 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixTailor: Mixed Gradient Aggregation for Robust Learning Against Tailored Attacks
Jul 16, 2022
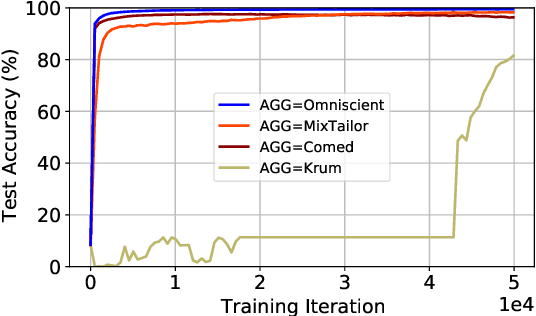
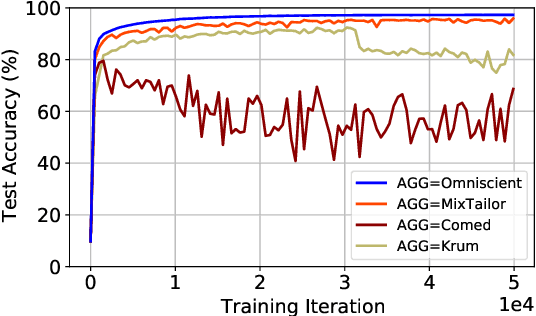
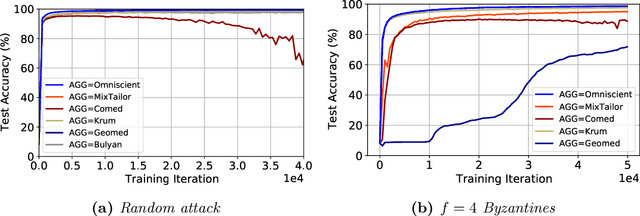
Implementations of SGD on distributed and multi-GPU systems creates new vulnerabilities, which can be identified and misused by one or more adversarial agents. Recently, it has been shown that well-known Byzantine-resilient gradient aggregation schemes are indeed vulnerable to informed attackers that can tailor the attacks (Fang et al., 2020; Xie et al., 2020b). We introduce MixTailor, a scheme based on randomization of the aggregation strategies that makes it impossible for the attacker to be fully informed. Deterministic schemes can be integrated into MixTailor on the fly without introducing any additional hyperparameters. Randomization decreases the capability of a powerful adversary to tailor its attacks, while the resulting randomized aggregation scheme is still competitive in terms of performance. For both iid and non-iid settings, we establish almost sure convergence guarantees that are both stronger and more general than those available in the literature. Our empirical studies across various datasets, attacks, and settings, validate our hypothesis and show that MixTailor successfully defends when well-known Byzantine-tolerant schemes fail.
Adaptive Gradient Quantization for Data-Parallel SGD
Oct 23, 2020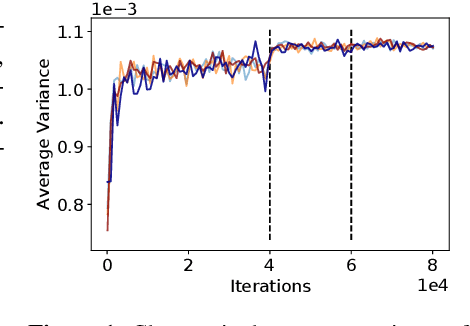
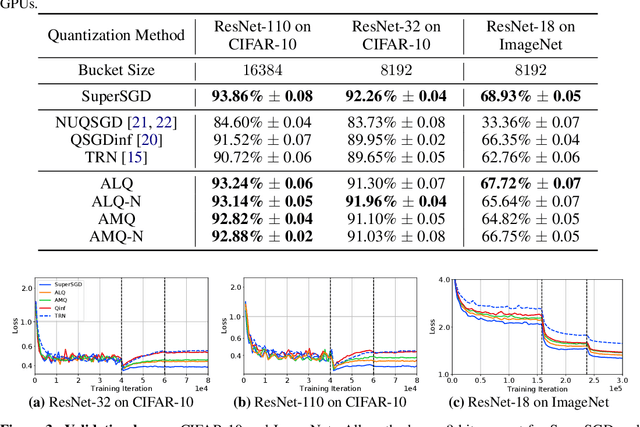
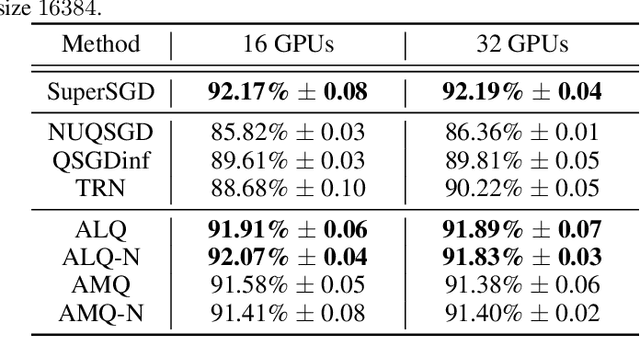
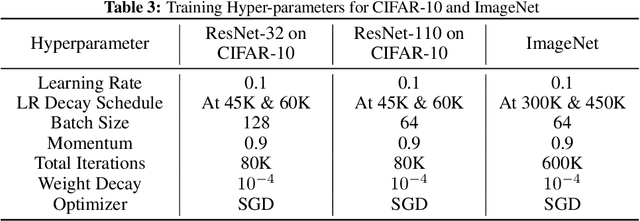
Many communication-efficient variants of SGD use gradient quantization schemes. These schemes are often heuristic and fixed over the course of training. We empirically observe that the statistics of gradients of deep models change during the training. Motivated by this observation, we introduce two adaptive quantization schemes, ALQ and AMQ. In both schemes, processors update their compression schemes in parallel by efficiently computing sufficient statistics of a parametric distribution. We improve the validation accuracy by almost 2% on CIFAR-10 and 1% on ImageNet in challenging low-cost communication setups. Our adaptive methods are also significantly more robust to the choice of hyperparameters.
Representation of Federated Learning via Worst-Case Robust Optimization Theory
Dec 11, 2019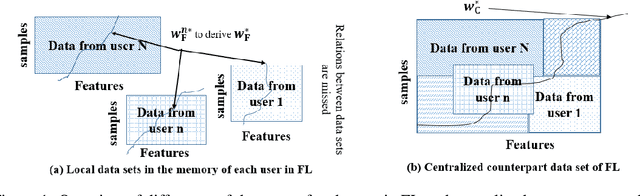
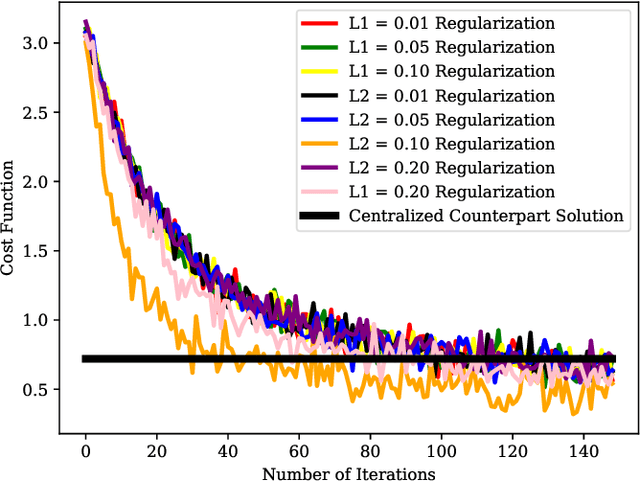

Federated learning (FL) is a distributed learning approach where a set of end-user devices participate in the learning process by acting on their isolated local data sets. Here, we process local data sets of users where worst-case optimization theory is used to reformulate the FL problem where the impact of local data sets in training phase is considered as an uncertain function bounded in a closed uncertainty region. This representation allows us to compare the performance of FL with its centralized counterpart, and to replace the uncertain function with a concept of protection functions leading to more tractable formulation. The latter supports applying a regularization factor in each user cost function in FL to reach a better performance. We evaluated our model using the MNIST data set versus the protection function parameters, e.g., regularization factors.
Artificial Intelligence as a Services (AI-aaS) on Software-Defined Infrastructure
Jul 11, 2019



This paper investigates a paradigm for offering artificial intelligence as a service (AI-aaS) on software-defined infrastructures (SDIs). The increasing complexity of networking and computing infrastructures is already driving the introduction of automation in networking and cloud computing management systems. Here we consider how these automation mechanisms can be leveraged to offer AI-aaS. Use cases for AI-aaS are easily found in addressing smart applications in sectors such as transportation, manufacturing, energy, water, air quality, and emissions. We propose an architectural scheme based on SDIs where each AI-aaS application is comprised of a monitoring, analysis, policy, execution plus knowledge (MAPE-K) loop (MKL). Each application is composed as one or more specific service chains embedded in SDI, some of which will include a Machine Learning (ML) pipeline. Our model includes a new training plane and an AI-aaS plane to deal with the model-development and operational phases of AI applications. We also consider the role of an ML/MKL sandbox in ensuring coherency and consistency in the operation of multiple parallel MKL loops. We present experimental measurement results for three AI-aaS applications deployed on the SAVI testbed: 1. Compressing monitored data in SDI using autoencoders; 2. Traffic monitoring to allocate CPUs resources to VNFs; and 3. Highway segment classification in smart transportation.