 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Confusion is Real: GRAPHIC - A Network Science Approach to Confusion Matrices in Deep Learning
Feb 23, 2026Explainable artificial intelligence has emerged as a promising field of research to address reliability concerns in artificial intelligence. Despite significant progress in explainable artificial intelligence, few methods provide a systematic way to visualize and understand how classes are confused and how their relationships evolve as training progresses. In this work, we present GRAPHIC, an architecture-agnostic approach that analyzes neural networks on a class level. It leverages confusion matrices derived from intermediate layers using linear classifiers. We interpret these as adjacency matrices of directed graphs, allowing tools from network science to visualize and quantify learning dynamics across training epochs and intermediate layers. GRAPHIC provides insights into linear class separability, dataset issues, and architectural behavior, revealing, for example, similarities between flatfish and man and labeling ambiguities validated in a human study. In summary, by uncovering real confusions, GRAPHIC offers new perspectives on how neural networks learn. The code is available at https://github.com/Johanna-S-Froehlich/GRAPHIC.
Coding for Computation: Efficient Compression of Neural Networks for Reconfigurable Hardware
Apr 24, 2025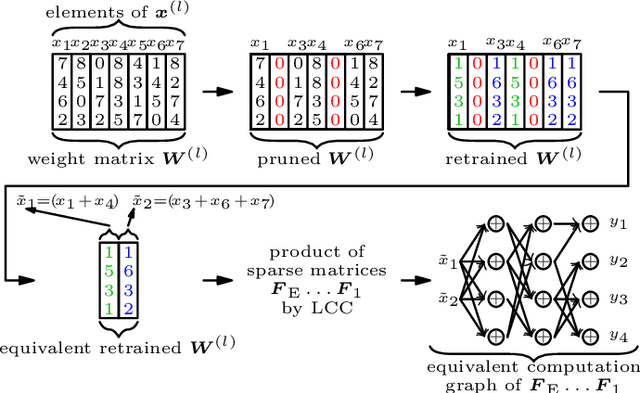
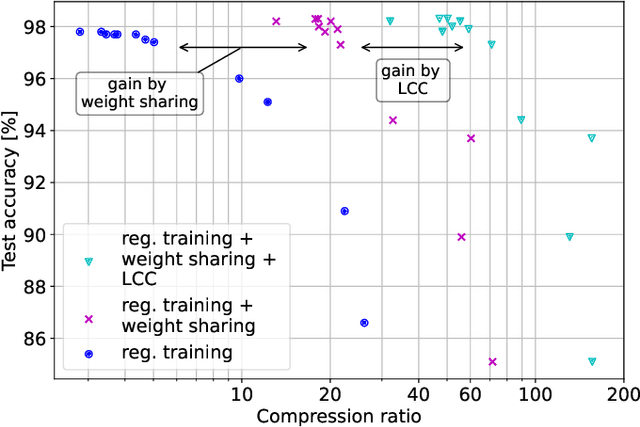
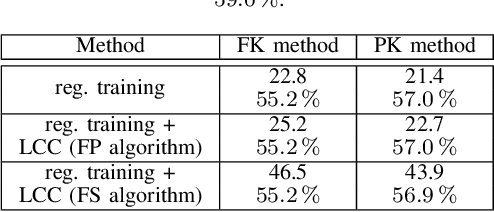
As state of the art neural networks (NNs) continue to grow in size, their resource-efficient implementation becomes ever more important. In this paper, we introduce a compression scheme that reduces the number of computations required for NN inference on reconfigurable hardware such as FPGAs. This is achieved by combining pruning via regularized training, weight sharing and linear computation coding (LCC). Contrary to common NN compression techniques, where the objective is to reduce the memory used for storing the weights of the NNs, our approach is optimized to reduce the number of additions required for inference in a hardware-friendly manner. The proposed scheme achieves competitive performance for simple multilayer perceptrons, as well as for large scale deep NNs such as ResNet-34.
Linear Computation Coding: Exponential Search and Reduced-State Algorithms
Jan 13, 2023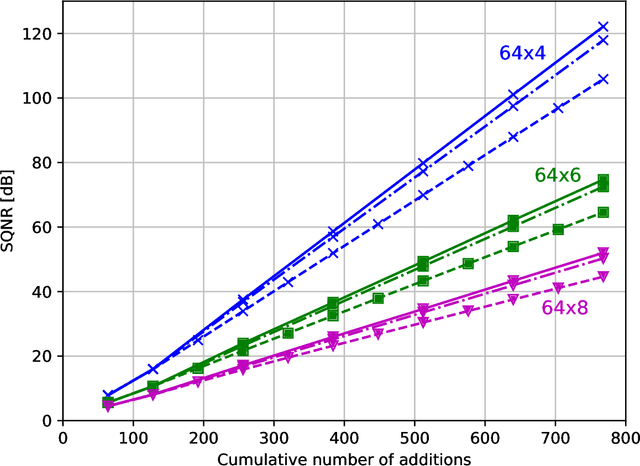
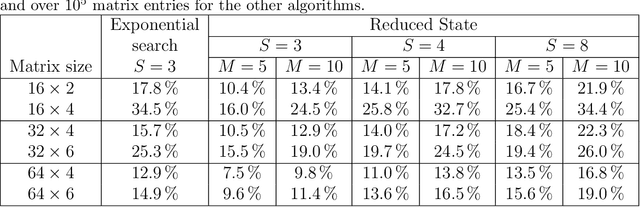
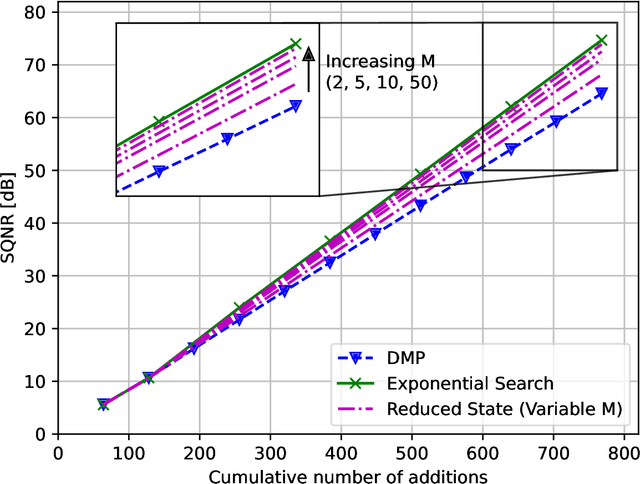
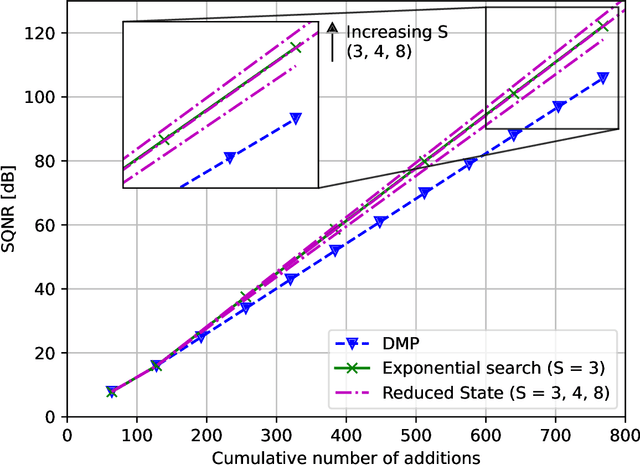
Linear computation coding is concerned with the compression of multidimensional linear functions, i.e. with reducing the computational effort of multiplying an arbitrary vector to an arbitrary, but known, constant matrix. This paper advances over the state-of-the art, that is based on a discrete matching pursuit (DMP) algorithm, by a step-wise optimal search. Offering significant performance gains over DMP, it is however computationally infeasible for large matrices and high accuracy. Therefore, a reduced-state algorithm is introduced that offers performance superior to DMP, while still being computationally feasible even for large matrices. Depending on the matrix size, the performance gain over DMP is on the order of at least 10%.