 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Intermittent Job Failure Categories for Diagnosis Using Few-Shot Fine-Tuned Language Models
Jan 29, 2026In principle, Continuous Integration (CI) pipeline failures provide valuable feedback to developers on code-related errors. In practice, however, pipeline jobs often fail intermittently due to non-deterministic tests, network outages, infrastructure failures, resource exhaustion, and other reliability issues. These intermittent (flaky) job failures lead to substantial inefficiencies: wasted computational resources from repeated reruns and significant diagnosis time that distracts developers from core activities and often requires intervention from specialized teams. Prior work has proposed machine learning techniques to detect intermittent failures, but does not address the subsequent diagnosis challenge. To fill this gap, we introduce FlaXifyer, a few-shot learning approach for predicting intermittent job failure categories using pre-trained language models. FlaXifyer requires only job execution logs and achieves 84.3% Macro F1 and 92.0% Top-2 accuracy with just 12 labeled examples per category. We also propose LogSift, an interpretability technique that identifies influential log statements in under one second, reducing review effort by 74.4% while surfacing relevant failure information in 87% of cases. Evaluation on 2,458 job failures from TELUS demonstrates that FlaXifyer and LogSift enable effective automated triage, accelerate failure diagnosis, and pave the way towards the automated resolution of intermittent job failures.
On The Impact of Merge Request Deviations on Code Review Practices
Jun 11, 2025Code review is a key practice in software engineering, ensuring quality and collaboration. However, industrial Merge Request (MR) workflows often deviate from standardized review processes, with many MRs serving non-review purposes (e.g., drafts, rebases, or dependency updates). We term these cases deviations and hypothesize that ignoring them biases analytics and undermines ML models for review analysis. We identify seven deviation categories, occurring in 37.02% of MRs, and propose a few-shot learning detection method (91% accuracy). By excluding deviations, ML models predicting review completion time improve performance in 53.33% of cases (up to 2.25x) and exhibit significant shifts in feature importance (47% overall, 60% top-*k*). Our contributions include: (1) a taxonomy of MR deviations, (2) an AI-driven detection approach, and (3) empirical evidence of their impact on ML-based review analytics. This work aids practitioners in optimizing review efforts and ensuring reliable insights.
Towards Build Optimization Using Digital Twins
Mar 25, 2025Despite the indisputable benefits of Continuous Integration (CI) pipelines (or builds), CI still presents significant challenges regarding long durations, failures, and flakiness. Prior studies addressed CI challenges in isolation, yet these issues are interrelated and require a holistic approach for effective optimization. To bridge this gap, this paper proposes a novel idea of developing Digital Twins (DTs) of build processes to enable global and continuous improvement. To support such an idea, we introduce the CI Build process Digital Twin (CBDT) framework as a minimum viable product. This framework offers digital shadowing functionalities, including real-time build data acquisition and continuous monitoring of build process performance metrics. Furthermore, we discuss guidelines and challenges in the practical implementation of CBDTs, including (1) modeling different aspects of the build process using Machine Learning, (2) exploring what-if scenarios based on historical patterns, and (3) implementing prescriptive services such as automated failure and performance repair to continuously improve build processes.
Intent Assurance using LLMs guided by Intent Drift
Feb 02, 2024



Intent-Based Networking (IBN) presents a paradigm shift for network management, by promising to align intents and business objectives with network operations--in an automated manner. However, its practical realization is challenging: 1) processing intents, i.e., translate, decompose and identify the logic to fulfill the intent, and 2) intent conformance, that is, considering dynamic networks, the logic should be adequately adapted to assure intents. To address the latter, intent assurance is tasked with continuous verification and validation, including taking the necessary actions to align the operational and target states. In this paper, we define an assurance framework that allows us to detect and act when intent drift occurs. To do so, we leverage AI-driven policies, generated by Large Language Models (LLMs) which can quickly learn the necessary in-context requirements, and assist with the fulfillment and assurance of intents.
Improving Knowledge Distillation with Teacher's Explanation
Oct 04, 2023



Knowledge distillation (KD) improves the performance of a low-complexity student model with the help of a more powerful teacher. The teacher in KD is a black-box model, imparting knowledge to the student only through its predictions. This limits the amount of transferred knowledge. In this work, we introduce a novel Knowledge Explaining Distillation (KED) framework, which allows the student to learn not only from the teacher's predictions but also from the teacher's explanations. We propose a class of superfeature-explaining teachers that provide explanation over groups of features, along with the corresponding student model. We also present a method for constructing the superfeatures. We then extend KED to reduce complexity in convolutional neural networks, to allow augmentation with hidden-representation distillation methods, and to work with a limited amount of training data using chimeric sets. Our experiments over a variety of datasets show that KED students can substantially outperform KD students of similar complexity.
Generative Adversarial Classification Network with Application to Network Traffic Classification
Mar 19, 2023Large datasets in machine learning often contain missing data, which necessitates the imputation of missing data values. In this work, we are motivated by network traffic classification, where traditional data imputation methods do not perform well. We recognize that no existing method directly accounts for classification accuracy during data imputation. Therefore, we propose a joint data imputation and data classification method, termed generative adversarial classification network (GACN), whose architecture contains a generator network, a discriminator network, and a classification network, which are iteratively optimized toward the ultimate objective of classification accuracy. For the scenario where some data samples are unlabeled, we further propose an extension termed semi-supervised GACN (SSGACN), which is able to use the partially labeled data to improve classification accuracy. We conduct experiments with real-world network traffic data traces, which demonstrate that GACN and SS-GACN can more accurately impute data features that are more important for classification, and they outperform existing methods in terms of classification accuracy.
* 6 pages, 4 figures, 2 tables
Flow-Packet Hybrid Traffic Classification for Class-Aware Network Routing
Apr 30, 2021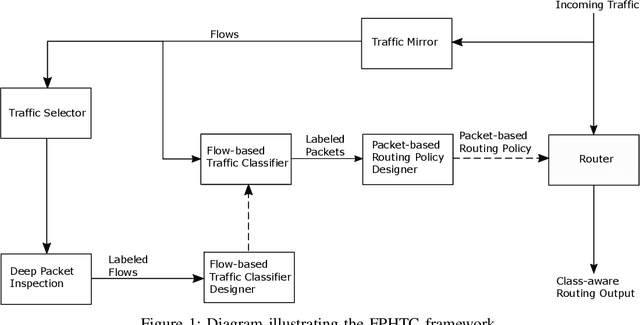

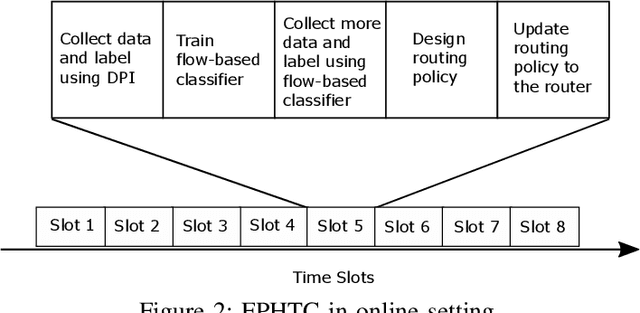
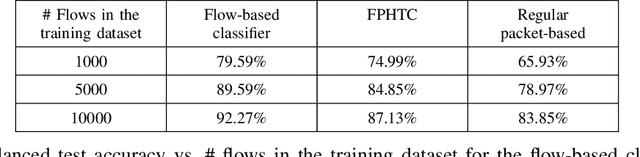
Network traffic classification using machine learning techniques has been widely studied. Most existing schemes classify entire traffic flows, but there are major limitations to their practicality. At a network router, the packets need to be processed with minimum delay, so the classifier cannot wait until the end of the flow to make a decision. Furthermore, a complicated machine learning algorithm can be too computationally expensive to implement inside the router. In this paper, we introduce flow-packet hybrid traffic classification (FPHTC), where the router makes a decision per packet based on a routing policy that is designed through transferring the learned knowledge from a flow-based classifier residing outside the router. We analyze the generalization bound of FPHTC and show its advantage over regular packet-based traffic classification. We present experimental results using a real-world traffic dataset to illustrate the classification performance of FPHTC. We show that it is robust toward traffic pattern changes and can be deployed with limited computational resource.
Queue-Learning: A Reinforcement Learning Approach for Providing Quality of Service
Jan 12, 2021
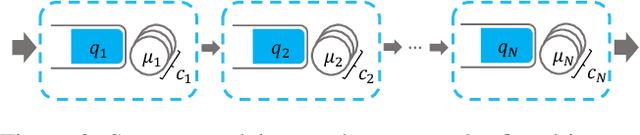


End-to-end delay is a critical attribute of quality of service (QoS) in application domains such as cloud computing and computer networks. This metric is particularly important in tandem service systems, where the end-to-end service is provided through a chain of services. Service-rate control is a common mechanism for providing QoS guarantees in service systems. In this paper, we introduce a reinforcement learning-based (RL-based) service-rate controller that provides probabilistic upper-bounds on the end-to-end delay of the system, while preventing the overuse of service resources. In order to have a general framework, we use queueing theory to model the service systems. However, we adopt an RL-based approach to avoid the limitations of queueing-theoretic methods. In particular, we use Deep Deterministic Policy Gradient (DDPG) to learn the service rates (action) as a function of the queue lengths (state) in tandem service systems. In contrast to existing RL-based methods that quantify their performance by the achieved overall reward, which could be hard to interpret or even misleading, our proposed controller provides explicit probabilistic guarantees on the end-to-end delay of the system. The evaluations are presented for a tandem queueing system with non-exponential inter-arrival and service times, the results of which validate our controller's capability in meeting QoS constraints.
Reinforcement Learning-based Admission Control in Delay-sensitive Service Systems
Aug 21, 2020



Ensuring quality of service (QoS) guarantees in service systems is a challenging task, particularly when the system is composed of more fine-grained services, such as service function chains. An important QoS metric in service systems is the end-to-end delay, which becomes even more important in delay-sensitive applications, where the jobs must be completed within a time deadline. Admission control is one way of providing end-to-end delay guarantee, where the controller accepts a job only if it has a high probability of meeting the deadline. In this paper, we propose a reinforcement learning-based admission controller that guarantees a probabilistic upper-bound on the end-to-end delay of the service system, while minimizes the probability of unnecessary rejections. Our controller only uses the queue length information of the network and requires no knowledge about the network topology or system parameters. Since long-term performance metrics are of great importance in service systems, we take an average-reward reinforcement learning approach, which is well suited to infinite horizon problems. Our evaluations verify that the proposed RL-based admission controller is capable of providing probabilistic bounds on the end-to-end delay of the network, without using system model information.