 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploratory State Representation Learning
Sep 28, 2021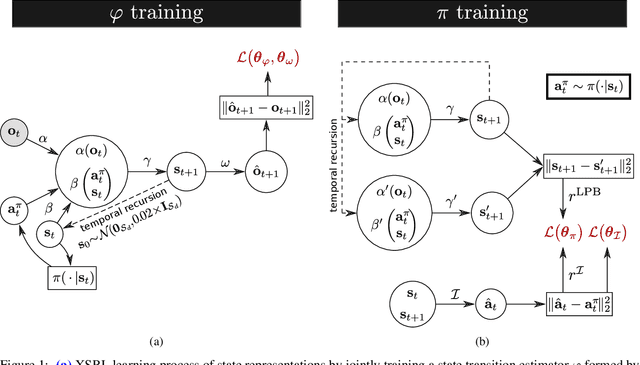
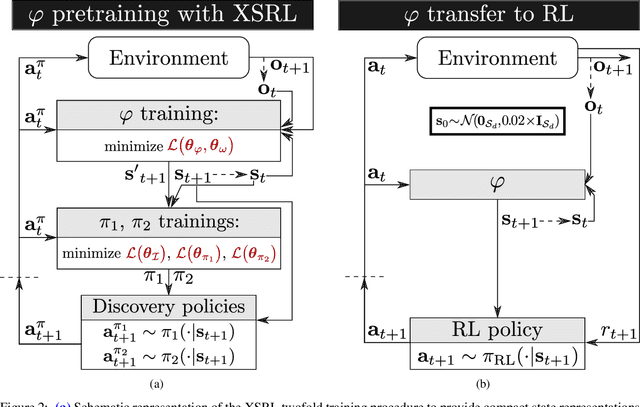


Not having access to compact and meaningful representations is known to significantly increase the complexity of reinforcement learning (RL). For this reason, it can be useful to perform state representation learning (SRL) before tackling RL tasks. However, obtaining a good state representation can only be done if a large diversity of transitions is observed, which can require a difficult exploration, especially if the environment is initially reward-free. To solve the problems of exploration and SRL in parallel, we propose a new approach called XSRL (eXploratory State Representation Learning). On one hand, it jointly learns compact state representations and a state transition estimator which is used to remove unexploitable information from the representations. On the other hand, it continuously trains an inverse model, and adds to the prediction error of this model a $k$-step learning progress bonus to form the maximization objective of a discovery policy. This results in a policy that seeks complex transitions from which the trained models can effectively learn. Our experimental results show that the approach leads to efficient exploration in challenging environments with image observations, and to state representations that significantly accelerate learning in RL tasks.
State Representation Learning from Demonstration
Sep 15, 2019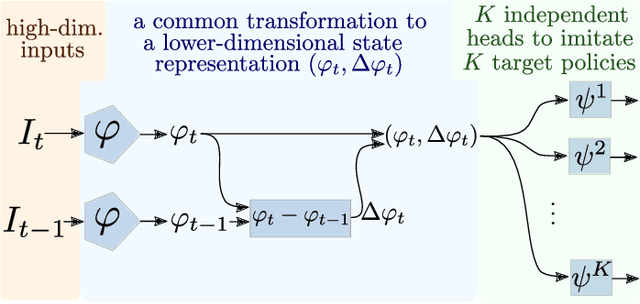
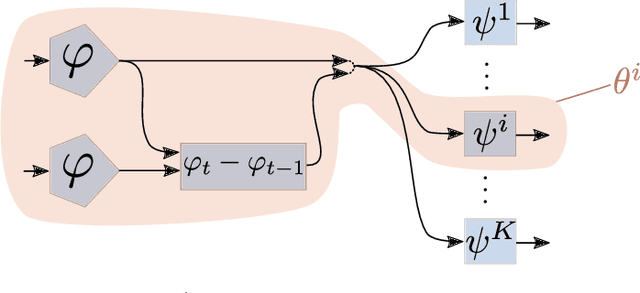

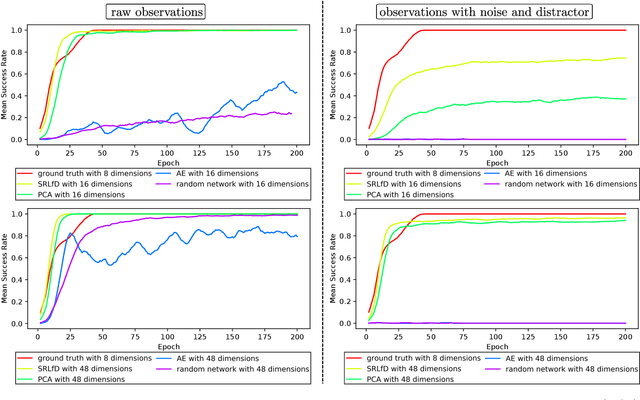
In a context where several policies can be observed as black boxes on different instances of a control task, we propose a method to derive a state representation that can be relied on to reproduce any of the observed policies. We do so via imitation learning on a multi-head neural network consisting of a first part that outputs a common state representation and then one head per policy to imitate. If the demonstrations contain enough diversity, the state representation is general and can be transferred to learn new instances of the task. We present a proof of concept with experimental results on a simulated 2D robotic arm performing a reaching task, with noisy image inputs containing a distractor, and show that the state representations learned provide a greater speed up to end-to-end reinforcement learning on new instances of the task than with other classical representations.