 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning-Based Approach for Cell Outage Compensation in NOMA Networks
Apr 08, 2022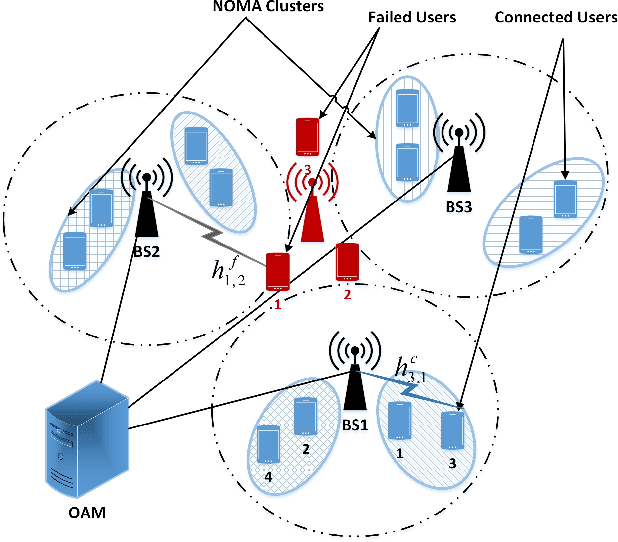
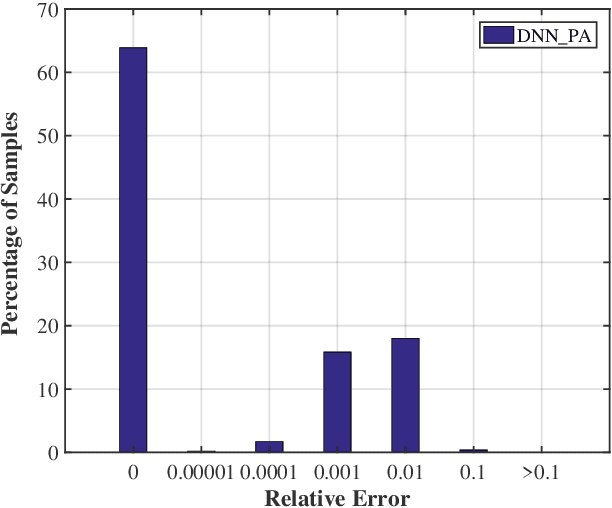
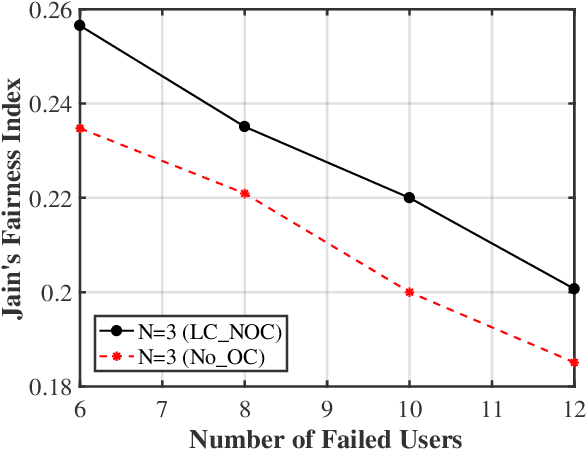
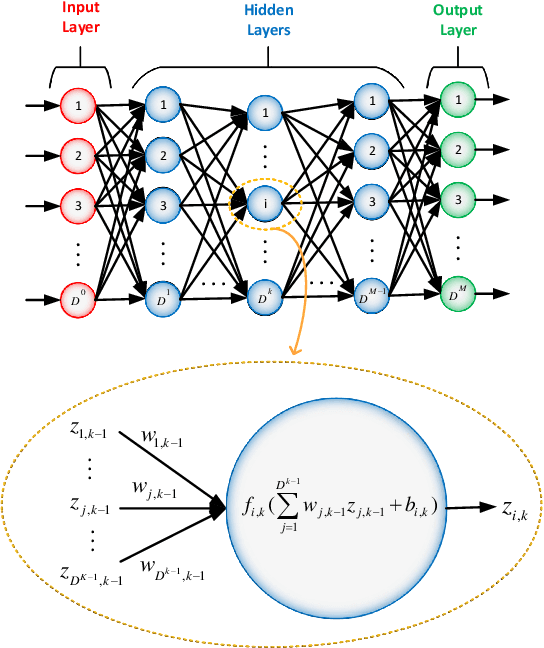
Cell outage compensation enables a network to react to a catastrophic cell failure quickly and serve users in the outage zone uninterruptedly. Utilizing the promising benefits of non-orthogonal multiple access (NOMA) for improving the throughput of cell edge users, we propose a newly NOMA-based cell outage compensation scheme. In this scheme, the compensation is formulated as a mixed integer non-linear program (MINLP) where outage zone users are associated to neighboring cells and their power are allocated with the objective of maximizing spectral efficiency, subject to maintaining the quality of service for the rest of the users. Owing to the importance of immediate management of cell outage and handling the computational complexity, we develop a low-complexity suboptimal solution for this problem in which the user association scheme is determined by a newly heuristic algorithm, and power allocation is set by applying an innovative deep neural network (DNN). The complexity of our proposed method is in the order of polynomial basis, which is much less than the exponential complexity of finding an optimal solution. Simulation results demonstrate that the proposed method approaches the optimal solution. Moreover, the developed scheme greatly improves fairness and increases the number of served users.
Interaction and Conflict Management in AI-assisted Operational Control Loops in 6G
Oct 22, 2021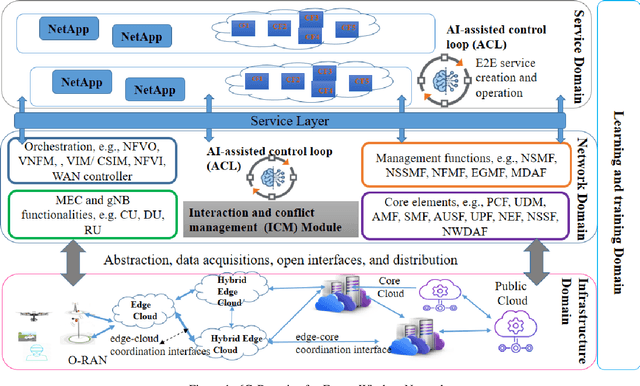
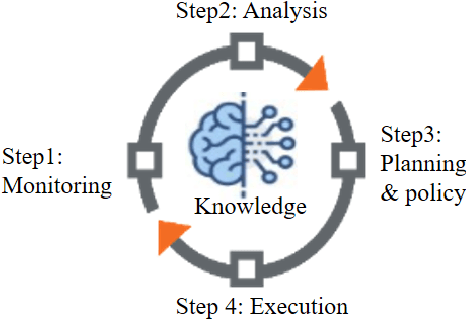
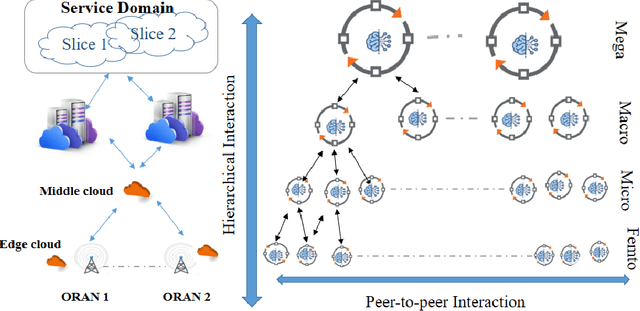
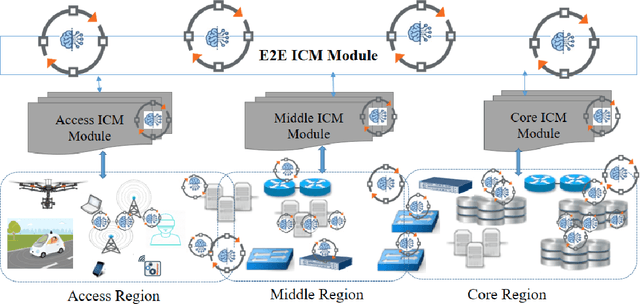
This paper studies autonomous and AI-assisted control loops (ACLs) in the next generation of wireless networks in the lens of multi-agent environments. We will study the diverse interactions and conflict management among these loops. We propose "interaction and conflict management" (ICM) modules to achieve coherent, consistent and interactions among these ACLs. We introduce three categories of ACLs based on their sizes, their cooperative and competitive behaviors, and their sharing of datasets and models. These categories help to introduce conflict resolution and interaction management mechanisms for ICM. Using Kubernetes, we present an implementation of ICM to remove the conflicts in the scheduling and rescheduling of Pods for different ACLs in networks.
Missing Data Estimation in Temporal Multilayer Position-aware Graph Neural Network (TMP-GNN)
Aug 07, 2021



GNNs have been proven to perform highly effective in various node-level, edge-level, and graph-level prediction tasks in several domains. Existing approaches mainly focus on static graphs. However, many graphs change over time with their edge may disappear, or node or edge attribute may alter from one time to the other. It is essential to consider such evolution in representation learning of nodes in time varying graphs. In this paper, we propose a Temporal Multilayered Position-aware Graph Neural Network (TMP-GNN), a node embedding approach for dynamic graph that incorporates the interdependence of temporal relations into embedding computation. We evaluate the performance of TMP-GNN on two different representations of temporal multilayered graphs. The performance is assessed against the most popular GNNs on node-level prediction tasks. Then, we incorporate TMP-GNN into a deep learning framework to estimate missing data and compare the performance with their corresponding competent GNNs from our former experiment, and a baseline method. Experimental results on four real-world datasets yield up to 58% of lower ROC AUC for pairwise node classification task, and 96% of lower MAE in missing feature estimation, particularly for graphs with a relatively high number of nodes and lower mean degree of connectivity.
Toward Efficient Transfer Learning in 6G
Jul 12, 2021



6G networks will greatly expand the support for data-oriented, autonomous applications for over the top (OTT) and networking use cases. The success of these use cases will depend on the availability of big data sets which is not practical in many real scenarios due to the highly dynamic behavior of systems and the cost of data collection procedures. Transfer learning (TL) is a promising approach to deal with these challenges through the sharing of knowledge among diverse learning algorithms. with TL, the learning rate and learning accuracy can be considerably improved. However, there are implementation challenges to efficiently deploy and utilize TL in 6G. In this paper, we initiate this discussion by providing some performance metrics to measure the TL success. Then, we show how infrastructure, application, management, and training planes of 6G can be adapted to handle TL. We provide examples of TL in 6G and highlight the spatio-temporal features of data in 6G that can lead to efficient TL. By simulation results, we demonstrate how transferring the quantized neural network weights between two use cases can make a trade-off between overheads and performance and attain more efficient TL in 6G. We also provide a list of future research directions in TL for 6G.
Generalized ADMM in Distributed Learning via Variational Inequality
Apr 26, 2021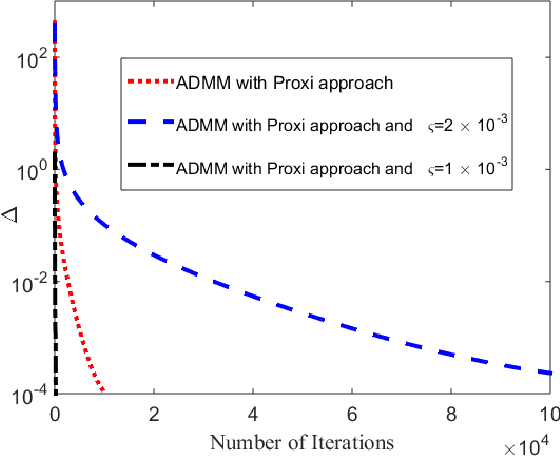

Due to the explosion in size and complexity of modern data sets and privacy concerns of data holders, it is increasingly important to be able to solve machine learning problems in distributed manners. The Alternating Direction Method of Multipliers (ADMM) through the concept of consensus variables is a practical algorithm in this context where its diverse variations and its performance have been studied in different application areas. In this paper, we study the effect of the local data sets of users in the distributed learning of ADMM. Our aim is to deploy variational inequality (VI) to attain an unified view of ADMM variations. Through the simulation results, we demonstrate how more general definitions of consensus parameters and introducing the uncertain parameters in distribute approach can help to get the better results in learning processes.
Robust Federated Learning by Mixture of Experts
Apr 23, 2021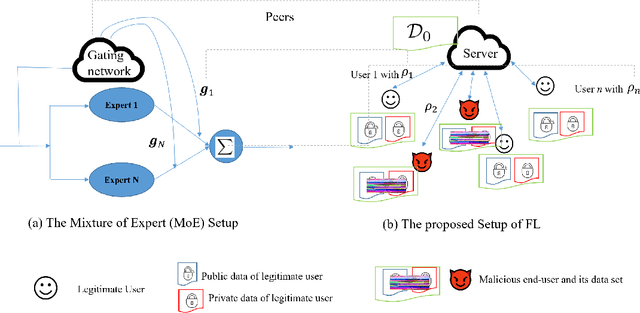
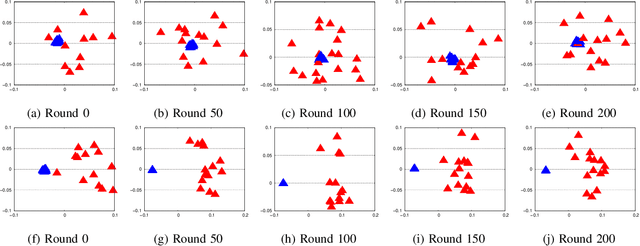
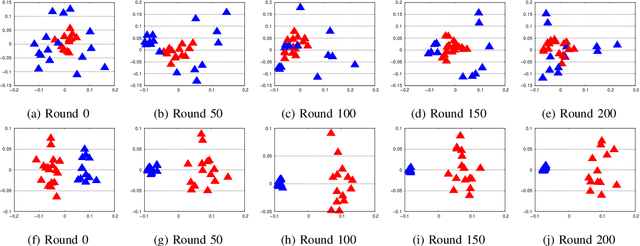
We present a novel weighted average model based on the mixture of experts (MoE) concept to provide robustness in Federated learning (FL) against the poisoned/corrupted/outdated local models. These threats along with the non-IID nature of data sets can considerably diminish the accuracy of the FL model. Our proposed MoE-FL setup relies on the trust between users and the server where the users share a portion of their public data sets with the server. The server applies a robust aggregation method by solving the optimization problem or the Softmax method to highlight the outlier cases and to reduce their adverse effect on the FL process. Our experiments illustrate that MoE-FL outperforms the performance of the traditional aggregation approach for high rate of poisoned data from attackers.
Estimation of Missing Data in Intelligent Transportation System
Jan 09, 2021



Missing data is a challenge in many applications, including intelligent transportation systems (ITS). In this paper, we study traffic speed and travel time estimations in ITS, where portions of the collected data are missing due to sensor instability and communication errors at collection points. These practical issues can be remediated by missing data analysis, which are mainly categorized as either statistical or machine learning(ML)-based approaches. Statistical methods require the prior probability distribution of the data which is unknown in our application. Therefore, we focus on an ML-based approach, Multi-Directional Recurrent Neural Network (M-RNN). M-RNN utilizes both temporal and spatial characteristics of the data. We evaluate the effectiveness of this approach on a TomTom dataset containing spatio-temporal measurements of average vehicle speed and travel time in the Greater Toronto Area (GTA). We evaluate the method under various conditions, where the results demonstrate that M-RNN outperforms existing solutions,e.g., spline interpolation and matrix completion, by up to 58% decreases in Root Mean Square Error (RMSE).
Representation of Federated Learning via Worst-Case Robust Optimization Theory
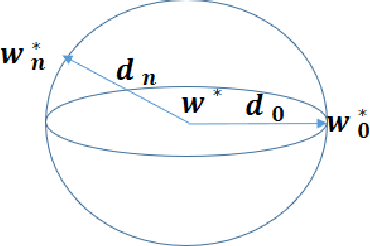
Dec 11, 2019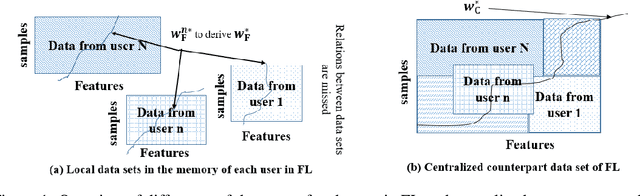
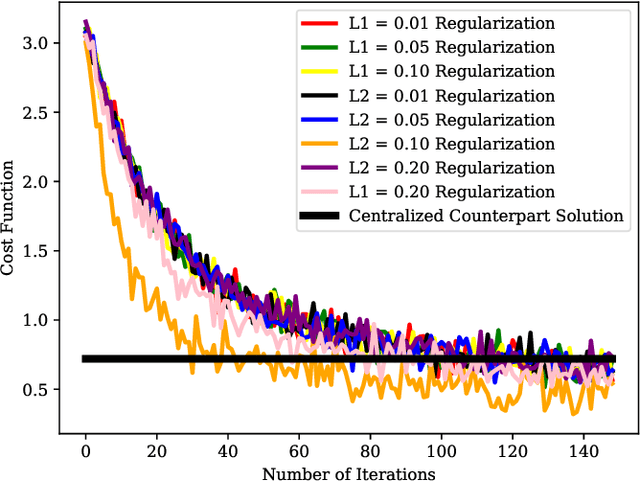

Federated learning (FL) is a distributed learning approach where a set of end-user devices participate in the learning process by acting on their isolated local data sets. Here, we process local data sets of users where worst-case optimization theory is used to reformulate the FL problem where the impact of local data sets in training phase is considered as an uncertain function bounded in a closed uncertainty region. This representation allows us to compare the performance of FL with its centralized counterpart, and to replace the uncertain function with a concept of protection functions leading to more tractable formulation. The latter supports applying a regularization factor in each user cost function in FL to reach a better performance. We evaluated our model using the MNIST data set versus the protection function parameters, e.g., regularization factors.
Artificial Intelligence as a Services (AI-aaS) on Software-Defined Infrastructure
Jul 11, 2019



This paper investigates a paradigm for offering artificial intelligence as a service (AI-aaS) on software-defined infrastructures (SDIs). The increasing complexity of networking and computing infrastructures is already driving the introduction of automation in networking and cloud computing management systems. Here we consider how these automation mechanisms can be leveraged to offer AI-aaS. Use cases for AI-aaS are easily found in addressing smart applications in sectors such as transportation, manufacturing, energy, water, air quality, and emissions. We propose an architectural scheme based on SDIs where each AI-aaS application is comprised of a monitoring, analysis, policy, execution plus knowledge (MAPE-K) loop (MKL). Each application is composed as one or more specific service chains embedded in SDI, some of which will include a Machine Learning (ML) pipeline. Our model includes a new training plane and an AI-aaS plane to deal with the model-development and operational phases of AI applications. We also consider the role of an ML/MKL sandbox in ensuring coherency and consistency in the operation of multiple parallel MKL loops. We present experimental measurement results for three AI-aaS applications deployed on the SAVI testbed: 1. Compressing monitored data in SDI using autoencoders; 2. Traffic monitoring to allocate CPUs resources to VNFs; and 3. Highway segment classification in smart transportation.