 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Reset Divide & Conquer Imitation Learning
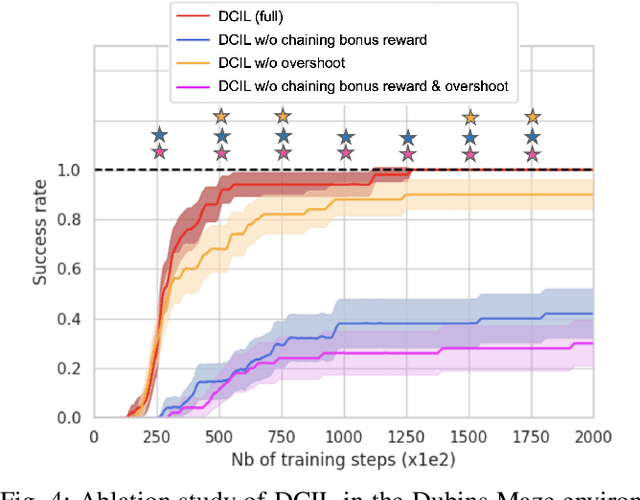
Feb 14, 2024Demonstrations are commonly used to speed up the learning process of Deep Reinforcement Learning algorithms. To cope with the difficulty of accessing multiple demonstrations, some algorithms have been developed to learn from a single demonstration. In particular, the Divide & Conquer Imitation Learning algorithms leverage a sequential bias to learn a control policy for complex robotic tasks using a single state-based demonstration. The latest version, DCIL-II demonstrates remarkable sample efficiency. This novel method operates within an extended Goal-Conditioned Reinforcement Learning framework, ensuring compatibility between intermediate and subsequent goals extracted from the demonstration. However, a fundamental limitation arises from the assumption that the system can be reset to specific states along the demonstrated trajectory, confining the application to simulated systems. In response, we introduce an extension called Single-Reset DCIL (SR-DCIL), designed to overcome this constraint by relying on a single initial state reset rather than sequential resets. To address this more challenging setting, we integrate two mechanisms inspired by the Learning from Demonstrations literature, including a Demo-Buffer and Value Cloning, to guide the agent toward compatible success states. In addition, we introduce Approximate Goal Switching to facilitate training to reach goals distant from the reset state. Our paper makes several contributions, highlighting the importance of the reset assumption in DCIL-II, presenting the mechanisms of SR-DCIL variants and evaluating their performance in challenging robotic tasks compared to DCIL-II. In summary, this work offers insights into the significance of reset assumptions in the framework of DCIL and proposes SR-DCIL, a first step toward a versatile algorithm capable of learning control policies under a weaker reset assumption.
Leveraging Sequentiality in Reinforcement Learning from a Single Demonstration
Nov 09, 2022



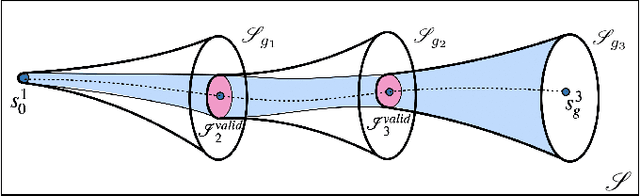
Deep Reinforcement Learning has been successfully applied to learn robotic control. However, the corresponding algorithms struggle when applied to problems where the agent is only rewarded after achieving a complex task. In this context, using demonstrations can significantly speed up the learning process, but demonstrations can be costly to acquire. In this paper, we propose to leverage a sequential bias to learn control policies for complex robotic tasks using a single demonstration. To do so, our method learns a goal-conditioned policy to control a system between successive low-dimensional goals. This sequential goal-reaching approach raises a problem of compatibility between successive goals: we need to ensure that the state resulting from reaching a goal is compatible with the achievement of the following goals. To tackle this problem, we present a new algorithm called DCIL-II. We show that DCIL-II can solve with unprecedented sample efficiency some challenging simulated tasks such as humanoid locomotion and stand-up as well as fast running with a simulated Cassie robot. Our method leveraging sequentiality is a step towards the resolution of complex robotic tasks under minimal specification effort, a key feature for the next generation of autonomous robots.
Divide & Conquer Imitation Learning
Apr 15, 2022
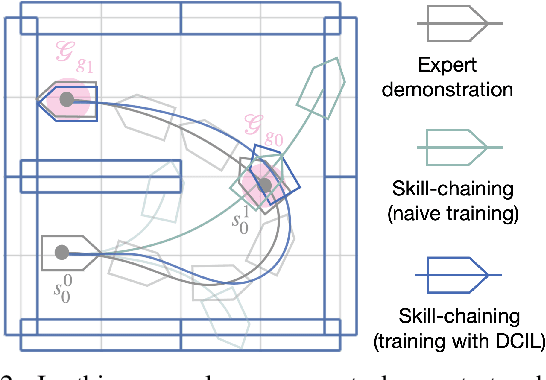
When cast into the Deep Reinforcement Learning framework, many robotics tasks require solving a long horizon and sparse reward problem, where learning algorithms struggle. In such context, Imitation Learning (IL) can be a powerful approach to bootstrap the learning process. However, most IL methods require several expert demonstrations which can be prohibitively difficult to acquire. Only a handful of IL algorithms have shown efficiency in the context of an extreme low expert data regime where a single expert demonstration is available. In this paper, we present a novel algorithm designed to imitate complex robotic tasks from the states of an expert trajectory. Based on a sequential inductive bias, our method divides the complex task into smaller skills. The skills are learned into a goal-conditioned policy that is able to solve each skill individually and chain skills to solve the entire task. We show that our method imitates a non-holonomic navigation task and scales to a complex simulated robotic manipulation task with very high sample efficiency.
Selection-Expansion: A Unifying Framework for Motion-Planning and Diversity Search Algorithms
Apr 10, 2021



Reinforcement learning agents need a reward signal to learn successful policies. When this signal is sparse or the corresponding gradient is deceptive, such agents need a dedicated mechanism to efficiently explore their search space without relying on the reward. Looking for a large diversity of behaviors or using Motion Planning (MP) algorithms are two options in this context. In this paper, we build on the common roots between these two options to investigate the properties of two diversity search algorithms, the Novelty Search and the Goal Exploration Process algorithms. These algorithms look for diversity in an outcome space or behavioral space which is generally hand-designed to represent what matters for a given task. The relation to MP algorithms reveals that the smoothness, or lack of smoothness of the mapping between the policy parameter space and the outcome space plays a key role in the search efficiency. In particular, we show empirically that, if the mapping is smooth enough, i.e. if two close policies in the parameter space lead to similar outcomes, then diversity algorithms tend to inherit exploration properties of MP algorithms. By contrast, if it is not, diversity algorithms lose these properties and their performance strongly depends on specific heuristics, notably filtering mechanisms that discard some of the explored policies.