 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tale of two goals: leveraging sequentiality in multi-goal scenarios
Mar 27, 2025Several hierarchical reinforcement learning methods leverage planning to create a graph or sequences of intermediate goals, guiding a lower-level goal-conditioned (GC) policy to reach some final goals. The low-level policy is typically conditioned on the current goal, with the aim of reaching it as quickly as possible. However, this approach can fail when an intermediate goal can be reached in multiple ways, some of which may make it impossible to continue toward subsequent goals. To address this issue, we introduce two instances of Markov Decision Process (MDP) where the optimization objective favors policies that not only reach the current goal but also subsequent ones. In the first, the agent is conditioned on both the current and final goals, while in the second, it is conditioned on the next two goals in the sequence. We conduct a series of experiments on navigation and pole-balancing tasks in which sequences of intermediate goals are given. By evaluating policies trained with TD3+HER on both the standard GC-MDP and our proposed MDPs, we show that, in most cases, conditioning on the next two goals improves stability and sample efficiency over other approaches.
Learning to explore when mistakes are not allowed
Feb 19, 2025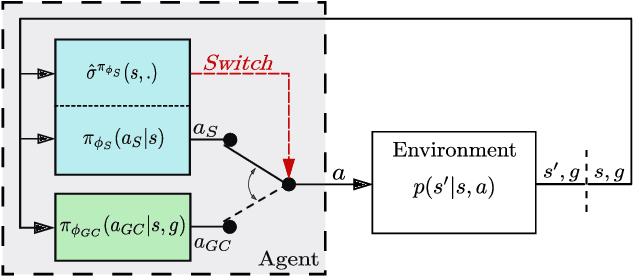

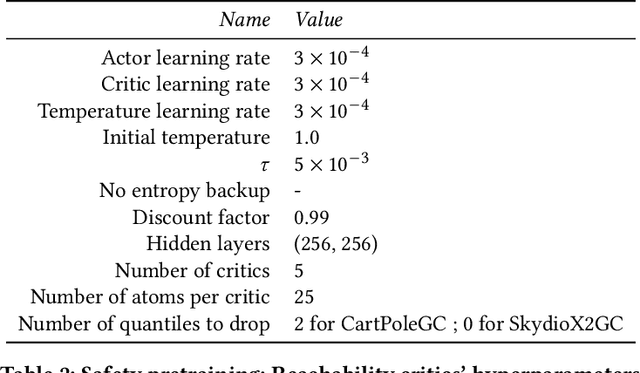
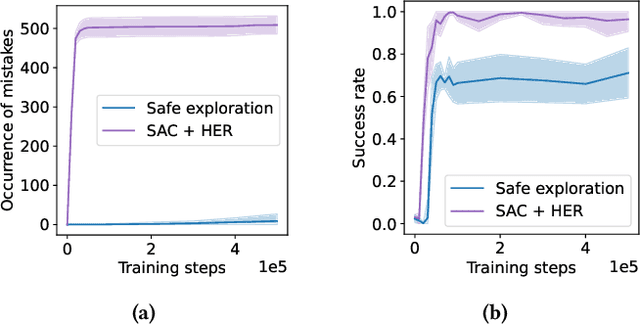
Goal-Conditioned Reinforcement Learning (GCRL) provides a versatile framework for developing unified controllers capable of handling wide ranges of tasks, exploring environments, and adapting behaviors. However, its reliance on trial-and-error poses challenges for real-world applications, as errors can result in costly and potentially damaging consequences. To address the need for safer learning, we propose a method that enables agents to learn goal-conditioned behaviors that explore without the risk of making harmful mistakes. Exploration without risks can seem paradoxical, but environment dynamics are often uniform in space, therefore a policy trained for safety without exploration purposes can still be exploited globally. Our proposed approach involves two distinct phases. First, during a pretraining phase, we employ safe reinforcement learning and distributional techniques to train a safety policy that actively tries to avoid failures in various situations. In the subsequent safe exploration phase, a goal-conditioned (GC) policy is learned while ensuring safety. To achieve this, we implement an action-selection mechanism leveraging the previously learned distributional safety critics to arbitrate between the safety policy and the GC policy, ensuring safe exploration by switching to the safety policy when needed. We evaluate our method in simulated environments and demonstrate that it not only provides substantial coverage of the goal space but also reduces the occurrence of mistakes to a minimum, in stark contrast to traditional GCRL approaches. Additionally, we conduct an ablation study and analyze failure modes, offering insights for future research directions.
Enhancing Robustness in Language-Driven Robotics: A Modular Approach to Failure Reduction
Nov 08, 2024



Recent advances in large language models (LLMs) have led to significant progress in robotics, enabling embodied agents to better understand and execute open-ended tasks. However, existing approaches using LLMs face limitations in grounding their outputs within the physical environment and aligning with the capabilities of the robot. This challenge becomes even more pronounced with smaller language models, which are more computationally efficient but less robust in task planning and execution. In this paper, we present a novel modular architecture designed to enhance the robustness of LLM-driven robotics by addressing these grounding and alignment issues. We formalize the task planning problem within a goal-conditioned POMDP framework, identify key failure modes in LLM-driven planning, and propose targeted design principles to mitigate these issues. Our architecture introduces an ``expected outcomes'' module to prevent mischaracterization of subgoals and a feedback mechanism to enable real-time error recovery. Experimental results, both in simulation and on physical robots, demonstrate that our approach significantly improves task success rates for pick-and-place and manipulation tasks compared to both larger LLMs and standard baselines. Through hardware experiments, we also demonstrate how our architecture can be run efficiently and locally. This work highlights the potential of smaller, locally-executable LLMs in robotics and provides a scalable, efficient solution for robust task execution.
QDGset: A Large Scale Grasping Dataset Generated with Quality-Diversity
Oct 03, 2024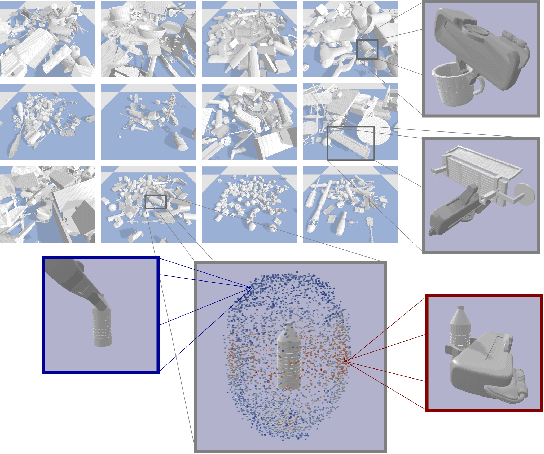
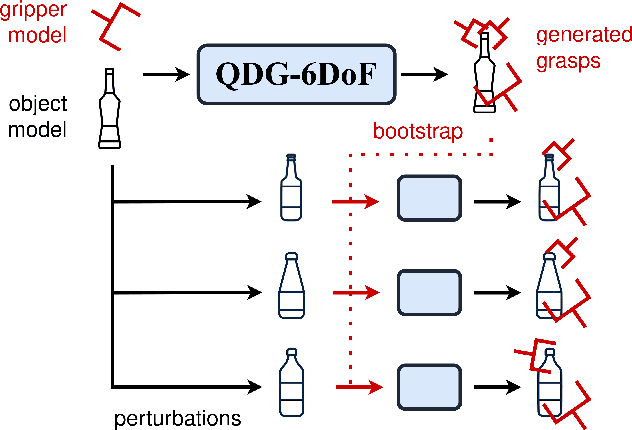
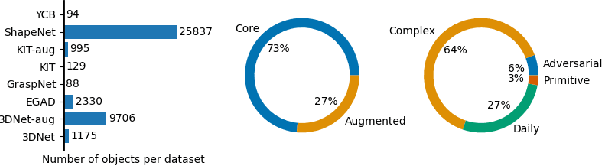
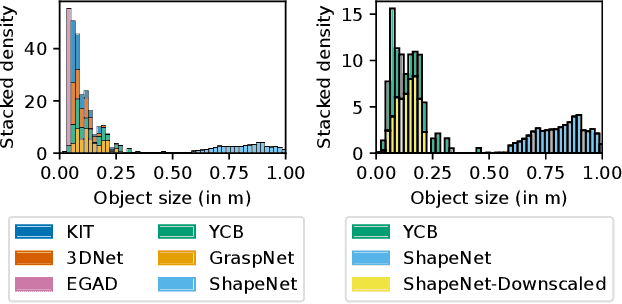
Recent advances in AI have led to significant results in robotic learning, but skills like grasping remain partially solved. Many recent works exploit synthetic grasping datasets to learn to grasp unknown objects. However, those datasets were generated using simple grasp sampling methods using priors. Recently, Quality-Diversity (QD) algorithms have been proven to make grasp sampling significantly more efficient. In this work, we extend QDG-6DoF, a QD framework for generating object-centric grasps, to scale up the production of synthetic grasping datasets. We propose a data augmentation method that combines the transformation of object meshes with transfer learning from previous grasping repertoires. The conducted experiments show that this approach reduces the number of required evaluations per discovered robust grasp by up to 20%. We used this approach to generate QDGset, a dataset of 6DoF grasp poses that contains about 3.5 and 4.5 times more grasps and objects, respectively, than the previous state-of-the-art. Our method allows anyone to easily generate data, eventually contributing to a large-scale collaborative dataset of synthetic grasps.
Speeding up 6-DoF Grasp Sampling with Quality-Diversity
Mar 10, 2024



Recent advances in AI have led to significant results in robotic learning, including natural language-conditioned planning and efficient optimization of controllers using generative models. However, the interaction data remains the bottleneck for generalization. Getting data for grasping is a critical challenge, as this skill is required to complete many manipulation tasks. Quality-Diversity (QD) algorithms optimize a set of solutions to get diverse, high-performing solutions to a given problem. This paper investigates how QD can be combined with priors to speed up the generation of diverse grasps poses in simulation compared to standard 6-DoF grasp sampling schemes. Experiments conducted on 4 grippers with 2-to-5 fingers on standard objects show that QD outperforms commonly used methods by a large margin. Further experiments show that QD optimization automatically finds some efficient priors that are usually hard coded. The deployment of generated grasps on a 2-finger gripper and an Allegro hand shows that the diversity produced maintains sim-to-real transferability. We believe these results to be a significant step toward the generation of large datasets that can lead to robust and generalizing robotic grasping policies.
Domain Randomization for Sim2real Transfer of Automatically Generated Grasping Datasets
Oct 06, 2023



Robotic grasping refers to making a robotic system pick an object by applying forces and torques on its surface. Many recent studies use data-driven approaches to address grasping, but the sparse reward nature of this task made the learning process challenging to bootstrap. To avoid constraining the operational space, an increasing number of works propose grasping datasets to learn from. But most of them are limited to simulations. The present paper investigates how automatically generated grasps can be exploited in the real world. More than 7000 reach-and-grasp trajectories have been generated with Quality-Diversity (QD) methods on 3 different arms and grippers, including parallel fingers and a dexterous hand, and tested in the real world. Conducted analysis on the collected measure shows correlations between several Domain Randomization-based quality criteria and sim-to-real transferability. Key challenges regarding the reality gap for grasping have been identified, stressing matters on which researchers on grasping should focus in the future. A QD approach has finally been proposed for making grasps more robust to domain randomization, resulting in a transfer ratio of 84% on the Franka Research 3 arm.
Learning to Grasp: from Somewhere to Anywhere
Oct 06, 2023



Robotic grasping is still a partially solved, multidisciplinary problem where data-driven techniques play an increasing role. The sparse nature of rewards make the automatic generation of grasping datasets challenging, especially for unconventional morphologies or highly actuated end-effectors. Most approaches for obtaining large-scale datasets rely on numerous human-provided demonstrations or heavily engineered solutions that do not scale well. Recent advances in Quality-Diversity (QD) methods have investigated how to learn object grasping at a specific pose with different robot morphologies. The present work introduces a pipeline for adapting QD-generated trajectories to new object poses. Using an RGB-D data stream, the vision pipeline first detects the targeted object, predicts its 6-DOF pose, and finally tracks it. An automatically generated reach-and-grasp trajectory can then be adapted by projecting it relatively to the object frame. Hundreds of trajectories have been deployed into the real world on several objects and with different robotic setups: a Franka Research 3 with a parallel gripper and a UR5 with a dexterous SIH Schunk hand. The transfer ratio obtained when applying transformation to the object pose matches the one obtained when the object pose matches the simulation, demonstrating the efficiency of the proposed approach.
Automatic Acquisition of a Repertoire of Diverse Grasping Trajectories through Behavior Shaping and Novelty Search
May 17, 2022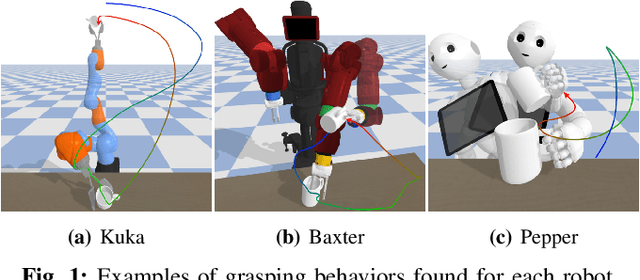
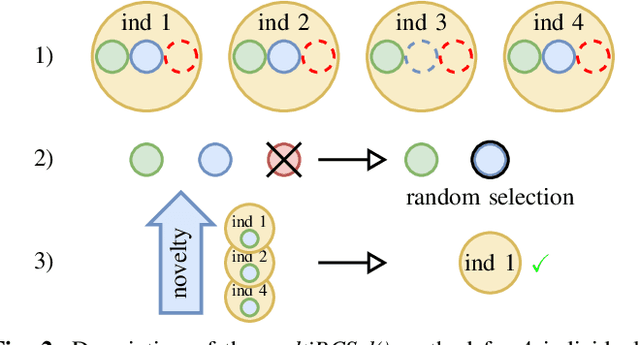
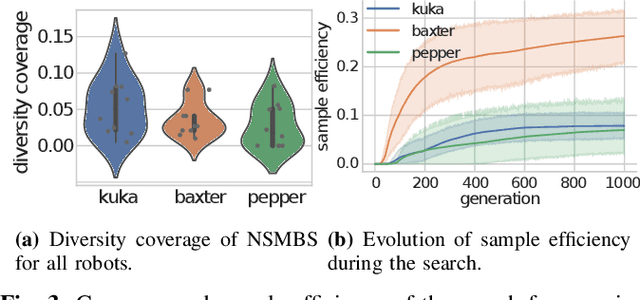
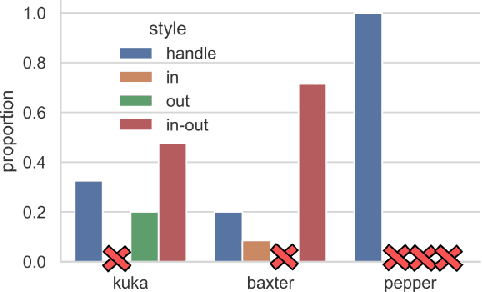
Grasping a particular object may require a dedicated grasping movement that may also be specific to the robot end-effector. No generic and autonomous method does exist to generate these movements without making hypotheses on the robot or on the object. Learning methods could help to autonomously discover relevant grasping movements, but they face an important issue: grasping movements are so rare that a learning method based on exploration has little chance to ever observe an interesting movement, thus creating a bootstrap issue. We introduce an approach to generate diverse grasping movements in order to solve this problem. The movements are generated in simulation, for particular object positions. We test it on several simulated robots: Baxter, Pepper and a Kuka Iiwa arm. Although we show that generated movements actually work on a real Baxter robot, the aim is to use this method to create a large dataset to bootstrap deep learning methods.
Exploratory State Representation Learning
Sep 28, 2021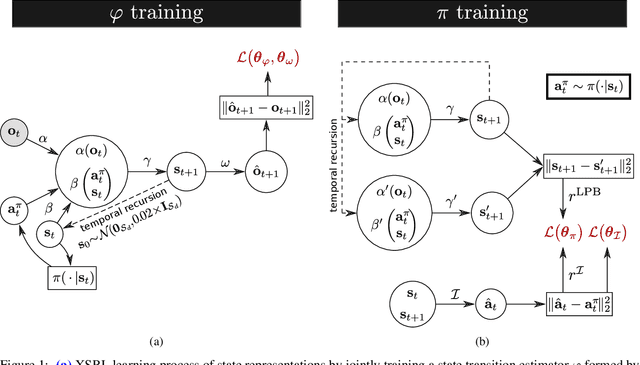
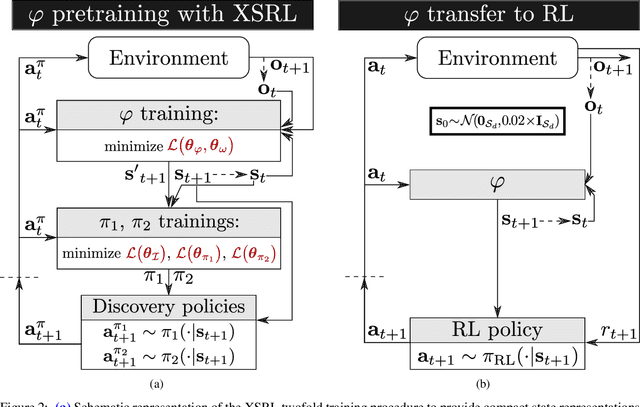


Not having access to compact and meaningful representations is known to significantly increase the complexity of reinforcement learning (RL). For this reason, it can be useful to perform state representation learning (SRL) before tackling RL tasks. However, obtaining a good state representation can only be done if a large diversity of transitions is observed, which can require a difficult exploration, especially if the environment is initially reward-free. To solve the problems of exploration and SRL in parallel, we propose a new approach called XSRL (eXploratory State Representation Learning). On one hand, it jointly learns compact state representations and a state transition estimator which is used to remove unexploitable information from the representations. On the other hand, it continuously trains an inverse model, and adds to the prediction error of this model a $k$-step learning progress bonus to form the maximization objective of a discovery policy. This results in a policy that seeks complex transitions from which the trained models can effectively learn. Our experimental results show that the approach leads to efficient exploration in challenging environments with image observations, and to state representations that significantly accelerate learning in RL tasks.
Selection-Expansion: A Unifying Framework for Motion-Planning and Diversity Search Algorithms
Apr 10, 2021



Reinforcement learning agents need a reward signal to learn successful policies. When this signal is sparse or the corresponding gradient is deceptive, such agents need a dedicated mechanism to efficiently explore their search space without relying on the reward. Looking for a large diversity of behaviors or using Motion Planning (MP) algorithms are two options in this context. In this paper, we build on the common roots between these two options to investigate the properties of two diversity search algorithms, the Novelty Search and the Goal Exploration Process algorithms. These algorithms look for diversity in an outcome space or behavioral space which is generally hand-designed to represent what matters for a given task. The relation to MP algorithms reveals that the smoothness, or lack of smoothness of the mapping between the policy parameter space and the outcome space plays a key role in the search efficiency. In particular, we show empirically that, if the mapping is smooth enough, i.e. if two close policies in the parameter space lead to similar outcomes, then diversity algorithms tend to inherit exploration properties of MP algorithms. By contrast, if it is not, diversity algorithms lose these properties and their performance strongly depends on specific heuristics, notably filtering mechanisms that discard some of the explored policies.