detection problem. We validate the proposed schemes through extensive numerical experiments. The results demonstrate that using a PASS, the throughput in both uplink and downlink is boosted significantly as compared with baseline MIMO architectures, such as massive MIMO~and classical hybrid analog-digital designs. This highlights the great potential of PASSs, making it a promising reconfigurable antenna technology for next-generation wireless systems.
Downlink Beamforming with Pinching-Antenna Assisted MIMO Systems
Feb 03, 2025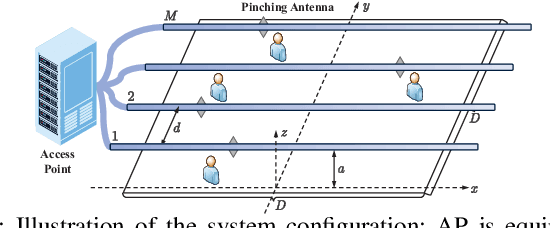
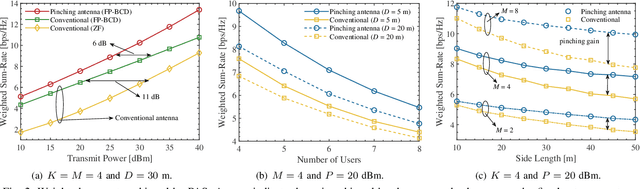
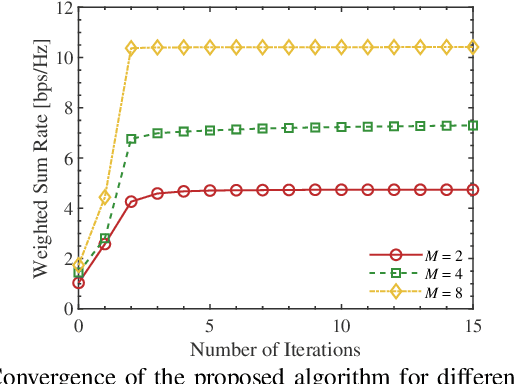
Pinching antennas have been recently proposed as a promising flexible-antenna technology, which can be implemented by attaching low-cost pinching elements to dielectric waveguides. This work explores the potential of employing pinching antenna systems (PASs) for downlink transmission in a multiuser MIMO setting. We consider the problem of hybrid beamforming, where the digital precoder at the access point and the activated locations of the pinching elements are jointly optimized to maximize the achievable weighted sum-rate. Invoking fractional programming, a novel low-complexity algorithm is developed to iteratively update the precoding matrix and the locations of the pinching antennas. We validate the proposed scheme through extensive numerical experiments. Our investigations demonstrate that using PAS the system throughput can be significantly boosted as compared with the conventional fixed-location antenna systems, enlightening the potential of PAS as an enabling candidate for next-generation wireless networks.
Universal Training of Neural Networks to Achieve Bayes Optimal Classification Accuracy
Jan 13, 2025


This work invokes the notion of $f$-divergence to introduce a novel upper bound on the Bayes error rate of a general classification task. We show that the proposed bound can be computed by sampling from the output of a parameterized model. Using this practical interpretation, we introduce the Bayes optimal learning threshold (BOLT) loss whose minimization enforces a classification model to achieve the Bayes error rate. We validate the proposed loss for image and text classification tasks, considering MNIST, Fashion-MNIST, CIFAR-10, and IMDb datasets. Numerical experiments demonstrate that models trained with BOLT achieve performance on par with or exceeding that of cross-entropy, particularly on challenging datasets. This highlights the potential of BOLT in improving generalization.
Regularized Top-$k$: A Bayesian Framework for Gradient Sparsification
Jan 10, 2025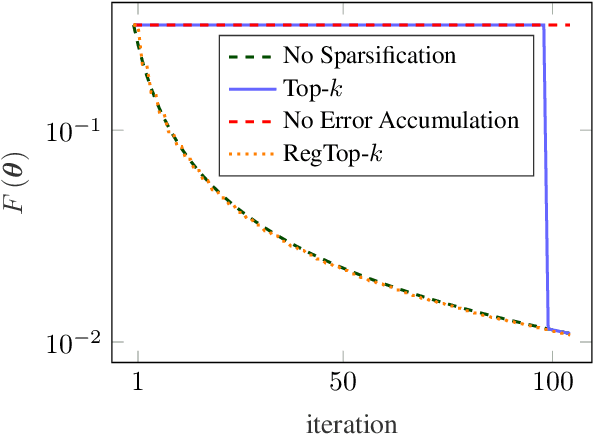
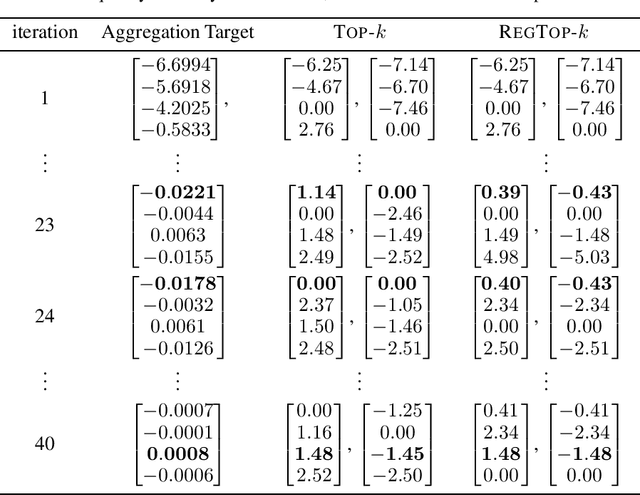
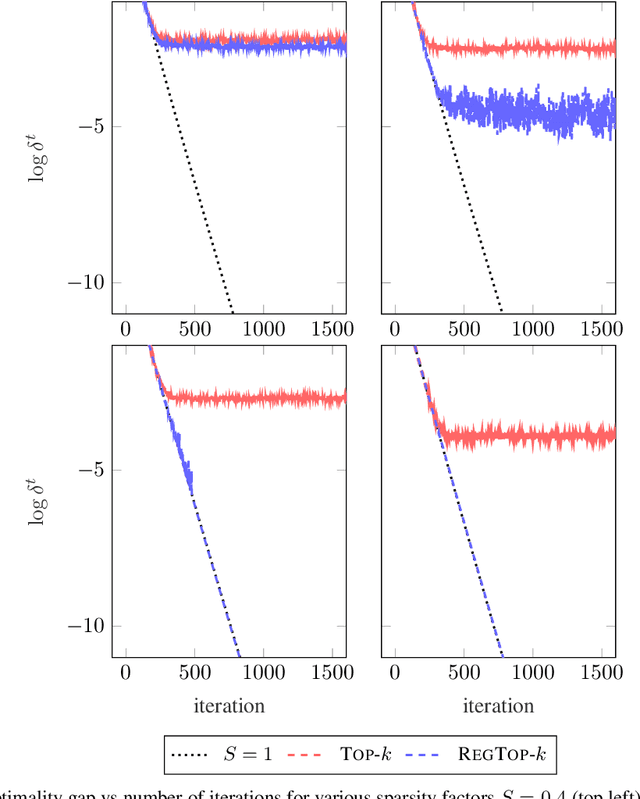
Error accumulation is effective for gradient sparsification in distributed settings: initially-unselected gradient entries are eventually selected as their accumulated error exceeds a certain level. The accumulation essentially behaves as a scaling of the learning rate for the selected entries. Although this property prevents the slow-down of lateral movements in distributed gradient descent, it can deteriorate convergence in some settings. This work proposes a novel sparsification scheme that controls the learning rate scaling of error accumulation. The development of this scheme follows two major steps: first, gradient sparsification is formulated as an inverse probability (inference) problem, and the Bayesian optimal sparsification mask is derived as a maximum-a-posteriori estimator. Using the prior distribution inherited from Top-$k$, we derive a new sparsification algorithm which can be interpreted as a regularized form of Top-$k$. We call this algorithm regularized Top-$k$ (RegTop-$k$). It utilizes past aggregated gradients to evaluate posterior statistics of the next aggregation. It then prioritizes the local accumulated gradient entries based on these posterior statistics. We validate our derivation through numerical experiments. In distributed linear regression, it is observed that while Top-$k$ remains at a fixed distance from the global optimum, RegTop-$k$ converges to the global optimum at significantly higher compression ratios. We further demonstrate the generalization of this observation by employing RegTop-$k$ in distributed training of ResNet-18 on CIFAR-10, where it noticeably outperforms Top-$k$.
Over-the-Air Fair Federated Learning via Multi-Objective Optimization
Jan 06, 2025

In federated learning (FL), heterogeneity among the local dataset distributions of clients can result in unsatisfactory performance for some, leading to an unfair model. To address this challenge, we propose an over-the-air fair federated learning algorithm (OTA-FFL), which leverages over-the-air computation to train fair FL models. By formulating FL as a multi-objective minimization problem, we introduce a modified Chebyshev approach to compute adaptive weighting coefficients for gradient aggregation in each communication round. To enable efficient aggregation over the multiple access channel, we derive analytical solutions for the optimal transmit scalars at the clients and the de-noising scalar at the parameter server. Extensive experiments demonstrate the superiority of OTA-FFL in achieving fairness and robust performance compared to existing methods.