 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tale of two goals: leveraging sequentiality in multi-goal scenarios
Mar 27, 2025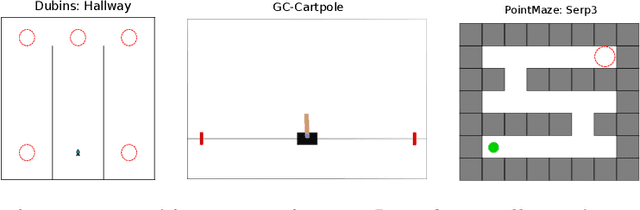



Several hierarchical reinforcement learning methods leverage planning to create a graph or sequences of intermediate goals, guiding a lower-level goal-conditioned (GC) policy to reach some final goals. The low-level policy is typically conditioned on the current goal, with the aim of reaching it as quickly as possible. However, this approach can fail when an intermediate goal can be reached in multiple ways, some of which may make it impossible to continue toward subsequent goals. To address this issue, we introduce two instances of Markov Decision Process (MDP) where the optimization objective favors policies that not only reach the current goal but also subsequent ones. In the first, the agent is conditioned on both the current and final goals, while in the second, it is conditioned on the next two goals in the sequence. We conduct a series of experiments on navigation and pole-balancing tasks in which sequences of intermediate goals are given. By evaluating policies trained with TD3+HER on both the standard GC-MDP and our proposed MDPs, we show that, in most cases, conditioning on the next two goals improves stability and sample efficiency over other approaches.
Single-Reset Divide & Conquer Imitation Learning
Feb 14, 2024Demonstrations are commonly used to speed up the learning process of Deep Reinforcement Learning algorithms. To cope with the difficulty of accessing multiple demonstrations, some algorithms have been developed to learn from a single demonstration. In particular, the Divide & Conquer Imitation Learning algorithms leverage a sequential bias to learn a control policy for complex robotic tasks using a single state-based demonstration. The latest version, DCIL-II demonstrates remarkable sample efficiency. This novel method operates within an extended Goal-Conditioned Reinforcement Learning framework, ensuring compatibility between intermediate and subsequent goals extracted from the demonstration. However, a fundamental limitation arises from the assumption that the system can be reset to specific states along the demonstrated trajectory, confining the application to simulated systems. In response, we introduce an extension called Single-Reset DCIL (SR-DCIL), designed to overcome this constraint by relying on a single initial state reset rather than sequential resets. To address this more challenging setting, we integrate two mechanisms inspired by the Learning from Demonstrations literature, including a Demo-Buffer and Value Cloning, to guide the agent toward compatible success states. In addition, we introduce Approximate Goal Switching to facilitate training to reach goals distant from the reset state. Our paper makes several contributions, highlighting the importance of the reset assumption in DCIL-II, presenting the mechanisms of SR-DCIL variants and evaluating their performance in challenging robotic tasks compared to DCIL-II. In summary, this work offers insights into the significance of reset assumptions in the framework of DCIL and proposes SR-DCIL, a first step toward a versatile algorithm capable of learning control policies under a weaker reset assumption.
Leveraging Sequentiality in Reinforcement Learning from a Single Demonstration
Nov 09, 2022



Deep Reinforcement Learning has been successfully applied to learn robotic control. However, the corresponding algorithms struggle when applied to problems where the agent is only rewarded after achieving a complex task. In this context, using demonstrations can significantly speed up the learning process, but demonstrations can be costly to acquire. In this paper, we propose to leverage a sequential bias to learn control policies for complex robotic tasks using a single demonstration. To do so, our method learns a goal-conditioned policy to control a system between successive low-dimensional goals. This sequential goal-reaching approach raises a problem of compatibility between successive goals: we need to ensure that the state resulting from reaching a goal is compatible with the achievement of the following goals. To tackle this problem, we present a new algorithm called DCIL-II. We show that DCIL-II can solve with unprecedented sample efficiency some challenging simulated tasks such as humanoid locomotion and stand-up as well as fast running with a simulated Cassie robot. Our method leveraging sequentiality is a step towards the resolution of complex robotic tasks under minimal specification effort, a key feature for the next generation of autonomous robots.
Help Me Explore: Minimal Social Interventions for Graph-Based Autotelic Agents
Feb 10, 2022In the quest for autonomous agents learning open-ended repertoires of skills, most works take a Piagetian perspective: learning trajectories are the results of interactions between developmental agents and their physical environment. The Vygotskian perspective, on the other hand, emphasizes the centrality of the socio-cultural environment: higher cognitive functions emerge from transmissions of socio-cultural processes internalized by the agent. This paper argues that both perspectives could be coupled within the learning of autotelic agents to foster their skill acquisition. To this end, we make two contributions: 1) a novel social interaction protocol called Help Me Explore (HME), where autotelic agents can benefit from both individual and socially guided exploration. In social episodes, a social partner suggests goals at the frontier of the learning agent knowledge. In autotelic episodes, agents can either learn to master their own discovered goals or autonomously rehearse failed social goals; 2) GANGSTR, a graph-based autotelic agent for manipulation domains capable of decomposing goals into sequences of intermediate sub-goals. We show that when learning within HME, GANGSTR overcomes its individual learning limits by mastering the most complex configurations (e.g. stacks of 5 blocks) with only few social interventions.