 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical and Machine Learning Models for Predicting Fire and Other Emergency Events
Feb 14, 2024Emergency events in a city cause considerable economic loss to individuals, their families, and the community. Accurate and timely prediction of events can help the emergency fire and rescue services in preparing for and mitigating the consequences of emergency events. In this paper, we present a systematic development of predictive models for various types of emergency events in the City of Edmonton, Canada. We present methods for (i) data collection and dataset development; (ii) descriptive analysis of each event type and its characteristics at different spatiotemporal levels; (iii) feature analysis and selection based on correlation coefficient analysis and feature importance analysis; and (iv) development of prediction models for the likelihood of occurrence of each event type at different temporal and spatial resolutions. We analyze the association of event types with socioeconomic and demographic data at the neighborhood level, identify a set of predictors for each event type, and develop predictive models with negative binomial regression. We conduct evaluations at neighborhood and fire station service area levels. Our results show that the models perform well for most of the event types with acceptable prediction errors for weekly and monthly periods. The evaluation shows that the prediction accuracy is consistent at the level of the fire station, so the predictions can be used in management by fire rescue service departments for planning resource allocation for these time periods. We also examine the impact of the COVID-19 pandemic on the occurrence of events and on the accuracy of event predictor models. Our findings show that COVID-19 had a significant impact on the performance of the event prediction models.
Intent Assurance using LLMs guided by Intent Drift
Feb 02, 2024



Intent-Based Networking (IBN) presents a paradigm shift for network management, by promising to align intents and business objectives with network operations--in an automated manner. However, its practical realization is challenging: 1) processing intents, i.e., translate, decompose and identify the logic to fulfill the intent, and 2) intent conformance, that is, considering dynamic networks, the logic should be adequately adapted to assure intents. To address the latter, intent assurance is tasked with continuous verification and validation, including taking the necessary actions to align the operational and target states. In this paper, we define an assurance framework that allows us to detect and act when intent drift occurs. To do so, we leverage AI-driven policies, generated by Large Language Models (LLMs) which can quickly learn the necessary in-context requirements, and assist with the fulfillment and assurance of intents.
Missing Data Estimation in Temporal Multilayer Position-aware Graph Neural Network (TMP-GNN)
Aug 07, 2021



GNNs have been proven to perform highly effective in various node-level, edge-level, and graph-level prediction tasks in several domains. Existing approaches mainly focus on static graphs. However, many graphs change over time with their edge may disappear, or node or edge attribute may alter from one time to the other. It is essential to consider such evolution in representation learning of nodes in time varying graphs. In this paper, we propose a Temporal Multilayered Position-aware Graph Neural Network (TMP-GNN), a node embedding approach for dynamic graph that incorporates the interdependence of temporal relations into embedding computation. We evaluate the performance of TMP-GNN on two different representations of temporal multilayered graphs. The performance is assessed against the most popular GNNs on node-level prediction tasks. Then, we incorporate TMP-GNN into a deep learning framework to estimate missing data and compare the performance with their corresponding competent GNNs from our former experiment, and a baseline method. Experimental results on four real-world datasets yield up to 58% of lower ROC AUC for pairwise node classification task, and 96% of lower MAE in missing feature estimation, particularly for graphs with a relatively high number of nodes and lower mean degree of connectivity.
A Deep Reinforcement Learning Approach for Fair Traffic Signal Control
Jul 21, 2021



Traffic signal control is one of the most effective methods of traffic management in urban areas. In recent years, traffic control methods based on deep reinforcement learning (DRL) have gained attention due to their ability to exploit real-time traffic data, which is often poorly used by the traditional hand-crafted methods. While most recent DRL-based methods have focused on maximizing the throughput or minimizing the average travel time of the vehicles, the fairness of the traffic signal controllers has often been neglected. This is particularly important as neglecting fairness can lead to situations where some vehicles experience extreme waiting times, or where the throughput of a particular traffic flow is highly impacted by the fluctuations of another conflicting flow at the intersection. In order to address these issues, we introduce two notions of fairness: delay-based and throughput-based fairness, which correspond to the two issues mentioned above. Furthermore, we propose two DRL-based traffic signal control methods for implementing these fairness notions, that can achieve a high throughput as well. We evaluate the performance of our proposed methods using three traffic arrival distributions, and find that our methods outperform the baselines in the tested scenarios.
Toward Efficient Transfer Learning in 6G
Jul 12, 2021



6G networks will greatly expand the support for data-oriented, autonomous applications for over the top (OTT) and networking use cases. The success of these use cases will depend on the availability of big data sets which is not practical in many real scenarios due to the highly dynamic behavior of systems and the cost of data collection procedures. Transfer learning (TL) is a promising approach to deal with these challenges through the sharing of knowledge among diverse learning algorithms. with TL, the learning rate and learning accuracy can be considerably improved. However, there are implementation challenges to efficiently deploy and utilize TL in 6G. In this paper, we initiate this discussion by providing some performance metrics to measure the TL success. Then, we show how infrastructure, application, management, and training planes of 6G can be adapted to handle TL. We provide examples of TL in 6G and highlight the spatio-temporal features of data in 6G that can lead to efficient TL. By simulation results, we demonstrate how transferring the quantized neural network weights between two use cases can make a trade-off between overheads and performance and attain more efficient TL in 6G. We also provide a list of future research directions in TL for 6G.
Queue-Learning: A Reinforcement Learning Approach for Providing Quality of Service
Jan 12, 2021
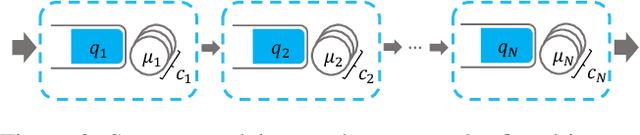


End-to-end delay is a critical attribute of quality of service (QoS) in application domains such as cloud computing and computer networks. This metric is particularly important in tandem service systems, where the end-to-end service is provided through a chain of services. Service-rate control is a common mechanism for providing QoS guarantees in service systems. In this paper, we introduce a reinforcement learning-based (RL-based) service-rate controller that provides probabilistic upper-bounds on the end-to-end delay of the system, while preventing the overuse of service resources. In order to have a general framework, we use queueing theory to model the service systems. However, we adopt an RL-based approach to avoid the limitations of queueing-theoretic methods. In particular, we use Deep Deterministic Policy Gradient (DDPG) to learn the service rates (action) as a function of the queue lengths (state) in tandem service systems. In contrast to existing RL-based methods that quantify their performance by the achieved overall reward, which could be hard to interpret or even misleading, our proposed controller provides explicit probabilistic guarantees on the end-to-end delay of the system. The evaluations are presented for a tandem queueing system with non-exponential inter-arrival and service times, the results of which validate our controller's capability in meeting QoS constraints.
Estimation of Missing Data in Intelligent Transportation System
Jan 09, 2021



Missing data is a challenge in many applications, including intelligent transportation systems (ITS). In this paper, we study traffic speed and travel time estimations in ITS, where portions of the collected data are missing due to sensor instability and communication errors at collection points. These practical issues can be remediated by missing data analysis, which are mainly categorized as either statistical or machine learning(ML)-based approaches. Statistical methods require the prior probability distribution of the data which is unknown in our application. Therefore, we focus on an ML-based approach, Multi-Directional Recurrent Neural Network (M-RNN). M-RNN utilizes both temporal and spatial characteristics of the data. We evaluate the effectiveness of this approach on a TomTom dataset containing spatio-temporal measurements of average vehicle speed and travel time in the Greater Toronto Area (GTA). We evaluate the method under various conditions, where the results demonstrate that M-RNN outperforms existing solutions,e.g., spline interpolation and matrix completion, by up to 58% decreases in Root Mean Square Error (RMSE).
Reinforcement Learning-based Admission Control in Delay-sensitive Service Systems
Aug 21, 2020



Ensuring quality of service (QoS) guarantees in service systems is a challenging task, particularly when the system is composed of more fine-grained services, such as service function chains. An important QoS metric in service systems is the end-to-end delay, which becomes even more important in delay-sensitive applications, where the jobs must be completed within a time deadline. Admission control is one way of providing end-to-end delay guarantee, where the controller accepts a job only if it has a high probability of meeting the deadline. In this paper, we propose a reinforcement learning-based admission controller that guarantees a probabilistic upper-bound on the end-to-end delay of the service system, while minimizes the probability of unnecessary rejections. Our controller only uses the queue length information of the network and requires no knowledge about the network topology or system parameters. Since long-term performance metrics are of great importance in service systems, we take an average-reward reinforcement learning approach, which is well suited to infinite horizon problems. Our evaluations verify that the proposed RL-based admission controller is capable of providing probabilistic bounds on the end-to-end delay of the network, without using system model information.
On the Robustness of Cooperative Multi-Agent Reinforcement Learning
Mar 08, 2020
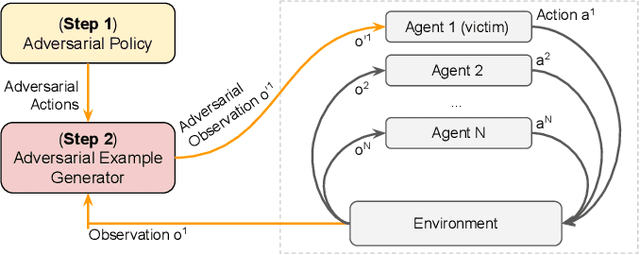

In cooperative multi-agent reinforcement learning (c-MARL), agents learn to cooperatively take actions as a team to maximize a total team reward. We analyze the robustness of c-MARL to adversaries capable of attacking one of the agents on a team. Through the ability to manipulate this agent's observations, the adversary seeks to decrease the total team reward. Attacking c-MARL is challenging for three reasons: first, it is difficult to estimate team rewards or how they are impacted by an agent mispredicting; second, models are non-differentiable; and third, the feature space is low-dimensional. Thus, we introduce a novel attack. The attacker first trains a policy network with reinforcement learning to find a wrong action it should encourage the victim agent to take. Then, the adversary uses targeted adversarial examples to force the victim to take this action. Our results on the StartCraft II multi-agent benchmark demonstrate that c-MARL teams are highly vulnerable to perturbations applied to one of their agent's observations. By attacking a single agent, our attack method has highly negative impact on the overall team reward, reducing it from 20 to 9.4. This results in the team's winning rate to go down from 98.9% to 0%.
Artificial Intelligence as a Services (AI-aaS) on Software-Defined Infrastructure
Jul 11, 2019



This paper investigates a paradigm for offering artificial intelligence as a service (AI-aaS) on software-defined infrastructures (SDIs). The increasing complexity of networking and computing infrastructures is already driving the introduction of automation in networking and cloud computing management systems. Here we consider how these automation mechanisms can be leveraged to offer AI-aaS. Use cases for AI-aaS are easily found in addressing smart applications in sectors such as transportation, manufacturing, energy, water, air quality, and emissions. We propose an architectural scheme based on SDIs where each AI-aaS application is comprised of a monitoring, analysis, policy, execution plus knowledge (MAPE-K) loop (MKL). Each application is composed as one or more specific service chains embedded in SDI, some of which will include a Machine Learning (ML) pipeline. Our model includes a new training plane and an AI-aaS plane to deal with the model-development and operational phases of AI applications. We also consider the role of an ML/MKL sandbox in ensuring coherency and consistency in the operation of multiple parallel MKL loops. We present experimental measurement results for three AI-aaS applications deployed on the SAVI testbed: 1. Compressing monitored data in SDI using autoencoders; 2. Traffic monitoring to allocate CPUs resources to VNFs; and 3. Highway segment classification in smart transportation.