 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Gradient Quantization for Data-Parallel SGD
Oct 23, 2020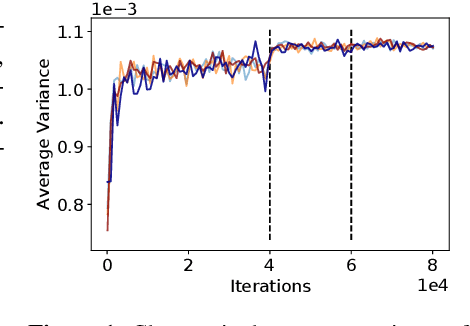
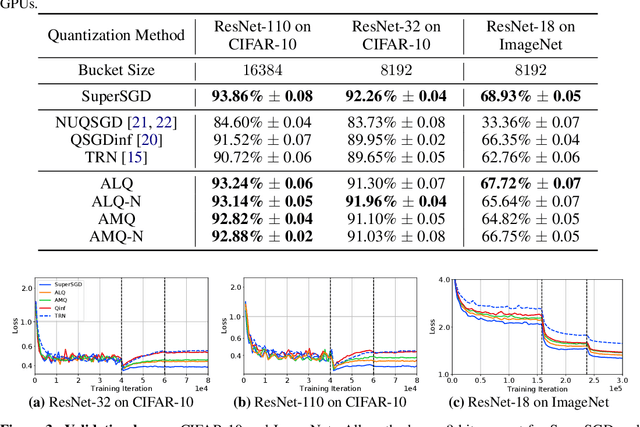
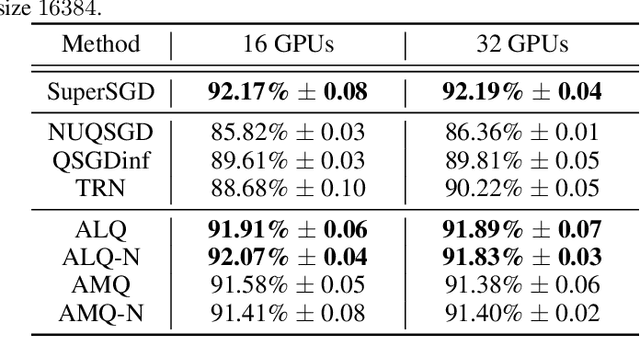
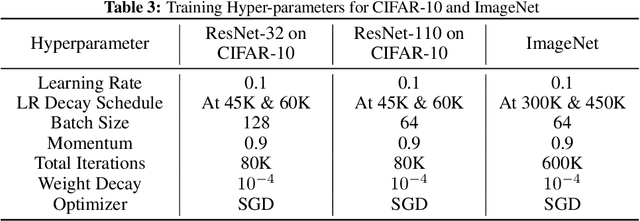
Many communication-efficient variants of SGD use gradient quantization schemes. These schemes are often heuristic and fixed over the course of training. We empirically observe that the statistics of gradients of deep models change during the training. Motivated by this observation, we introduce two adaptive quantization schemes, ALQ and AMQ. In both schemes, processors update their compression schemes in parallel by efficiently computing sufficient statistics of a parametric distribution. We improve the validation accuracy by almost 2% on CIFAR-10 and 1% on ImageNet in challenging low-cost communication setups. Our adaptive methods are also significantly more robust to the choice of hyperparameters.
The Infinite Latent Events Model
May 09, 2012

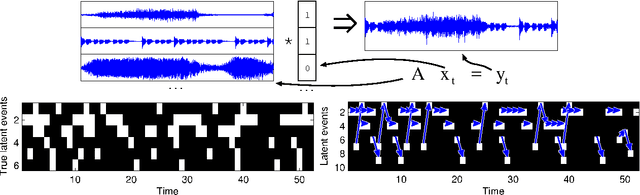
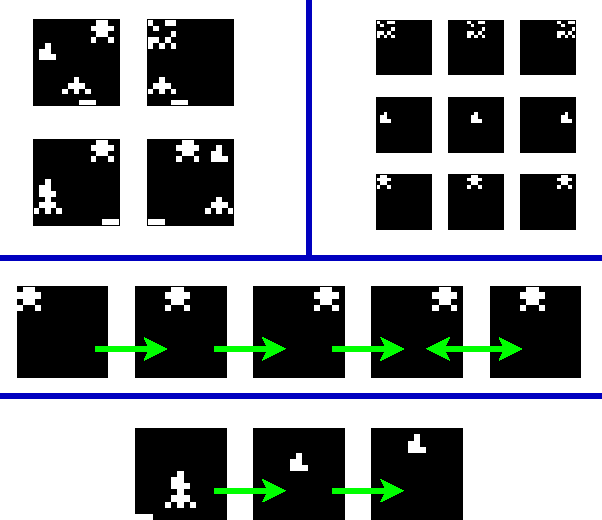
We present the Infinite Latent Events Model, a nonparametric hierarchical Bayesian distribution over infinite dimensional Dynamic Bayesian Networks with binary state representations and noisy-OR-like transitions. The distribution can be used to learn structure in discrete timeseries data by simultaneously inferring a set of latent events, which events fired at each timestep, and how those events are causally linked. We illustrate the model on a sound factorization task, a network topology identification task, and a video game task.
Bayesian Agglomerative Clustering with Coalescents
Jul 04, 2009


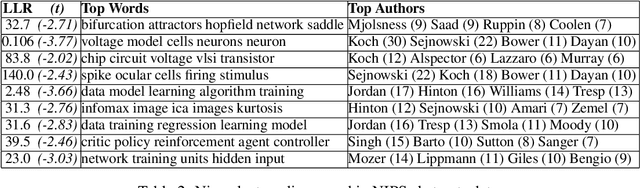
We introduce a new Bayesian model for hierarchical clustering based on a prior over trees called Kingman's coalescent. We develop novel greedy and sequential Monte Carlo inferences which operate in a bottom-up agglomerative fashion. We show experimentally the superiority of our algorithms over others, and demonstrate our approach in document clustering and phylolinguistics.