 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Locomotion Prediction in Construction Using a Memory-Driven LLM Agent With Chain-of-Thought Reasoning
Apr 21, 2025Construction tasks are inherently unpredictable, with dynamic environments and safety-critical demands posing significant risks to workers. Exoskeletons offer potential assistance but falter without accurate intent recognition across diverse locomotion modes. This paper presents a locomotion prediction agent leveraging Large Language Models (LLMs) augmented with memory systems, aimed at improving exoskeleton assistance in such settings. Using multimodal inputs - spoken commands and visual data from smart glasses - the agent integrates a Perception Module, Short-Term Memory (STM), Long-Term Memory (LTM), and Refinement Module to predict locomotion modes effectively. Evaluation reveals a baseline weighted F1-score of 0.73 without memory, rising to 0.81 with STM, and reaching 0.90 with both STM and LTM, excelling with vague and safety-critical commands. Calibration metrics, including a Brier Score drop from 0.244 to 0.090 and ECE from 0.222 to 0.044, affirm improved reliability. This framework supports safer, high-level human-exoskeleton collaboration, with promise for adaptive assistive systems in dynamic industries.
CAPS: Context-Aware Priority Sampling for Enhanced Imitation Learning in Autonomous Driving
Mar 03, 2025In this paper, we introduce CAPS (Context-Aware Priority Sampling), a novel method designed to enhance data efficiency in learning-based autonomous driving systems. CAPS addresses the challenge of imbalanced training datasets in imitation learning by leveraging Vector Quantized Variational Autoencoders (VQ-VAEs). The use of VQ-VAE provides a structured and interpretable data representation, which helps reveal meaningful patterns in the data. These patterns are used to group the data into clusters, with each sample being assigned a cluster ID. The cluster IDs are then used to re-balance the dataset, ensuring that rare yet valuable samples receive higher priority during training. By ensuring a more diverse and informative training set, CAPS improves the generalization of the trained planner across a wide range of driving scenarios. We evaluate our method through closed-loop simulations in the CARLA environment. The results on Bench2Drive scenarios demonstrate that our framework outperforms state-of-the-art methods, leading to notable improvements in model performance.
Getting SMARTER for Motion Planning in Autonomous Driving Systems
Feb 20, 2025



Motion planning is a fundamental problem in autonomous driving and perhaps the most challenging to comprehensively evaluate because of the associated risks and expenses of real-world deployment. Therefore, simulations play an important role in efficient development of planning algorithms. To be effective, simulations must be accurate and realistic, both in terms of dynamics and behavior modeling, and also highly customizable in order to accommodate a broad spectrum of research frameworks. In this paper, we introduce SMARTS 2.0, the second generation of our motion planning simulator which, in addition to being highly optimized for large-scale simulation, provides many new features, such as realistic map integration, vehicle-to-vehicle (V2V) communication, traffic and pedestrian simulation, and a broad variety of sensor models. Moreover, we present a novel benchmark suite for evaluating planning algorithms in various highly challenging scenarios, including interactive driving, such as turning at intersections, and adaptive driving, in which the task is to closely follow a lead vehicle without any explicit knowledge of its intention. Each scenario is characterized by a variety of traffic patterns and road structures. We further propose a series of common and task-specific metrics to effectively evaluate the performance of the planning algorithms. At the end, we evaluate common motion planning algorithms using the proposed benchmark and highlight the challenges the proposed scenarios impose. The new SMARTS 2.0 features and the benchmark are publicly available at github.com/huawei-noah/SMARTS.
AMEND: A Mixture of Experts Framework for Long-tailed Trajectory Prediction
Feb 13, 2024



Accurate prediction of pedestrians' future motions is critical for intelligent driving systems. Developing models for this task requires rich datasets containing diverse sets of samples. However, the existing naturalistic trajectory prediction datasets are generally imbalanced in favor of simpler samples and lack challenging scenarios. Such a long-tail effect causes prediction models to underperform on the tail portion of the data distribution containing safety-critical scenarios. Previous methods tackle the long-tail problem using methods such as contrastive learning and class-conditioned hypernetworks. These approaches, however, are not modular and cannot be applied to many machine learning architectures. In this work, we propose a modular model-agnostic framework for trajectory prediction that leverages a specialized mixture of experts. In our approach, each expert is trained with a specialized skill with respect to a particular part of the data. To produce predictions, we utilise a router network that selects the best expert by generating relative confidence scores. We conduct experimentation on common pedestrian trajectory prediction datasets and show that besides achieving state-of-the-art performance, our method significantly performs better on long-tail scenarios. We further conduct ablation studies to highlight the contribution of different proposed components.
Sparsity aware coding for single photon sensitive vision using Selective Sensing
Aug 09, 2023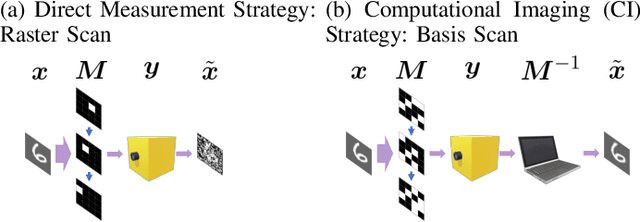
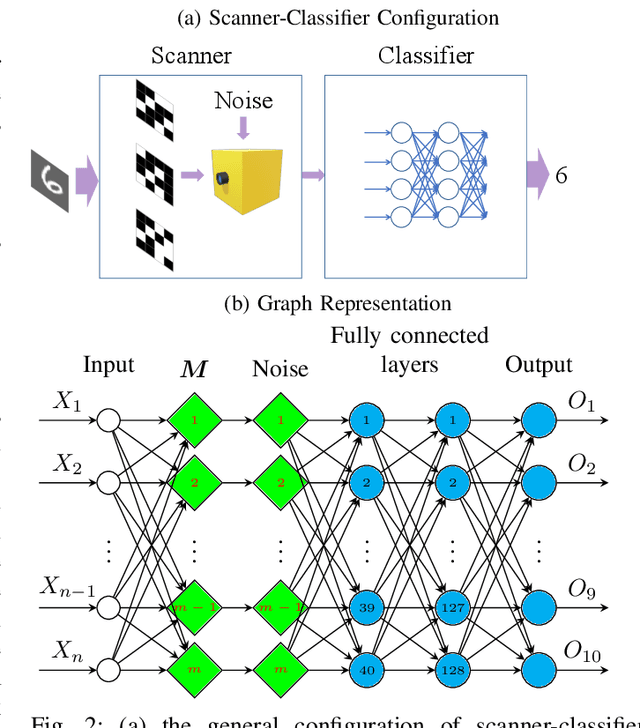
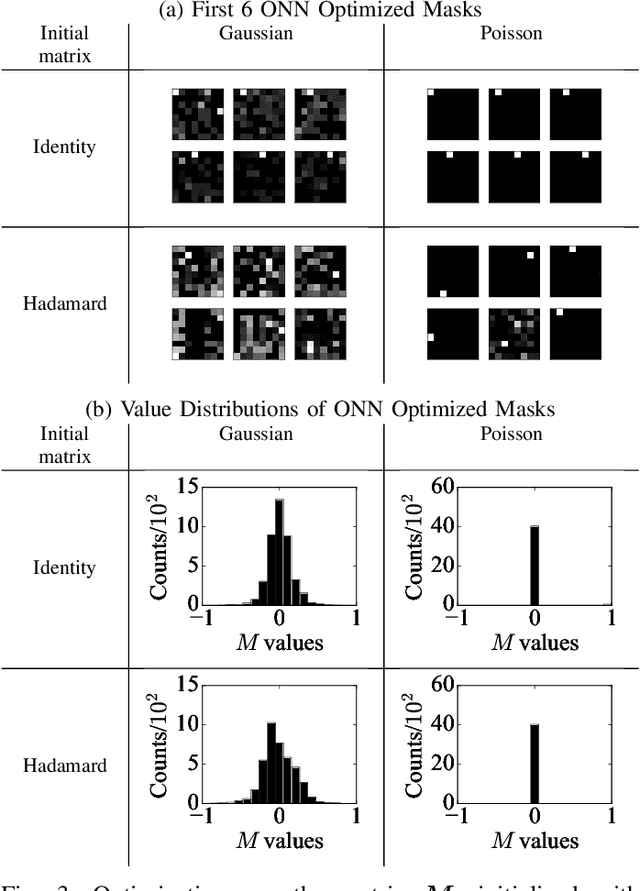
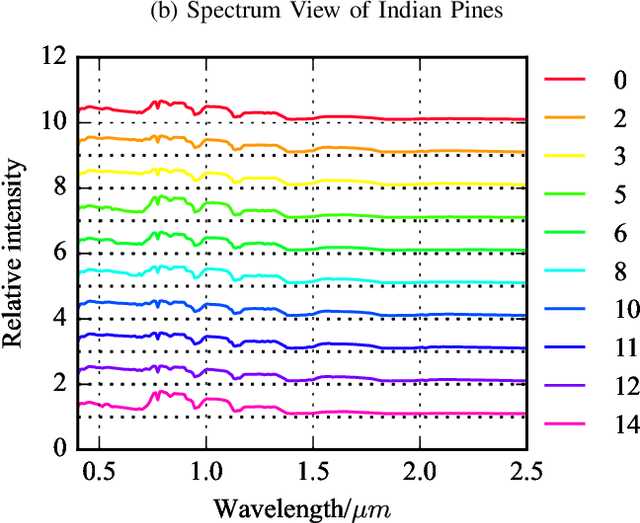
Optical coding has been widely adopted to improve the imaging techniques. Traditional coding strategies developed under additive Gaussian noise fail to perform optimally in the presence of Poisson noise. It has been observed in previous studies that coding performance varies significantly between these two noise models. In this work, we introduce a novel approach called selective sensing, which leverages training data to learn priors and optimizes the coding strategies for downstream classification tasks. By adapting to the specific characteristics of photon-counting sensors, the proposed method aims to improve coding performance under Poisson noise and enhance overall classification accuracy. Experimental and simulated results demonstrate the effectiveness of selective sensing in comparison to traditional coding strategies, highlighting its potential for practical applications in photon counting scenarios where Poisson noise are prevalent.