 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Cooperative Multi-Agent Reinforcement Learning
Paper and Code
Mar 08, 2020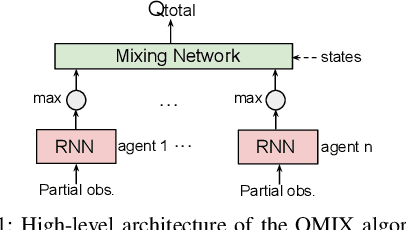
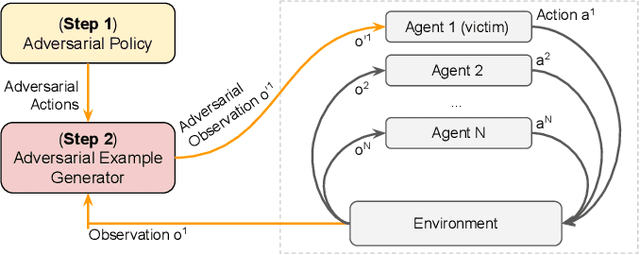

In cooperative multi-agent reinforcement learning (c-MARL), agents learn to cooperatively take actions as a team to maximize a total team reward. We analyze the robustness of c-MARL to adversaries capable of attacking one of the agents on a team. Through the ability to manipulate this agent's observations, the adversary seeks to decrease the total team reward. Attacking c-MARL is challenging for three reasons: first, it is difficult to estimate team rewards or how they are impacted by an agent mispredicting; second, models are non-differentiable; and third, the feature space is low-dimensional. Thus, we introduce a novel attack. The attacker first trains a policy network with reinforcement learning to find a wrong action it should encourage the victim agent to take. Then, the adversary uses targeted adversarial examples to force the victim to take this action. Our results on the StartCraft II multi-agent benchmark demonstrate that c-MARL teams are highly vulnerable to perturbations applied to one of their agent's observations. By attacking a single agent, our attack method has highly negative impact on the overall team reward, reducing it from 20 to 9.4. This results in the team's winning rate to go down from 98.9% to 0%.