 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Representation Learning from Demonstration
Sep 15, 2019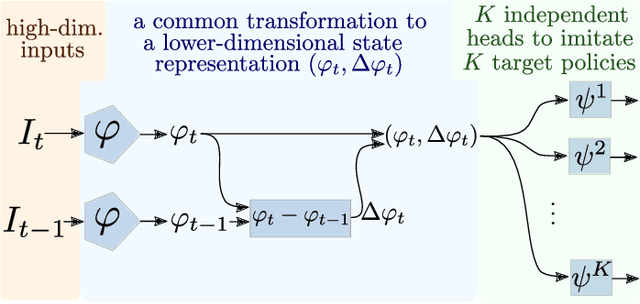
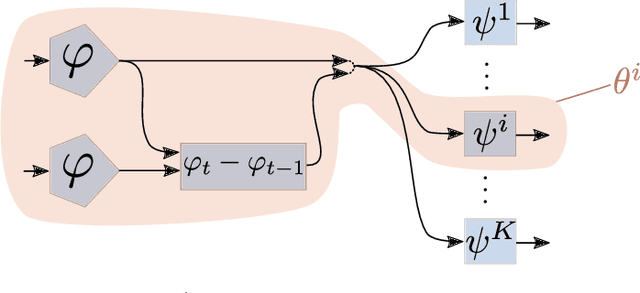

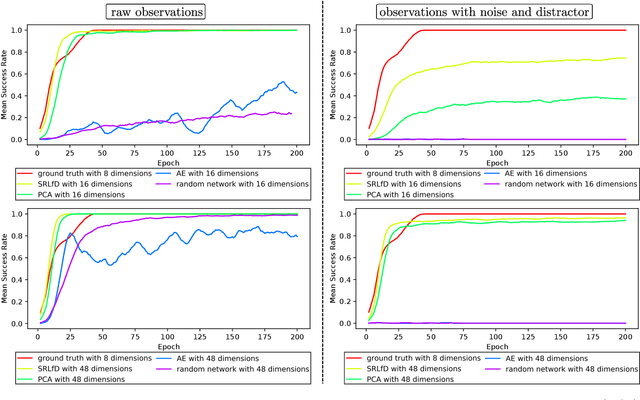
In a context where several policies can be observed as black boxes on different instances of a control task, we propose a method to derive a state representation that can be relied on to reproduce any of the observed policies. We do so via imitation learning on a multi-head neural network consisting of a first part that outputs a common state representation and then one head per policy to imitate. If the demonstrations contain enough diversity, the state representation is general and can be transferred to learn new instances of the task. We present a proof of concept with experimental results on a simulated 2D robotic arm performing a reaching task, with noisy image inputs containing a distractor, and show that the state representations learned provide a greater speed up to end-to-end reinforcement learning on new instances of the task than with other classical representations.