 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Reinforcement Learning Approach for Fair Traffic Signal Control
Jul 21, 2021



Traffic signal control is one of the most effective methods of traffic management in urban areas. In recent years, traffic control methods based on deep reinforcement learning (DRL) have gained attention due to their ability to exploit real-time traffic data, which is often poorly used by the traditional hand-crafted methods. While most recent DRL-based methods have focused on maximizing the throughput or minimizing the average travel time of the vehicles, the fairness of the traffic signal controllers has often been neglected. This is particularly important as neglecting fairness can lead to situations where some vehicles experience extreme waiting times, or where the throughput of a particular traffic flow is highly impacted by the fluctuations of another conflicting flow at the intersection. In order to address these issues, we introduce two notions of fairness: delay-based and throughput-based fairness, which correspond to the two issues mentioned above. Furthermore, we propose two DRL-based traffic signal control methods for implementing these fairness notions, that can achieve a high throughput as well. We evaluate the performance of our proposed methods using three traffic arrival distributions, and find that our methods outperform the baselines in the tested scenarios.
Dynamic Resource Management for Providing QoS in Drone Delivery Systems
Mar 06, 2021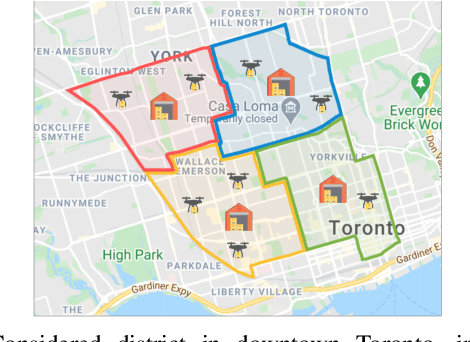
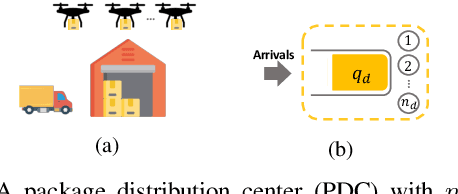

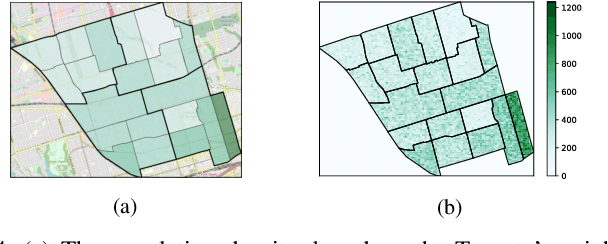
Drones have been considered as an alternative means of package delivery to reduce the delivery cost and time. Due to the battery limitations, the drones are best suited for last-mile delivery, i.e., the delivery from the package distribution centers (PDCs) to the customers. Since a typical delivery system consists of multiple PDCs, each having random and time-varying demands, the dynamic drone-to-PDC allocation would be of great importance in meeting the demand in an efficient manner. In this paper, we study the dynamic UAV assignment problem for a drone delivery system with the goal of providing measurable Quality of Service (QoS) guarantees. We adopt a queueing theoretic approach to model the customer-service nature of the problem. Furthermore, we take a deep reinforcement learning approach to obtain a dynamic policy for the re-allocation of the UAVs. This policy guarantees a probabilistic upper-bound on the queue length of the packages waiting in each PDC, which is beneficial from both the service provider's and the customers' viewpoints. We evaluate the performance of our proposed algorithm by considering three broad arrival classes, including Bernoulli, Time-Varying Bernoulli, and Markov-Modulated Bernoulli arrivals. Our results show that the proposed method outperforms the baselines, particularly in scenarios with Time-Varying and Markov-Modulated Bernoulli arrivals, which are more representative of real-world demand patterns. Moreover, our algorithm satisfies the QoS constraints in all the studied scenarios while minimizing the average number of UAVs in use.
Queue-Learning: A Reinforcement Learning Approach for Providing Quality of Service
Jan 12, 2021
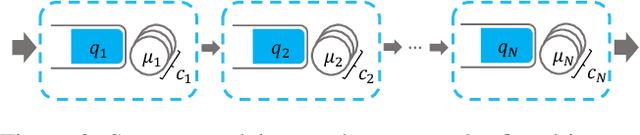


End-to-end delay is a critical attribute of quality of service (QoS) in application domains such as cloud computing and computer networks. This metric is particularly important in tandem service systems, where the end-to-end service is provided through a chain of services. Service-rate control is a common mechanism for providing QoS guarantees in service systems. In this paper, we introduce a reinforcement learning-based (RL-based) service-rate controller that provides probabilistic upper-bounds on the end-to-end delay of the system, while preventing the overuse of service resources. In order to have a general framework, we use queueing theory to model the service systems. However, we adopt an RL-based approach to avoid the limitations of queueing-theoretic methods. In particular, we use Deep Deterministic Policy Gradient (DDPG) to learn the service rates (action) as a function of the queue lengths (state) in tandem service systems. In contrast to existing RL-based methods that quantify their performance by the achieved overall reward, which could be hard to interpret or even misleading, our proposed controller provides explicit probabilistic guarantees on the end-to-end delay of the system. The evaluations are presented for a tandem queueing system with non-exponential inter-arrival and service times, the results of which validate our controller's capability in meeting QoS constraints.
Reinforcement Learning-based Admission Control in Delay-sensitive Service Systems
Aug 21, 2020



Ensuring quality of service (QoS) guarantees in service systems is a challenging task, particularly when the system is composed of more fine-grained services, such as service function chains. An important QoS metric in service systems is the end-to-end delay, which becomes even more important in delay-sensitive applications, where the jobs must be completed within a time deadline. Admission control is one way of providing end-to-end delay guarantee, where the controller accepts a job only if it has a high probability of meeting the deadline. In this paper, we propose a reinforcement learning-based admission controller that guarantees a probabilistic upper-bound on the end-to-end delay of the service system, while minimizes the probability of unnecessary rejections. Our controller only uses the queue length information of the network and requires no knowledge about the network topology or system parameters. Since long-term performance metrics are of great importance in service systems, we take an average-reward reinforcement learning approach, which is well suited to infinite horizon problems. Our evaluations verify that the proposed RL-based admission controller is capable of providing probabilistic bounds on the end-to-end delay of the network, without using system model information.