 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLFTSim: Realistic and Controllable Multi-Agent Traffic Simulation via Reinforcement Learning Fine-Tuning
May 18, 2026Supervised open-loop training has been widely adopted for training traffic simulation models; however, it fails to capture the inherently dynamic, multi-agent interactions common in complex driving scenarios. We introduce RLFTSim, a reinforcement-learning-based fine-tuning framework that enhances scenario realism by aligning simulator rollouts with real-world data distributions and provides a method for distilling goal-conditioned controllability in scenario generation. We instantiate RLFTSim on top of a pre-trained simulation model, design a reward that balances fidelity and controllability, and perform comprehensive experiments on the Waymo Open Motion Dataset. Our results show improvements in realism, achieving state-of-the-art performance. Compared with other heuristic search-based fine-tuning methods, RLFTSim requires significantly fewer samples due to a proposed low-variance and dense reward signal, and it directly addresses the realism alignment issue by design. We also demonstrate the effectiveness of our approach for distilling traffic simulation controllability through goal conditioning. The project page is available at https://ehsan-ami.github.io/rlftsim.
CAPS: Context-Aware Priority Sampling for Enhanced Imitation Learning in Autonomous Driving
Mar 03, 2025In this paper, we introduce CAPS (Context-Aware Priority Sampling), a novel method designed to enhance data efficiency in learning-based autonomous driving systems. CAPS addresses the challenge of imbalanced training datasets in imitation learning by leveraging Vector Quantized Variational Autoencoders (VQ-VAEs). The use of VQ-VAE provides a structured and interpretable data representation, which helps reveal meaningful patterns in the data. These patterns are used to group the data into clusters, with each sample being assigned a cluster ID. The cluster IDs are then used to re-balance the dataset, ensuring that rare yet valuable samples receive higher priority during training. By ensuring a more diverse and informative training set, CAPS improves the generalization of the trained planner across a wide range of driving scenarios. We evaluate our method through closed-loop simulations in the CARLA environment. The results on Bench2Drive scenarios demonstrate that our framework outperforms state-of-the-art methods, leading to notable improvements in model performance.
Learning Soft Driving Constraints from Vectorized Scene Embeddings while Imitating Expert Trajectories
Dec 07, 2024


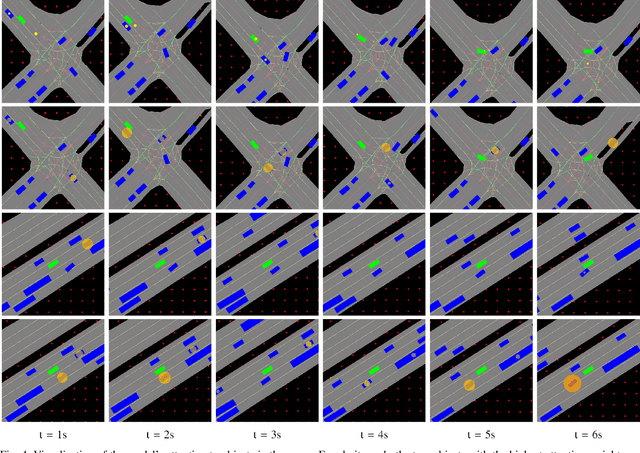
The primary goal of motion planning is to generate safe and efficient trajectories for vehicles. Traditionally, motion planning models are trained using imitation learning to mimic the behavior of human experts. However, these models often lack interpretability and fail to provide clear justifications for their decisions. We propose a method that integrates constraint learning into imitation learning by extracting driving constraints from expert trajectories. Our approach utilizes vectorized scene embeddings that capture critical spatial and temporal features, enabling the model to identify and generalize constraints across various driving scenarios. We formulate the constraint learning problem using a maximum entropy model, which scores the motion planner's trajectories based on their similarity to the expert trajectory. By separating the scoring process into distinct reward and constraint streams, we improve both the interpretability of the planner's behavior and its attention to relevant scene components. Unlike existing constraint learning methods that rely on simulators and are typically embedded in reinforcement learning (RL) or inverse reinforcement learning (IRL) frameworks, our method operates without simulators, making it applicable to a wider range of datasets and real-world scenarios. Experimental results on the InD and TrafficJams datasets demonstrate that incorporating driving constraints enhances model interpretability and improves closed-loop performance.
Learning from Mistakes: a Weakly-supervised Method for Mitigating the Distribution Shift in Autonomous Vehicle Planning
Jun 03, 2024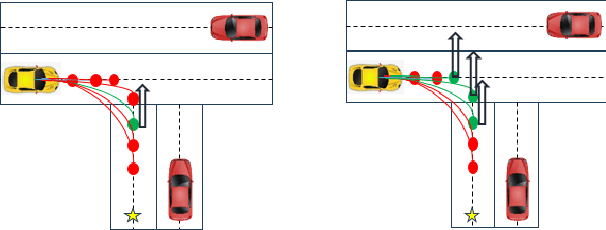



The planning problem constitutes a fundamental aspect of the autonomous driving framework. Recent strides in representation learning have empowered vehicles to comprehend their surrounding environments, thereby facilitating the integration of learning-based planning strategies. Among these approaches, Imitation Learning stands out due to its notable training efficiency. However, traditional Imitation Learning methodologies encounter challenges associated with the co-variate shift phenomenon. We propose Learn from Mistakes (LfM) as a remedy to address this issue. The essence of LfM lies in deploying a pre-trained planner across diverse scenarios. Instances where the planner deviates from its immediate objectives, such as maintaining a safe distance from obstacles or adhering to traffic rules, are flagged as mistakes. The environments corresponding to these mistakes are categorized as out-of-distribution states and compiled into a new dataset termed closed-loop mistakes dataset. Notably, the absence of expert annotations for the closed-loop data precludes the applicability of standard imitation learning approaches. To facilitate learning from the closed-loop mistakes, we introduce Validity Learning, a weakly supervised method, which aims to discern valid trajectories within the current environmental context. Experimental evaluations conducted on the InD and Nuplan datasets reveal substantial enhancements in closed-loop metrics such as Progress and Collision Rate, underscoring the effectiveness of the proposed methodology.
Augmenting Safety-Critical Driving Scenarios while Preserving Similarity to Expert Trajectories
Apr 20, 2024
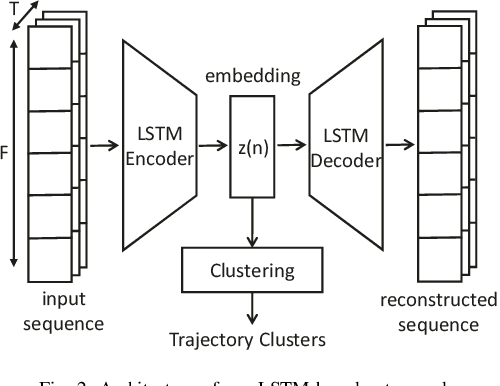
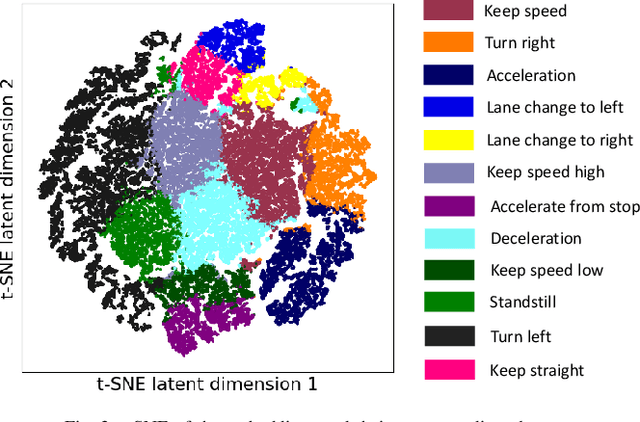
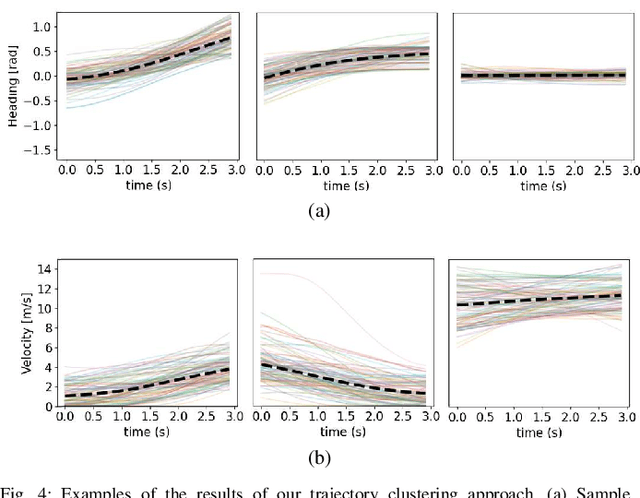
Trajectory augmentation serves as a means to mitigate distributional shift in imitation learning. However, imitating trajectories that inadequately represent the original expert data can result in undesirable behaviors, particularly in safety-critical scenarios. We propose a trajectory augmentation method designed to maintain similarity with expert trajectory data. To accomplish this, we first cluster trajectories to identify minority yet safety-critical groups. Then, we combine the trajectories within the same cluster through geometrical transformation to create new trajectories. These trajectories are then added to the training dataset, provided that they meet our specified safety-related criteria. Our experiments exhibit that training an imitation learning model using these augmented trajectories can significantly improve closed-loop performance.
Distributed Deep Reinforcement Learning for Intelligent Traffic Monitoring with a Team of Aerial Robots
Jul 10, 2021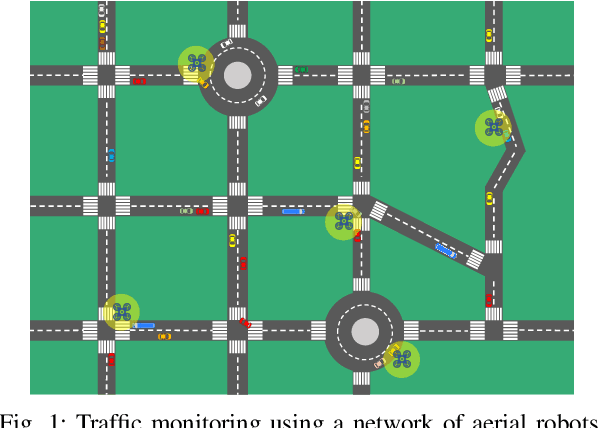
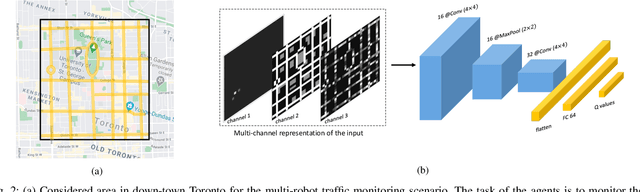
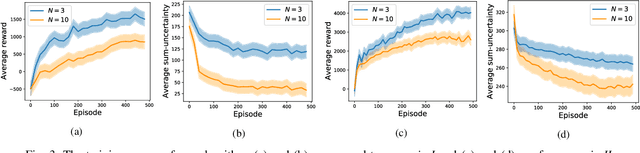
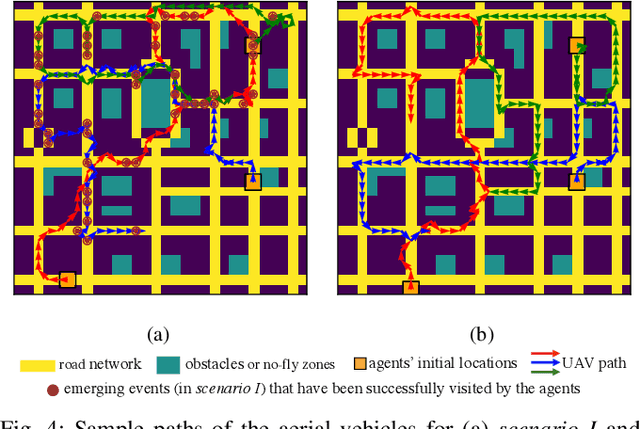
This paper studies the traffic monitoring problem in a road network using a team of aerial robots. The problem is challenging due to two main reasons. First, the traffic events are stochastic, both temporally and spatially. Second, the problem has a non-homogeneous structure as the traffic events arrive at different locations of the road network at different rates. Accordingly, some locations require more visits by the robots compared to other locations. To address these issues, we define an uncertainty metric for each location of the road network and formulate a path planning problem for the aerial robots to minimize the network's average uncertainty. We express this problem as a partially observable Markov decision process (POMDP) and propose a distributed and scalable algorithm based on deep reinforcement learning to solve it. We consider two different scenarios depending on the communication mode between the agents (aerial robots) and the traffic management center (TMC). The first scenario assumes that the agents continuously communicate with the TMC to send/receive real-time information about the traffic events. Hence, the agents have global and real-time knowledge of the environment. However, in the second scenario, we consider a challenging setting where the observation of the aerial robots is partial and limited to their sensing ranges. Moreover, in contrast to the first scenario, the information exchange between the aerial robots and the TMC is restricted to specific time instances. We evaluate the performance of our proposed algorithm in both scenarios for a real road network topology and demonstrate its functionality in a traffic monitoring system.
Dynamic Resource Management for Providing QoS in Drone Delivery Systems
Mar 06, 2021
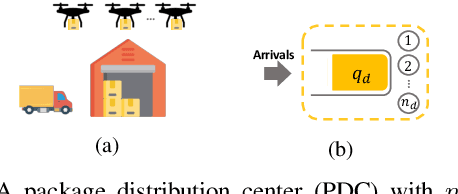

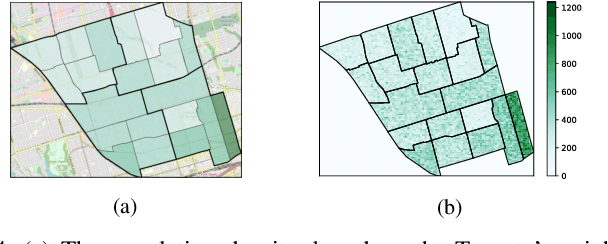
Drones have been considered as an alternative means of package delivery to reduce the delivery cost and time. Due to the battery limitations, the drones are best suited for last-mile delivery, i.e., the delivery from the package distribution centers (PDCs) to the customers. Since a typical delivery system consists of multiple PDCs, each having random and time-varying demands, the dynamic drone-to-PDC allocation would be of great importance in meeting the demand in an efficient manner. In this paper, we study the dynamic UAV assignment problem for a drone delivery system with the goal of providing measurable Quality of Service (QoS) guarantees. We adopt a queueing theoretic approach to model the customer-service nature of the problem. Furthermore, we take a deep reinforcement learning approach to obtain a dynamic policy for the re-allocation of the UAVs. This policy guarantees a probabilistic upper-bound on the queue length of the packages waiting in each PDC, which is beneficial from both the service provider's and the customers' viewpoints. We evaluate the performance of our proposed algorithm by considering three broad arrival classes, including Bernoulli, Time-Varying Bernoulli, and Markov-Modulated Bernoulli arrivals. Our results show that the proposed method outperforms the baselines, particularly in scenarios with Time-Varying and Markov-Modulated Bernoulli arrivals, which are more representative of real-world demand patterns. Moreover, our algorithm satisfies the QoS constraints in all the studied scenarios while minimizing the average number of UAVs in use.
Federated Learning for Cellular-connected UAVs: Radio Mapping and Path Planning
Aug 23, 2020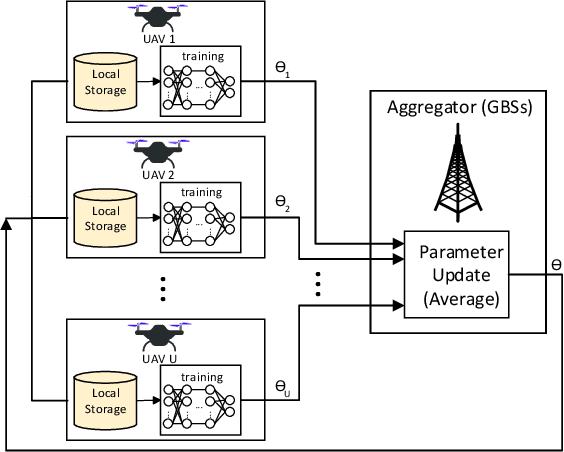
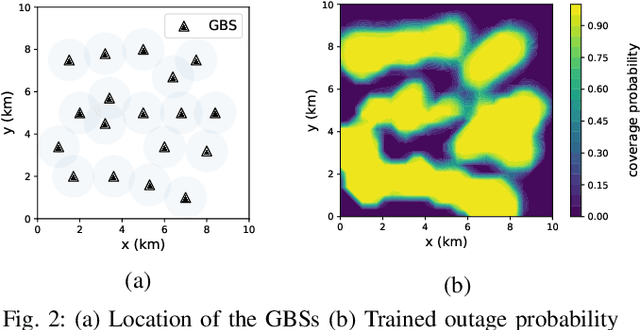
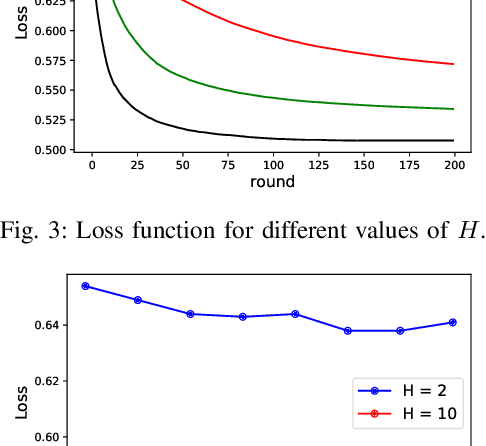
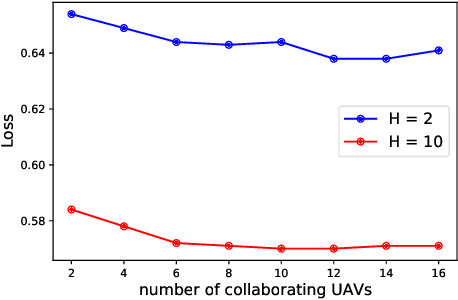
To prolong the lifetime of the unmanned aerial vehicles (UAVs), the UAVs need to fulfill their missions in the shortest possible time. In addition to this requirement, in many applications, the UAVs require a reliable internet connection during their flights. In this paper, we minimize the travel time of the UAVs, ensuring that a probabilistic connectivity constraint is satisfied. To solve this problem, we need a global model of the outage probability in the environment. Since the UAVs have different missions and fly over different areas, their collected data carry local information on the network's connectivity. As a result, the UAVs can not rely on their own experiences to build the global model. This issue affects the path planning of the UAVs. To address this concern, we utilize a two-step approach. In the first step, by using Federated Learning (FL), the UAVs collaboratively build a global model of the outage probability in the environment. In the second step, by using the global model obtained in the first step and rapidly-exploring random trees (RRTs), we propose an algorithm to optimize UAVs' paths. Simulation results show the effectiveness of this two-step approach for UAV networks.
A Double Q-Learning Approach for Navigation of Aerial Vehicles with Connectivity Constraint
Feb 24, 2020



This paper studies the trajectory optimization problem for an aerial vehicle with the mission of flying between a pair of given initial and final locations. The objective is to minimize the travel time of the aerial vehicle ensuring that the communication connectivity constraint required for the safe operation of the aerial vehicle is satisfied. We consider two different criteria for the connectivity constraint of the aerial vehicle which leads to two different scenarios. In the first scenario, we assume that the maximum continuous time duration that the aerial vehicle is out of the coverage of the ground base stations (GBSs) is limited to a given threshold. In the second scenario, however, we assume that the total time periods that the aerial vehicle is not covered by the GBSs is restricted. Based on these two constraints, we formulate two trajectory optimization problems. To solve these non-convex problems, we use an approach based on the double Q-learning method which is a model-free reinforcement learning technique and unlike the existing algorithms does not need perfect knowledge of the environment. Moreover, in contrast to the well-known Q-learning technique, our double Q-learning algorithm does not suffer from the over-estimation issue. Simulation results show that although our algorithm does not require prior information of the environment, it works well and shows near optimal performance.
Reinforcement Learning-Based Trajectory Design for the Aerial Base Stations
Jun 29, 2019


In this paper, the trajectory optimization problem for a multi-aerial base station (ABS) communication network is investigated. The objective is to find the trajectory of the ABSs so that the sum-rate of the users served by each ABS is maximized. To reach this goal, along with the optimal trajectory design, optimal power and sub-channel allocation is also of great importance to support the users with the highest possible data rates. To solve this complicated problem, we divide it into two sub-problems: ABS trajectory optimization sub-problem, and joint power and sub-channel assignment sub-problem. Then, based on the Q-learning method, we develop a distributed algorithm which solves these sub-problems efficiently, and does not need significant amount of information exchange between the ABSs and the core network. Simulation results show that although Q-learning is a model-free reinforcement learning technique, it has a remarkable capability to train the ABSs to optimize their trajectories based on the received reward signals, which carry decent information from the topology of the network.