 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion
Mar 18, 2026Diffusion-based image-to-video (I2V) models are increasingly effective, yet they struggle to scale to ultra-high-resolution inputs (e.g., 4K). Generating videos at the model's native resolution often loses fine-grained structure, whereas high-resolution tiled denoising preserves local detail but breaks global layout consistency. This failure mode is particularly severe in the fresco animation setting: monumental artworks containing many distinct characters, objects, and semantically different sub-scenes that must remain spatially coherent over time. We introduce FrescoDiffusion, a training-free method for coherent large-format I2V generation from a single complex image. The key idea is to augment tiled denoising with a precomputed latent prior: we first generate a low-resolution video at the underlying model resolution and upsample its latent trajectory to obtain a global reference that captures long-range temporal and spatial structure. For 4K generation, we compute per-tile noise predictions and fuse them with this reference at every diffusion timestep by minimizing a single weighted least-squares objective in model-output space. The objective combines a standard tile-merging criterion with our regularization term, yielding a closed-form fusion update that strengthens global coherence while retaining fine detail. We additionally provide a spatial regularization variable that enables region-level control over where motion is allowed. Experiments on the VBench-I2V dataset and our proposed fresco I2V dataset show improved global consistency and fidelity over tiled baselines, while being computationally efficient. Our regularization enables explicit controllability of the trade-off between creativity and consistency.
OnlyFlow: Optical Flow based Motion Conditioning for Video Diffusion Models
Nov 15, 2024We consider the problem of text-to-video generation tasks with precise control for various applications such as camera movement control and video-to-video editing. Most methods tacking this problem rely on providing user-defined controls, such as binary masks or camera movement embeddings. In our approach we propose OnlyFlow, an approach leveraging the optical flow firstly extracted from an input video to condition the motion of generated videos. Using a text prompt and an input video, OnlyFlow allows the user to generate videos that respect the motion of the input video as well as the text prompt. This is implemented through an optical flow estimation model applied on the input video, which is then fed to a trainable optical flow encoder. The output feature maps are then injected into the text-to-video backbone model. We perform quantitative, qualitative and user preference studies to show that OnlyFlow positively compares to state-of-the-art methods on a wide range of tasks, even though OnlyFlow was not specifically trained for such tasks. OnlyFlow thus constitutes a versatile, lightweight yet efficient method for controlling motion in text-to-video generation. Models and code will be made available on GitHub and HuggingFace.
Mind-to-Image: Projecting Visual Mental Imagination of the Brain from fMRI
Apr 15, 2024The reconstruction of images observed by subjects from fMRI data collected during visual stimuli has made significant strides in the past decade, thanks to the availability of extensive fMRI datasets and advancements in generative models for image generation. However, the application of visual reconstruction has remained limited. Reconstructing visual imagination presents a greater challenge, with potentially revolutionary applications ranging from aiding individuals with disabilities to verifying witness accounts in court. The primary hurdles in this field are the absence of data collection protocols for visual imagery and the lack of datasets on the subject. Traditionally, fMRI-to-image relies on data collected from subjects exposed to visual stimuli, which poses issues for generating visual imagery based on the difference of brain activity between visual stimulation and visual imagery. For the first time, we have compiled a substantial dataset (around 6h of scans) on visual imagery along with a proposed data collection protocol. We then train a modified version of an fMRI-to-image model and demonstrate the feasibility of reconstructing images from two modes of imagination: from memory and from pure imagination. This marks an important step towards creating a technology that allow direct reconstruction of visual imagery.
Utility-based Adaptive Teaching Strategies using Bayesian Theory of Mind
Sep 29, 2023Good teachers always tailor their explanations to the learners. Cognitive scientists model this process under the rationality principle: teachers try to maximise the learner's utility while minimising teaching costs. To this end, human teachers seem to build mental models of the learner's internal state, a capacity known as Theory of Mind (ToM). Inspired by cognitive science, we build on Bayesian ToM mechanisms to design teacher agents that, like humans, tailor their teaching strategies to the learners. Our ToM-equipped teachers construct models of learners' internal states from observations and leverage them to select demonstrations that maximise the learners' rewards while minimising teaching costs. Our experiments in simulated environments demonstrate that learners taught this way are more efficient than those taught in a learner-agnostic way. This effect gets stronger when the teacher's model of the learner better aligns with the actual learner's state, either using a more accurate prior or after accumulating observations of the learner's behaviour. This work is a first step towards social machines that teach us and each other, see https://teacher-with-tom.github.io.
Enhancing Agent Communication and Learning through Action and Language
Aug 28, 2023We introduce a novel category of GC-agents capable of functioning as both teachers and learners. Leveraging action-based demonstrations and language-based instructions, these agents enhance communication efficiency. We investigate the incorporation of pedagogy and pragmatism, essential elements in human communication and goal achievement, enhancing the agents' teaching and learning capabilities. Furthermore, we explore the impact of combining communication modes (action and language) on learning outcomes, highlighting the benefits of a multi-modal approach.
Overcoming Referential Ambiguity in Language-Guided Goal-Conditioned Reinforcement Learning
Sep 26, 2022
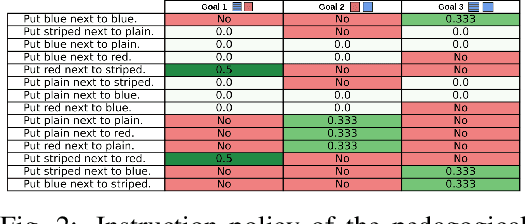
Teaching an agent to perform new tasks using natural language can easily be hindered by ambiguities in interpretation. When a teacher provides an instruction to a learner about an object by referring to its features, the learner can misunderstand the teacher's intentions, for instance if the instruction ambiguously refer to features of the object, a phenomenon called referential ambiguity. We study how two concepts derived from cognitive sciences can help resolve those referential ambiguities: pedagogy (selecting the right instructions) and pragmatism (learning the preferences of the other agents using inductive reasoning). We apply those ideas to a teacher/learner setup with two artificial agents on a simulated robotic task (block-stacking). We show that these concepts improve sample efficiency for training the learner.
Pragmatically Learning from Pedagogical Demonstrations in Multi-Goal Environments
Jun 09, 2022
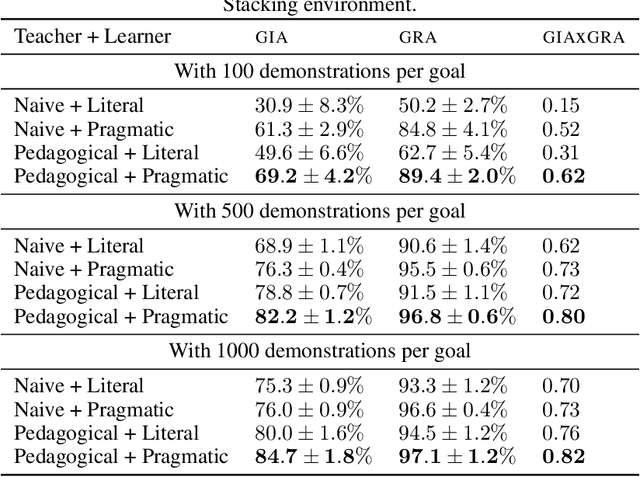

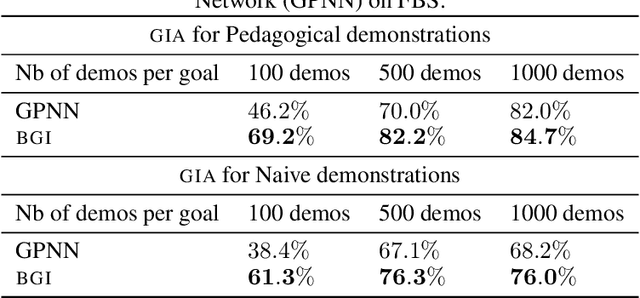
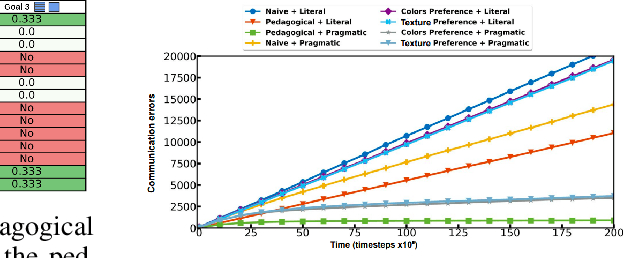
Learning from demonstration methods usually leverage close to optimal demonstrations to accelerate training. By contrast, when demonstrating a task, human teachers deviate from optimal demonstrations and pedagogically modify their behavior by giving demonstrations that best disambiguate the goal they want to demonstrate. Analogously, human learners excel at pragmatically inferring the intent of the teacher, facilitating communication between the two agents. These mechanisms are critical in the few demonstrations regime, where inferring the goal is more difficult. In this paper, we implement pedagogy and pragmatism mechanisms by leveraging a Bayesian model of goal inference from demonstrations. We highlight the benefits of this model in multi-goal teacher-learner setups with two artificial agents that learn with goal-conditioned Reinforcement Learning. We show that combining a pedagogical teacher and a pragmatic learner results in faster learning and reduced goal ambiguity over standard learning from demonstrations, especially in the few demonstrations regime.
Pedagogical Demonstrations and Pragmatic Learning in Artificial Tutor-Learner Interactions
Feb 28, 2022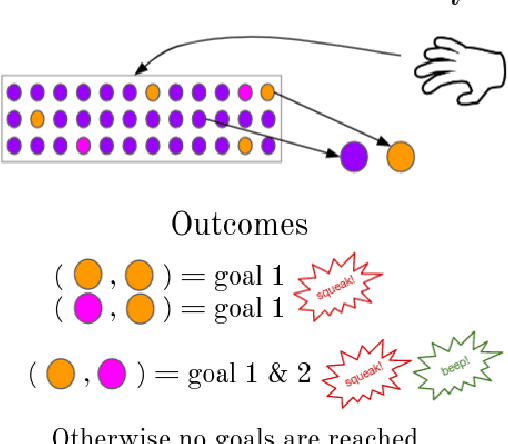
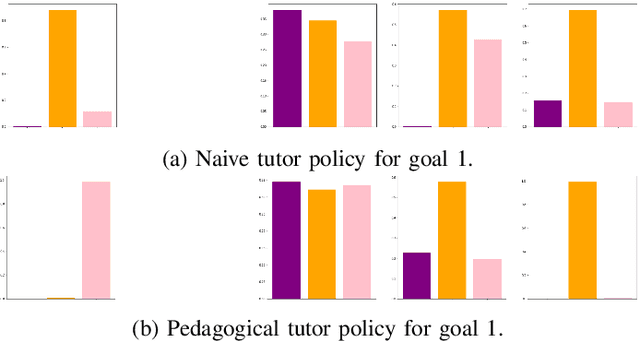
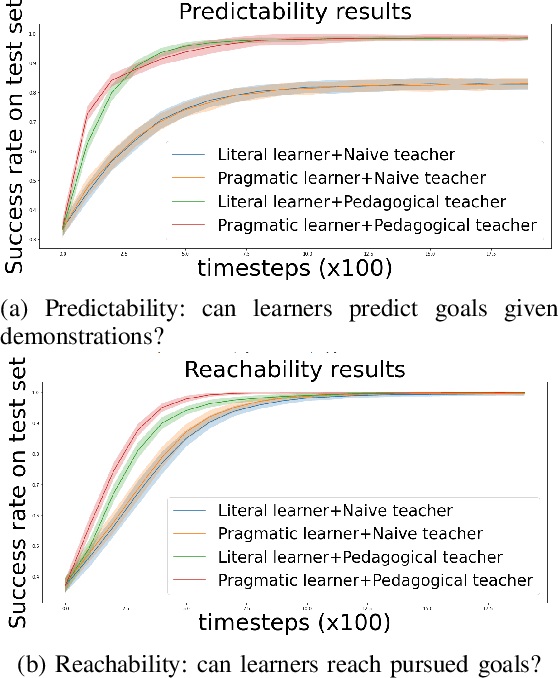
When demonstrating a task, human tutors pedagogically modify their behavior by either "showing" the task rather than just "doing" it (exaggerating on relevant parts of the demonstration) or by giving demonstrations that best disambiguate the communicated goal. Analogously, human learners pragmatically infer the communicative intent of the tutor: they interpret what the tutor is trying to teach them and deduce relevant information for learning. Without such mechanisms, traditional Learning from Demonstration (LfD) algorithms will consider such demonstrations as sub-optimal. In this paper, we investigate the implementation of such mechanisms in a tutor-learner setup where both participants are artificial agents in an environment with multiple goals. Using pedagogy from the tutor and pragmatism from the learner, we show substantial improvements over standard learning from demonstrations.
Are standard Object Segmentation models sufficient for Learning Affordance Segmentation?
Jul 05, 2021
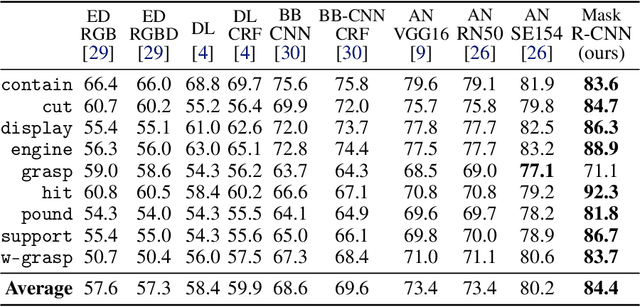
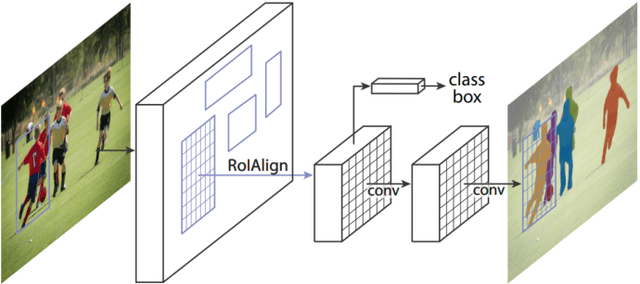
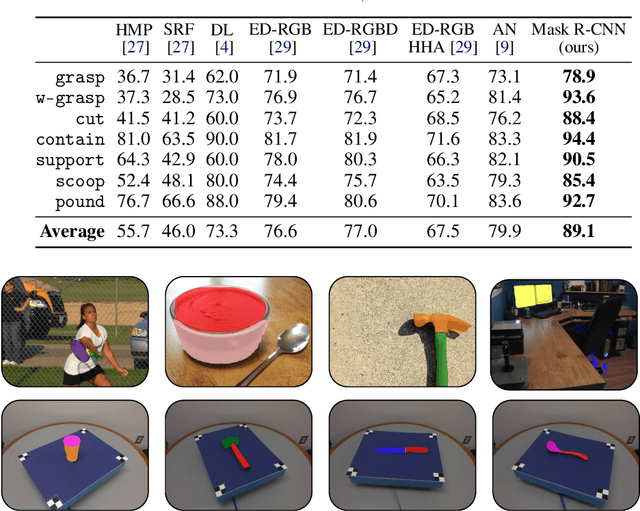
Affordances are the possibilities of actions the environment offers to the individual. Ordinary objects (hammer, knife) usually have many affordances (grasping, pounding, cutting), and detecting these allow artificial agents to understand what are their possibilities in the environment, with obvious application in Robotics. Proposed benchmarks and state-of-the-art prediction models for supervised affordance segmentation are usually modifications of popular object segmentation models such as Mask R-CNN. We observe that theoretically, these popular object segmentation methods should be sufficient for detecting affordances masks. So we ask the question: is it necessary to tailor new architectures to the problem of learning affordances? We show that applying the out-of-the-box Mask R-CNN to the problem of affordances segmentation outperforms the current state-of-the-art. We conclude that the problem of supervised affordance segmentation is included in the problem of object segmentation and argue that better benchmarks for affordance learning should include action capacities.
SCOD: Active Object Detection for Embodied Agents using Sensory Commutativity of Action Sequences
Jul 05, 2021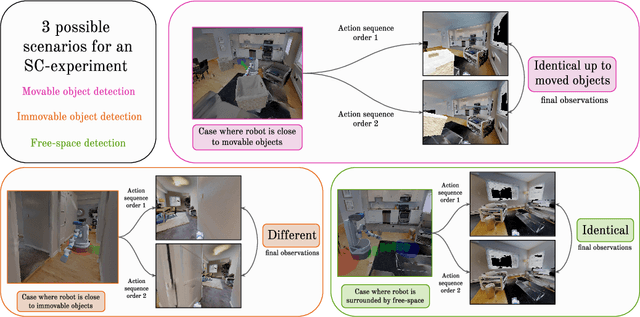
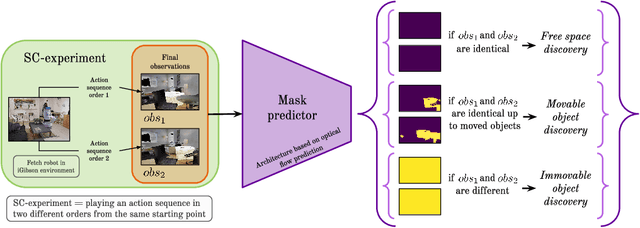
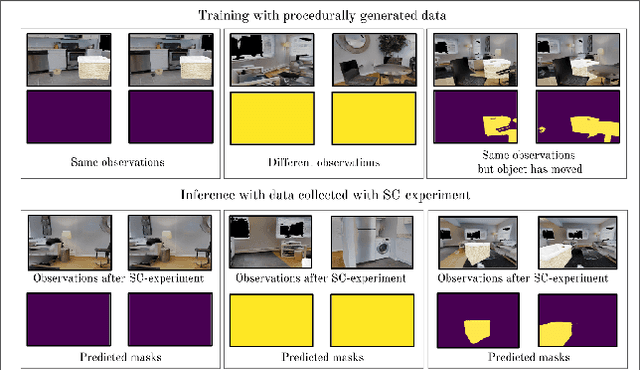

We introduce SCOD (Sensory Commutativity Object Detection), an active method for movable and immovable object detection. SCOD exploits the commutative properties of action sequences, in the scenario of an embodied agent equipped with first-person sensors and a continuous motor space with multiple degrees of freedom. SCOD is based on playing an action sequence in two different orders from the same starting point and comparing the two final observations obtained after each sequence. Our experiments on 3D realistic robotic setups (iGibson) demonstrate the accuracy of SCOD and its generalization to unseen environments and objects. We also successfully apply SCOD on a real robot to further illustrate its generalization properties. With SCOD, we aim at providing a novel way of approaching the problem of object discovery in the context of a naive embodied agent. We provide code and a supplementary video.