 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegOTA: Accelerating Over-the-Air Federated Learning with Segmented Transmission
Apr 13, 2025Federated learning (FL) with over-the-air computation efficiently utilizes the communication resources, but it can still experience significant latency when each device transmits a large number of model parameters to the server. This paper proposes the Segmented Over-The-Air (SegOTA) method for FL, which reduces latency by partitioning devices into groups and letting each group transmit only one segment of the model parameters in each communication round. Considering a multi-antenna server, we model the SegOTA transmission and reception process to establish an upper bound on the expected model learning optimality gap. We minimize this upper bound, by formulating the per-round online optimization of device grouping and joint transmit-receive beamforming, for which we derive efficient closed-form solutions. Simulation results show that our proposed SegOTA substantially outperforms the conventional full-model OTA approach and other common alternatives.
Improving Wireless Federated Learning via Joint Downlink-Uplink Beamforming over Analog Transmission
Feb 04, 2025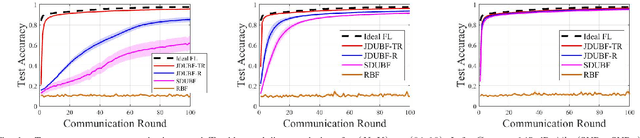
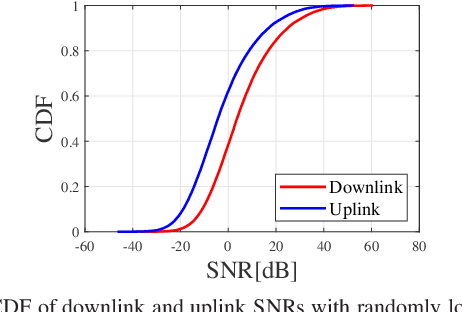
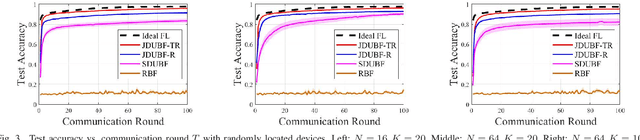
Federated learning (FL) over wireless networks using analog transmission can efficiently utilize the communication resource but is susceptible to errors caused by noisy wireless links. In this paper, assuming a multi-antenna base station, we jointly design downlink-uplink beamforming to maximize FL training convergence over time-varying wireless channels. We derive the round-trip model updating equation and use it to analyze the FL training convergence to capture the effects of downlink and uplink beamforming and the local model training on the global model update. Aiming to maximize the FL training convergence rate, we propose a low-complexity joint downlink-uplink beamforming (JDUBF) algorithm, which adopts a greedy approach to decompose the multi-round joint optimization and convert it into per-round online joint optimization problems. The per-round problem is further decomposed into three subproblems over a block coordinate descent framework, where we show that each subproblem can be efficiently solved by projected gradient descent with fast closed-form updates. An efficient initialization method that leads to a closed-form initial point is also proposed to accelerate the convergence of JDUBF. Simulation demonstrates that JDUBF substantially outperforms the conventional separate-link beamforming design.
Power-Efficient Over-the-Air Aggregation with Receive Beamforming for Federated Learning
Jan 29, 2025



This paper studies power-efficient uplink transmission design for federated learning (FL) that employs over-the-air analog aggregation and multi-antenna beamforming at the server. We jointly optimize device transmit weights and receive beamforming at each FL communication round to minimize the total device transmit power while ensuring convergence in FL training. Through our convergence analysis, we establish sufficient conditions on the aggregation error to guarantee FL training convergence. Utilizing these conditions, we reformulate the power minimization problem into a unique bi-convex structure that contains a transmit beamforming optimization subproblem and a receive beamforming feasibility subproblem. Despite this unconventional structure, we propose a novel alternating optimization approach that guarantees monotonic decrease of the objective value, to allow convergence to a partial optimum. We further consider imperfect channel state information (CSI), which requires accounting for the channel estimation errors in the power minimization problem and FL convergence analysis. We propose a CSI-error-aware joint beamforming algorithm, which can substantially outperform one that does not account for channel estimation errors. Simulation with canonical classification datasets demonstrates that our proposed methods achieve significant power reduction compared to existing benchmarks across a wide range of parameter settings, while attaining the same target accuracy under the same convergence rate.
Universal Training of Neural Networks to Achieve Bayes Optimal Classification Accuracy
Jan 13, 2025


This work invokes the notion of $f$-divergence to introduce a novel upper bound on the Bayes error rate of a general classification task. We show that the proposed bound can be computed by sampling from the output of a parameterized model. Using this practical interpretation, we introduce the Bayes optimal learning threshold (BOLT) loss whose minimization enforces a classification model to achieve the Bayes error rate. We validate the proposed loss for image and text classification tasks, considering MNIST, Fashion-MNIST, CIFAR-10, and IMDb datasets. Numerical experiments demonstrate that models trained with BOLT achieve performance on par with or exceeding that of cross-entropy, particularly on challenging datasets. This highlights the potential of BOLT in improving generalization.
Regularized Top-$k$: A Bayesian Framework for Gradient Sparsification
Jan 10, 2025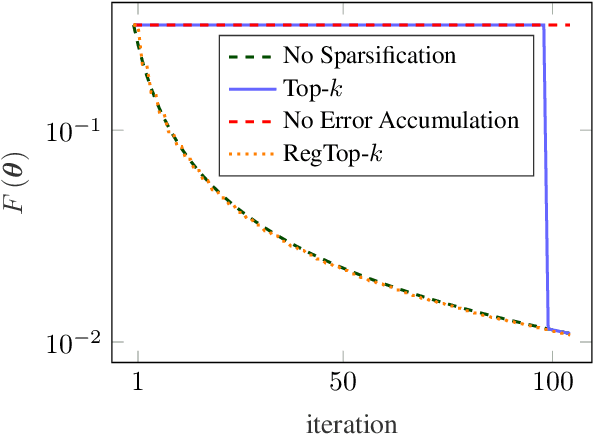
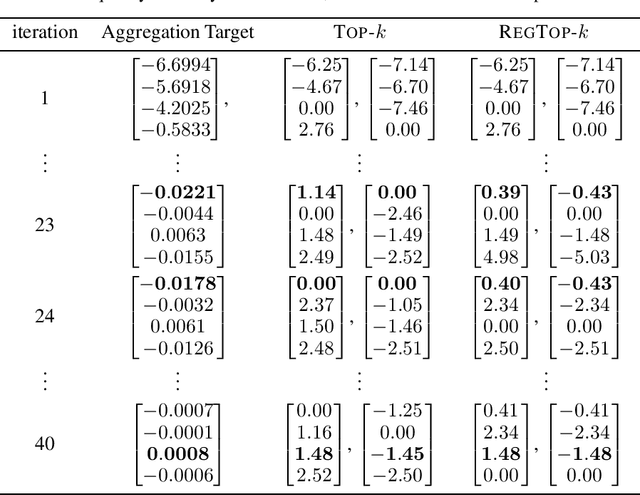
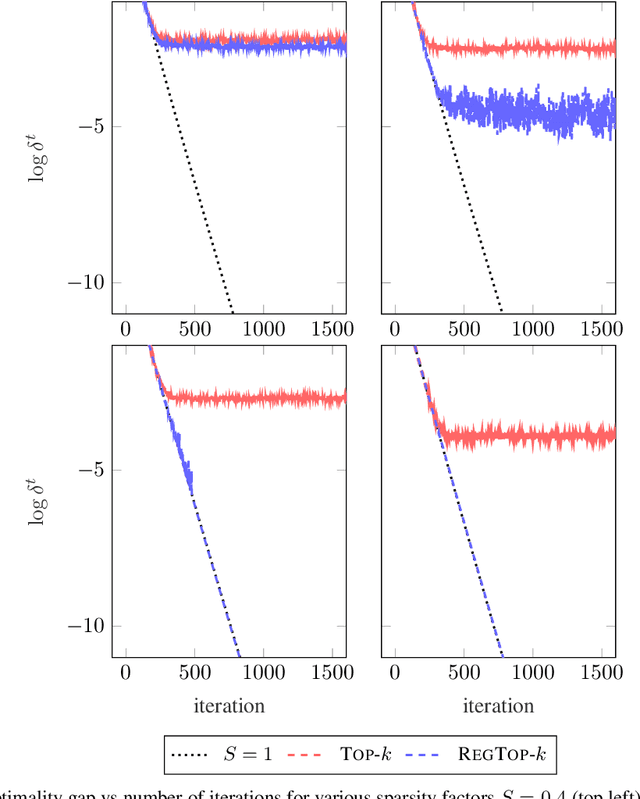
Error accumulation is effective for gradient sparsification in distributed settings: initially-unselected gradient entries are eventually selected as their accumulated error exceeds a certain level. The accumulation essentially behaves as a scaling of the learning rate for the selected entries. Although this property prevents the slow-down of lateral movements in distributed gradient descent, it can deteriorate convergence in some settings. This work proposes a novel sparsification scheme that controls the learning rate scaling of error accumulation. The development of this scheme follows two major steps: first, gradient sparsification is formulated as an inverse probability (inference) problem, and the Bayesian optimal sparsification mask is derived as a maximum-a-posteriori estimator. Using the prior distribution inherited from Top-$k$, we derive a new sparsification algorithm which can be interpreted as a regularized form of Top-$k$. We call this algorithm regularized Top-$k$ (RegTop-$k$). It utilizes past aggregated gradients to evaluate posterior statistics of the next aggregation. It then prioritizes the local accumulated gradient entries based on these posterior statistics. We validate our derivation through numerical experiments. In distributed linear regression, it is observed that while Top-$k$ remains at a fixed distance from the global optimum, RegTop-$k$ converges to the global optimum at significantly higher compression ratios. We further demonstrate the generalization of this observation by employing RegTop-$k$ in distributed training of ResNet-18 on CIFAR-10, where it noticeably outperforms Top-$k$.
Uplink Over-the-Air Aggregation for Multi-Model Wireless Federated Learning
Sep 02, 2024

We propose an uplink over-the-air aggregation (OAA) method for wireless federated learning (FL) that simultaneously trains multiple models. To maximize the multi-model training convergence rate, we derive an upper bound on the optimality gap of the global model update, and then, formulate an uplink joint transmit-receive beamforming optimization problem to minimize this upper bound. We solve this problem using the block coordinate descent approach, which admits low-complexity closed-form updates. Simulation results show that our proposed multi-model FL with fast OAA substantially outperforms sequentially training multiple models under the conventional single-model approach.
Joint Group Scheduling and Multicast Beamforming for Downlink Large-Scale Multi-Group Multicast
Mar 15, 2024



Next-generation wireless networks need to handle massive user access effectively. This paper addresses the problem of joint group scheduling and multicast beamforming for downlink multicast with many active groups. Aiming to maximize the minimum user throughput, we propose a three-phase approach to tackle this difficult joint optimization problem efficiently. In Phase 1, we utilize the optimal multicast beamforming structure obtained recently to find the group-channel directions for all groups. We propose two low-complexity scheduling algorithms in Phase 2, which determine the subset of groups in each time slot sequentially and the total number of time slots required for all groups. The first algorithm measures the level of spatial separation among groups and selects the dissimilar groups that maximize the minimum user rate into the same time slot. In contrast, the second algorithm first identifies the spatially correlated groups via a learning-based clustering method based on the group-channel directions, and then separates spatially similar groups into different time slots. Finally, the multicast beamformers for the scheduled groups are obtained in each time slot by a computationally efficient method. Simulation results show that our proposed approaches can effectively capture the level of spatial separation among groups for scheduling to improve the minimum user throughput over the conventional approach that serves all groups in a single time slot or one group per time slot, and can be executed with low computational complexity.
Multi-Model Wireless Federated Learning with Downlink Beamforming
Jan 15, 2024

This paper studies the design of wireless federated learning (FL) for simultaneously training multiple machine learning models. We consider round robin device-model assignment and downlink beamforming for concurrent multiple model updates. After formulating the joint downlink-uplink transmission process, we derive the per-model global update expression over communication rounds, capturing the effect of beamforming and noisy reception. To maximize the multi-model training convergence rate, we derive an upper bound on the optimality gap of the global model update and use it to formulate a multi-group multicast beamforming problem. We show that this problem can be converted to minimizing the sum of inverse received signal-to-interference-plus-noise ratios, which can be solved efficiently by projected gradient descent. Simulation shows that our proposed multi-model FL solution outperforms other alternatives, including conventional single-model sequential training and multi-model zero-forcing beamforming.
Improving Knowledge Distillation with Teacher's Explanation
Oct 04, 2023



Knowledge distillation (KD) improves the performance of a low-complexity student model with the help of a more powerful teacher. The teacher in KD is a black-box model, imparting knowledge to the student only through its predictions. This limits the amount of transferred knowledge. In this work, we introduce a novel Knowledge Explaining Distillation (KED) framework, which allows the student to learn not only from the teacher's predictions but also from the teacher's explanations. We propose a class of superfeature-explaining teachers that provide explanation over groups of features, along with the corresponding student model. We also present a method for constructing the superfeatures. We then extend KED to reduce complexity in convolutional neural networks, to allow augmentation with hidden-representation distillation methods, and to work with a limited amount of training data using chimeric sets. Our experiments over a variety of datasets show that KED students can substantially outperform KD students of similar complexity.
Generative Adversarial Classification Network with Application to Network Traffic Classification
Mar 19, 2023Large datasets in machine learning often contain missing data, which necessitates the imputation of missing data values. In this work, we are motivated by network traffic classification, where traditional data imputation methods do not perform well. We recognize that no existing method directly accounts for classification accuracy during data imputation. Therefore, we propose a joint data imputation and data classification method, termed generative adversarial classification network (GACN), whose architecture contains a generator network, a discriminator network, and a classification network, which are iteratively optimized toward the ultimate objective of classification accuracy. For the scenario where some data samples are unlabeled, we further propose an extension termed semi-supervised GACN (SSGACN), which is able to use the partially labeled data to improve classification accuracy. We conduct experiments with real-world network traffic data traces, which demonstrate that GACN and SS-GACN can more accurately impute data features that are more important for classification, and they outperform existing methods in terms of classification accuracy.
* 6 pages, 4 figures, 2 tables