 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre standard Object Segmentation models sufficient for Learning Affordance Segmentation?
Jul 05, 2021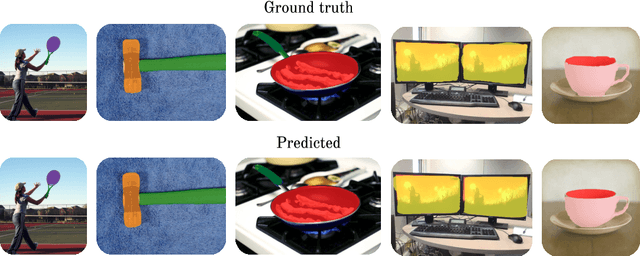
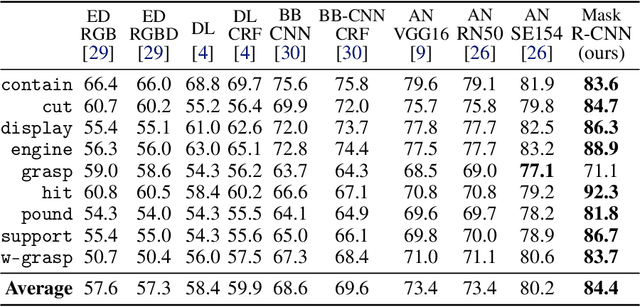
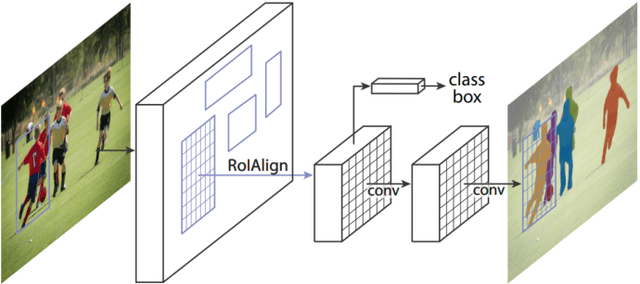
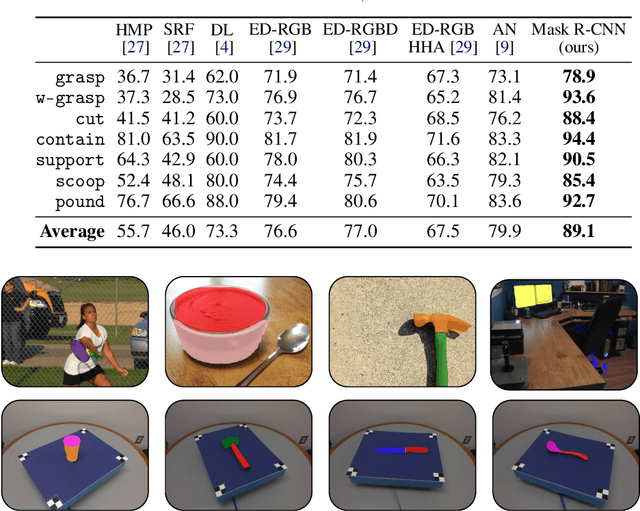
Affordances are the possibilities of actions the environment offers to the individual. Ordinary objects (hammer, knife) usually have many affordances (grasping, pounding, cutting), and detecting these allow artificial agents to understand what are their possibilities in the environment, with obvious application in Robotics. Proposed benchmarks and state-of-the-art prediction models for supervised affordance segmentation are usually modifications of popular object segmentation models such as Mask R-CNN. We observe that theoretically, these popular object segmentation methods should be sufficient for detecting affordances masks. So we ask the question: is it necessary to tailor new architectures to the problem of learning affordances? We show that applying the out-of-the-box Mask R-CNN to the problem of affordances segmentation outperforms the current state-of-the-art. We conclude that the problem of supervised affordance segmentation is included in the problem of object segmentation and argue that better benchmarks for affordance learning should include action capacities.
SCOD: Active Object Detection for Embodied Agents using Sensory Commutativity of Action Sequences
Jul 05, 2021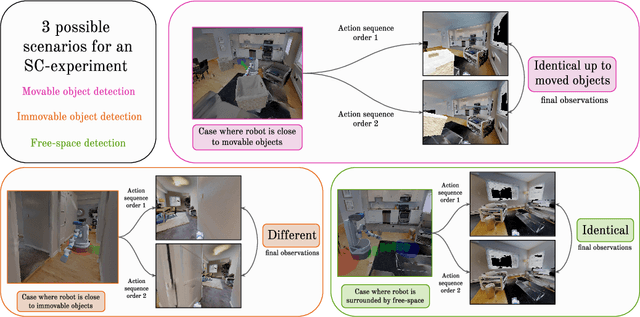
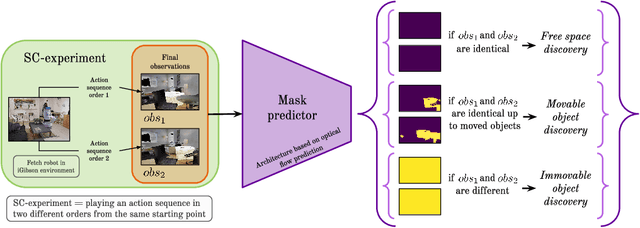
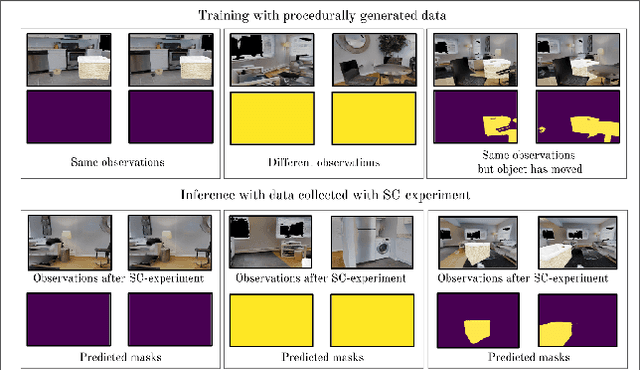

We introduce SCOD (Sensory Commutativity Object Detection), an active method for movable and immovable object detection. SCOD exploits the commutative properties of action sequences, in the scenario of an embodied agent equipped with first-person sensors and a continuous motor space with multiple degrees of freedom. SCOD is based on playing an action sequence in two different orders from the same starting point and comparing the two final observations obtained after each sequence. Our experiments on 3D realistic robotic setups (iGibson) demonstrate the accuracy of SCOD and its generalization to unseen environments and objects. We also successfully apply SCOD on a real robot to further illustrate its generalization properties. With SCOD, we aim at providing a novel way of approaching the problem of object discovery in the context of a naive embodied agent. We provide code and a supplementary video.
On the Sensory Commutativity of Action Sequences for Embodied Agents
Feb 13, 2020



We study perception in the scenario of an embodied agent equipped with first-person sensors and a continuous motor space with multiple degrees of freedom. Inspired by two theories of perception in artificial agents (Higgins (2018), Poincar\'e (1895)) we consider theoretically the commutation properties of action sequences with respect to sensory information perceived by such embodied agent. From the theoretical derivations, we define the Sensory Commutativity Probability criterion which measures how much an agent's degree of freedom affects the environment in embodied scenarios. We empirically illustrate how it can be used to improve sample-efficiency in Reinforcement Learning.
Symmetry-Based Disentangled Representation Learning requires Interaction with Environments
Mar 30, 2019


Finding a generally accepted formal definition of a disentangled representation in the context of an agent behaving in an environment is an important challenge towards the construction of data-efficient autonomous agents. Higgins et al. recently proposed Symmetry-Based Disentangled Representation Learning, a definition based on a characterization of symmetries in the environment using group theory. We build on their work and make observations, theoretical and empirical, that lead us to argue that Symmetry-Based Disentangled Representation Learning cannot only be based on fixed data samples. Agents should interact with the environment to discover its symmetries. All of our experiments can be reproduced on Colab: http://bit.do/eKpqv.
S-TRIGGER: Continual State Representation Learning via Self-Triggered Generative Replay
Feb 25, 2019

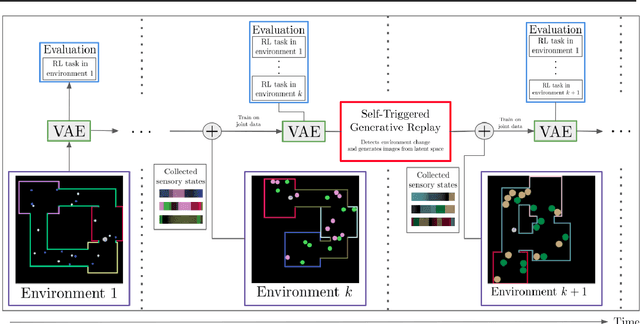
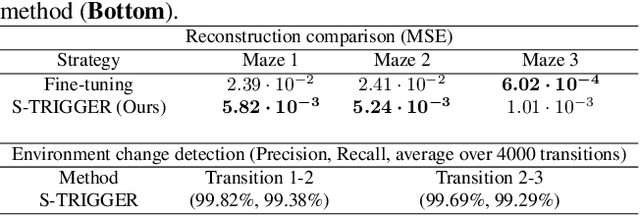
We consider the problem of building a state representation model for control, in a continual learning setting. As the environment changes, the aim is to efficiently compress the sensory state's information without losing past knowledge, and then use Reinforcement Learning on the resulting features for efficient policy learning. To this end, we propose S-TRIGGER, a general method for Continual State Representation Learning applicable to Variational Auto-Encoders and its many variants. The method is based on Generative Replay, i.e. the use of generated samples to maintain past knowledge. It comes along with a statistically sound method for environment change detection, which self-triggers the Generative Replay. Our experiments on VAEs show that S-TRIGGER learns state representations that allows fast and high-performing Reinforcement Learning, while avoiding catastrophic forgetting. The resulting system is capable of autonomously learning new information without using past data and with a bounded system size. Code for our experiments is attached in Appendix.
Generative Models from the perspective of Continual Learning
Dec 21, 2018
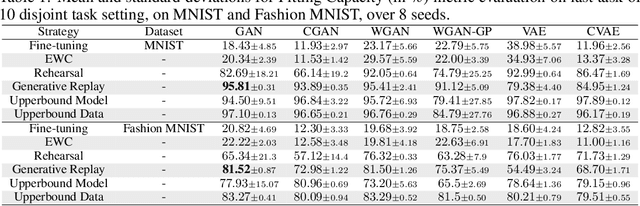


Which generative model is the most suitable for Continual Learning? This paper aims at evaluating and comparing generative models on disjoint sequential image generation tasks. We investigate how several models learn and forget, considering various strategies: rehearsal, regularization, generative replay and fine-tuning. We used two quantitative metrics to estimate the generation quality and memory ability. We experiment with sequential tasks on three commonly used benchmarks for Continual Learning (MNIST, Fashion MNIST and CIFAR10). We found that among all models, the original GAN performs best and among Continual Learning strategies, generative replay outperforms all other methods. Even if we found satisfactory combinations on MNIST and Fashion MNIST, training generative models sequentially on CIFAR10 is particularly instable, and remains a challenge. Our code is available online \footnote{\url{https://github.com/TLESORT/Generative\_Continual\_Learning}}.
Continual State Representation Learning for Reinforcement Learning using Generative Replay
Nov 02, 2018



We consider the problem of building a state representation model in a continual fashion. As the environment changes, the aim is to efficiently compress the sensory state's information without losing past knowledge. The learned features are then fed to a Reinforcement Learning algorithm to learn a policy. We propose to use Variational Auto-Encoders for state representation, and Generative Replay, i.e. the use of generated samples, to maintain past knowledge. We also provide a general and statistically sound method for automatic environment change detection. Our method provides efficient state representation as well as forward transfer, and avoids catastrophic forgetting. The resulting model is capable of incrementally learning information without using past data and with a bounded system size.
Flatland: a Lightweight First-Person 2-D Environment for Reinforcement Learning
Sep 10, 2018
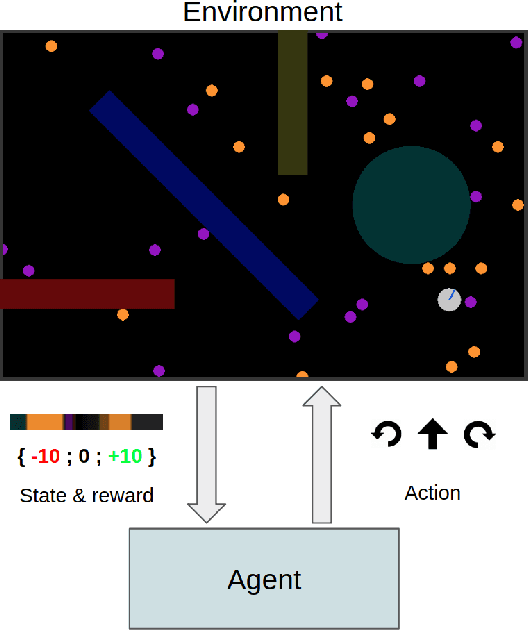
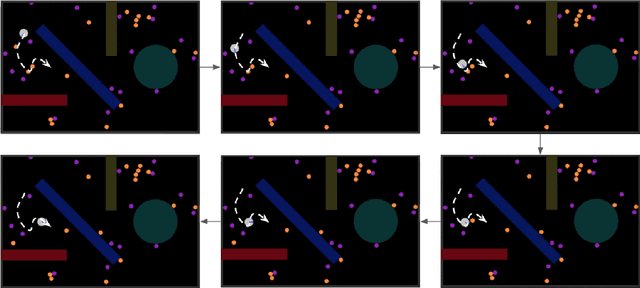
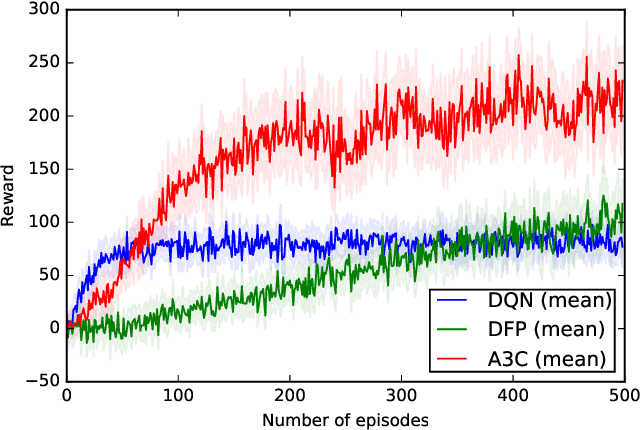
Flatland is a simple, lightweight environment for fast prototyping and testing of reinforcement learning agents. It is of lower complexity compared to similar 3D platforms (e.g. DeepMind Lab or VizDoom), but emulates physical properties of the real world, such as continuity, multi-modal partially-observable states with first-person view and coherent physics. We propose to use it as an intermediary benchmark for problems related to Lifelong Learning. Flatland is highly customizable and offers a wide range of task difficulty to extensively evaluate the properties of artificial agents. We experiment with three reinforcement learning baseline agents and show that they can rapidly solve a navigation task in Flatland. A video of an agent acting in Flatland is available here: https://youtu.be/I5y6Y2ZypdA.