 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Geometric Discounts: An Alternative Criterion for Reinforcement Learning
Sep 26, 2022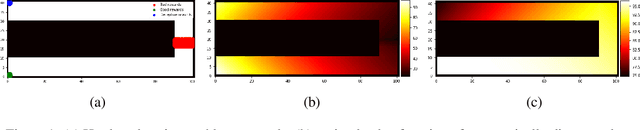

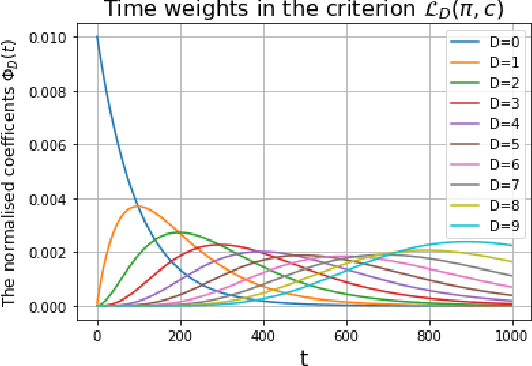
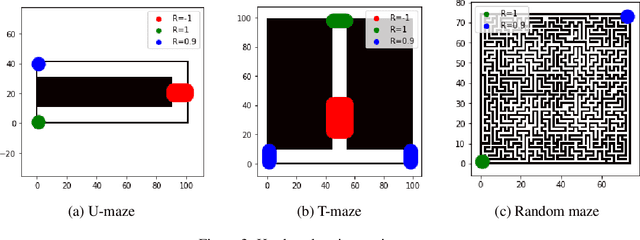
The endeavor of artificial intelligence (AI) is to design autonomous agents capable of achieving complex tasks. Namely, reinforcement learning (RL) proposes a theoretical background to learn optimal behaviors. In practice, RL algorithms rely on geometric discounts to evaluate this optimality. Unfortunately, this does not cover decision processes where future returns are not exponentially less valuable. Depending on the problem, this limitation induces sample-inefficiency (as feed-backs are exponentially decayed) and requires additional curricula/exploration mechanisms (to deal with sparse, deceptive or adversarial rewards). In this paper, we tackle these issues by generalizing the discounted problem formulation with a family of delayed objective functions. We investigate the underlying RL problem to derive: 1) the optimal stationary solution and 2) an approximation of the optimal non-stationary control. The devised algorithms solved hard exploration problems on tabular environment and improved sample-efficiency on classic simulated robotics benchmarks.
Learning Object-Centered Autotelic Behaviors with Graph Neural Networks
Apr 11, 2022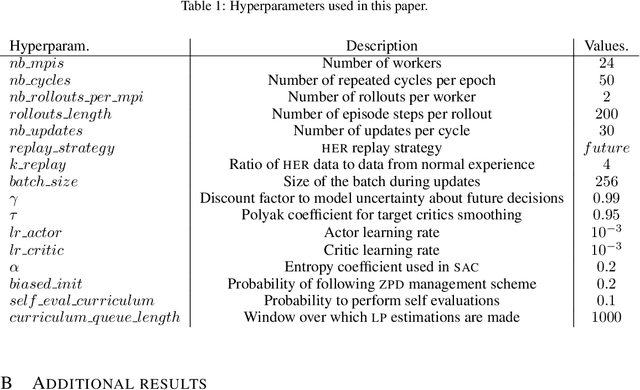
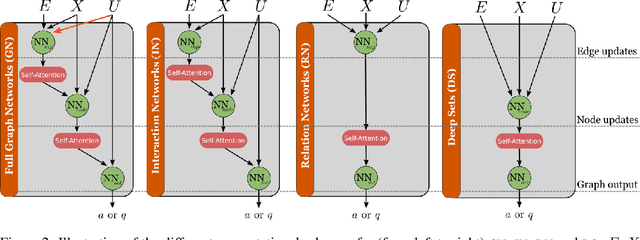
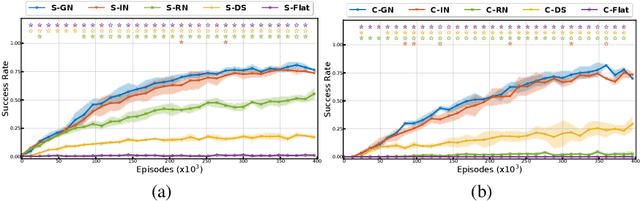
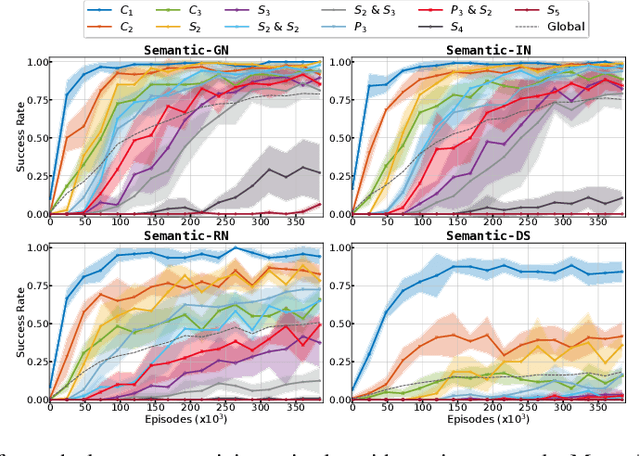
Although humans live in an open-ended world and endlessly face new challenges, they do not have to learn from scratch each time they face the next one. Rather, they have access to a handful of previously learned skills, which they rapidly adapt to new situations. In artificial intelligence, autotelic agents, which are intrinsically motivated to represent and set their own goals, exhibit promising skill adaptation capabilities. However, these capabilities are highly constrained by their policy and goal space representations. In this paper, we propose to investigate the impact of these representations on the learning capabilities of autotelic agents. We study different implementations of autotelic agents using four types of Graph Neural Networks policy representations and two types of goal spaces, either geometric or predicate-based. We show that combining object-centered architectures that are expressive enough with semantic relational goals enables an efficient transfer between skills and promotes behavioral diversity. We also release our graph-based implementations to encourage further research in this direction.
Help Me Explore: Minimal Social Interventions for Graph-Based Autotelic Agents
Feb 10, 2022In the quest for autonomous agents learning open-ended repertoires of skills, most works take a Piagetian perspective: learning trajectories are the results of interactions between developmental agents and their physical environment. The Vygotskian perspective, on the other hand, emphasizes the centrality of the socio-cultural environment: higher cognitive functions emerge from transmissions of socio-cultural processes internalized by the agent. This paper argues that both perspectives could be coupled within the learning of autotelic agents to foster their skill acquisition. To this end, we make two contributions: 1) a novel social interaction protocol called Help Me Explore (HME), where autotelic agents can benefit from both individual and socially guided exploration. In social episodes, a social partner suggests goals at the frontier of the learning agent knowledge. In autotelic episodes, agents can either learn to master their own discovered goals or autonomously rehearse failed social goals; 2) GANGSTR, a graph-based autotelic agent for manipulation domains capable of decomposing goals into sequences of intermediate sub-goals. We show that when learning within HME, GANGSTR overcomes its individual learning limits by mastering the most complex configurations (e.g. stacks of 5 blocks) with only few social interventions.
Towards Teachable Autonomous Agents
May 25, 2021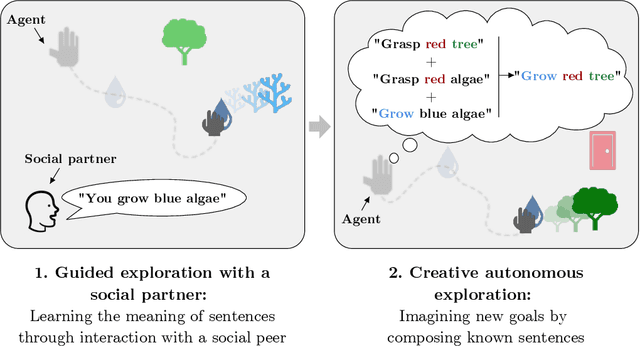
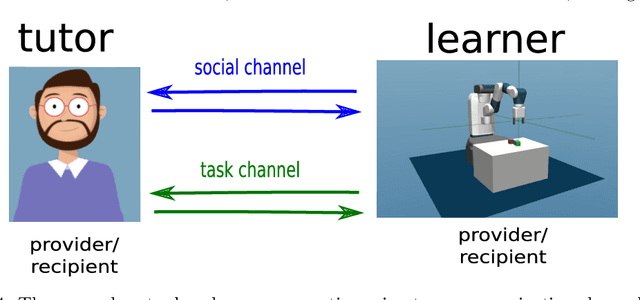
Autonomous discovery and direct instruction are two extreme sources of learning in children, but educational sciences have shown that intermediate approaches such as assisted discovery or guided play resulted in better acquisition of skills. When turning to Artificial Intelligence, the above dichotomy is translated into the distinction between autonomous agents which learn in isolation and interactive learning agents which can be taught by social partners but generally lack autonomy. In between should stand teachable autonomous agents: agents learning from both internal and teaching signals to benefit from the higher efficiency of assisted discovery. Such agents could learn on their own in the real world, but non-expert users could drive their learning behavior towards their expectations. More fundamentally, combining both capabilities might also be a key step towards general intelligence. In this paper we elucidate obstacles along this research line. First, we build on a seminal work of Bruner to extract relevant features of the assisted discovery processes. Second, we describe current research on autotelic agents, i.e. agents equipped with forms of intrinsic motivations that enable them to represent, self-generate and pursue their own goals. We argue that autotelic capabilities are paving the way towards teachable and autonomous agents. Finally, we adopt a social learning perspective on tutoring interactions and we highlight some components that are currently missing to autotelic agents before they can be taught by ordinary people using natural pedagogy, and we provide a list of specific research questions that emerge from this perspective.
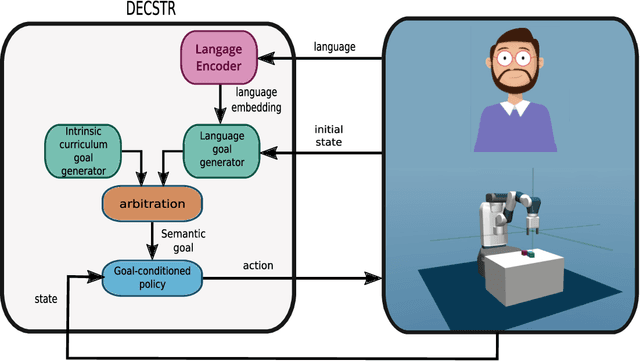
DECSTR: Learning Goal-Directed Abstract Behaviors using Pre-Verbal Spatial Predicates in Intrinsically Motivated Agents
Jun 12, 2020
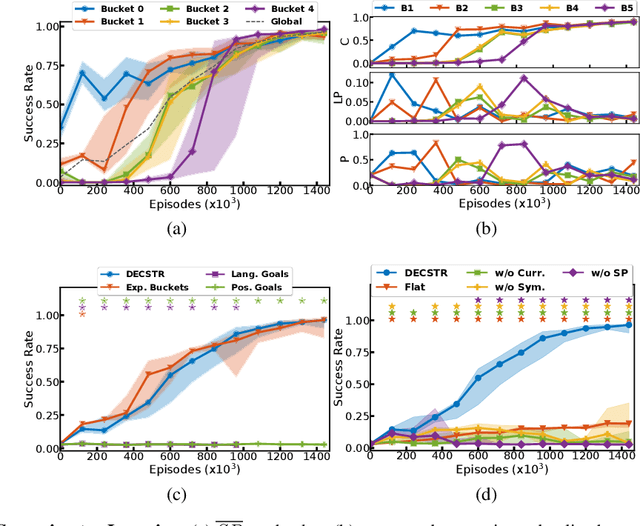
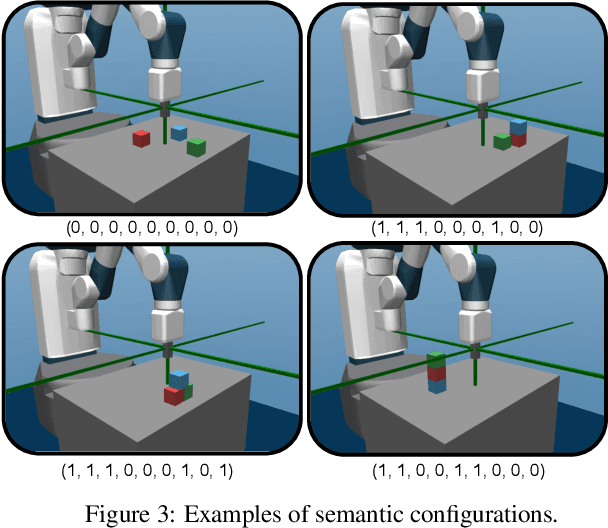
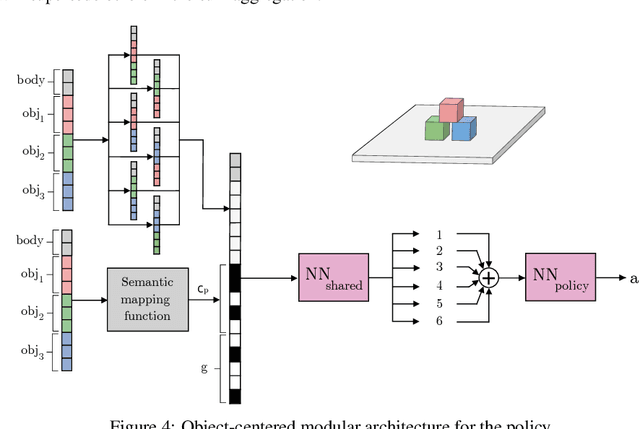
Intrinsically motivated agents freely explore their environment and set their own goals. Such goals are traditionally represented as specific states, but recent works introduced the use of language to facilitate abstraction. Language can, for example, represent goals as sets of general properties that surrounding objects should verify. However, language-conditioned agents are trained simultaneously to understand language and to act, which seems to contrast with how children learn: infants demonstrate goal-oriented behaviors and abstract spatial concepts very early in their development, before language mastery. Guided by these findings from developmental psychology, we introduce a high-level state representation based on natural semantic predicates that describe spatial relations between objects and that are known to be present early in infants. In a robotic manipulation environment, our DECSTR system explores this representation space by manipulating objects, and efficiently learns to achieve any reachable configuration within it. It does so by leveraging an object-centered modular architecture, a symmetry inductive bias, and a new form of automatic curriculum learning for goal selection and policy learning. As with children, language acquisition takes place in a second phase, independently from goal-oriented sensorimotor learning. This is done via a new goal generation module, conditioned on instructions describing expected transformations in object relations. We present ablations studies for each component and highlight several advantages of targeting abstract goals over specific ones. We further show that using this intermediate representation enables efficient language grounding by evaluating agents on sequences of language instructions and their logical combinations.
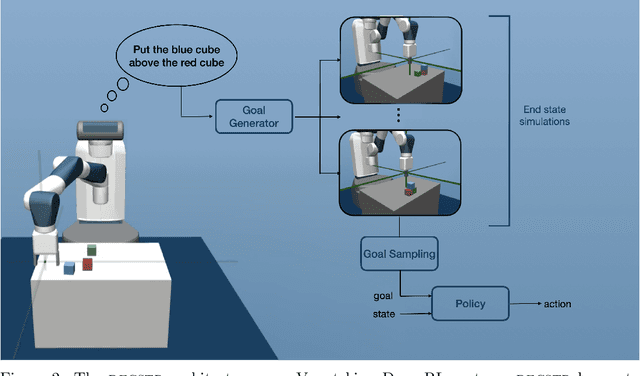
Language-Conditioned Goal Generation: a New Approach to Language Grounding for RL
Jun 12, 2020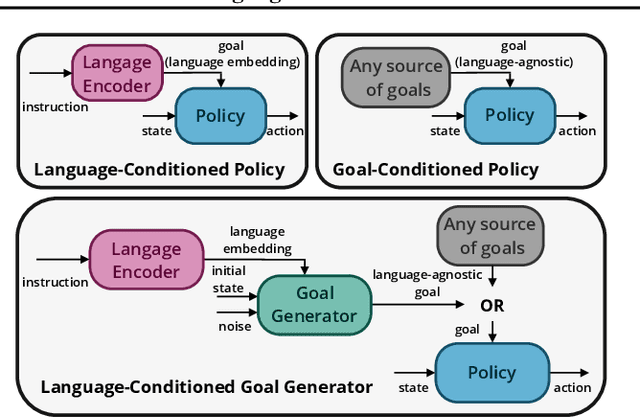
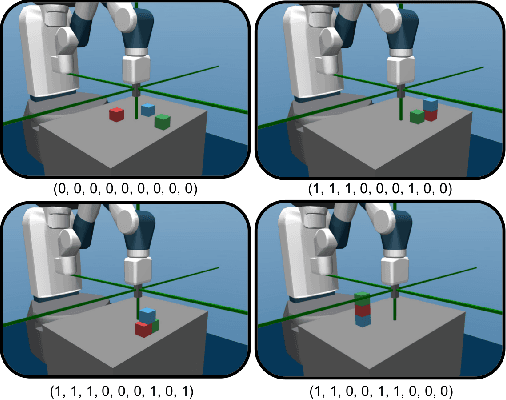
In the real world, linguistic agents are also embodied agents: they perceive and act in the physical world. The notion of Language Grounding questions the interactions between language and embodiment: how do learning agents connect or ground linguistic representations to the physical world ? This question has recently been approached by the Reinforcement Learning community under the framework of instruction-following agents. In these agents, behavioral policies or reward functions are conditioned on the embedding of an instruction expressed in natural language. This paper proposes another approach: using language to condition goal generators. Given any goal-conditioned policy, one could train a language-conditioned goal generator to generate language-agnostic goals for the agent. This method allows to decouple sensorimotor learning from language acquisition and enable agents to demonstrate a diversity of behaviors for any given instruction. We propose a particular instantiation of this approach and demonstrate its benefits.