 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeodesics, Non-linearities and the Archive of Novelty Search
May 06, 2022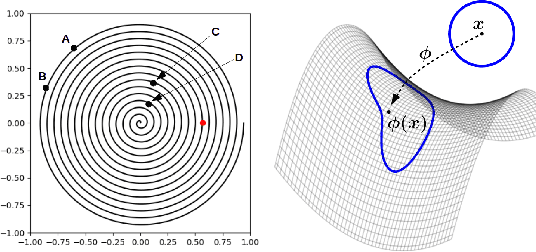


The Novelty Search (NS) algorithm was proposed more than a decade ago. However, the mechanisms behind its empirical success are still not well formalized/understood. This short note focuses on the effects of the archive on exploration. Experimental evidence from a few application domains suggests that archive-based NS performs in general better than when Novelty is solely computed with respect to the population. An argument that is often encountered in the literature is that the archive prevents exploration from backtracking or cycling, i.e. from revisiting previously encountered areas in the behavior space. We argue that this is not a complete or accurate explanation as backtracking - beside often being desirable - can actually be enabled by the archive. Through low-dimensional/analytical examples, we show that a key effect of the archive is that it counterbalances the exploration biases that result, among other factors, from the use of inadequate behavior metrics and the non-linearities of the behavior mapping. Our observations seem to hint that attributing a more active role to the archive in sampling can be beneficial.
* 4 pages, 3 figures
Discovering and Exploiting Sparse Rewards in a Learned Behavior Space
Nov 02, 2021



Learning optimal policies in sparse rewards settings is difficult as the learning agent has little to no feedback on the quality of its actions. In these situations, a good strategy is to focus on exploration, hopefully leading to the discovery of a reward signal to improve on. A learning algorithm capable of dealing with this kind of settings has to be able to (1) explore possible agent behaviors and (2) exploit any possible discovered reward. Efficient exploration algorithms have been proposed that require to define a behavior space, that associates to an agent its resulting behavior in a space that is known to be worth exploring. The need to define this space is a limitation of these algorithms. In this work, we introduce STAX, an algorithm designed to learn a behavior space on-the-fly and to explore it while efficiently optimizing any reward discovered. It does so by separating the exploration and learning of the behavior space from the exploitation of the reward through an alternating two-steps process. In the first step, STAX builds a repertoire of diverse policies while learning a low-dimensional representation of the high-dimensional observations generated during the policies evaluation. In the exploitation step, emitters are used to optimize the performance of the discovered rewarding solutions. Experiments conducted on three different sparse reward environments show that STAX performs comparably to existing baselines while requiring much less prior information about the task as it autonomously builds the behavior space.
Exploratory State Representation Learning
Sep 28, 2021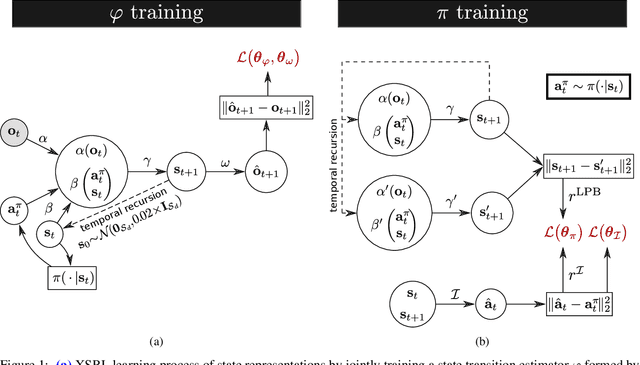
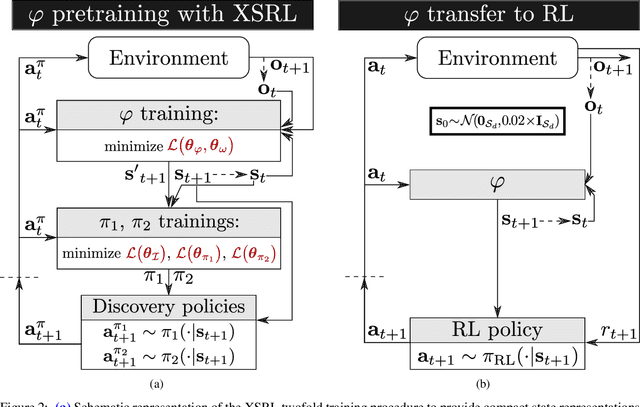


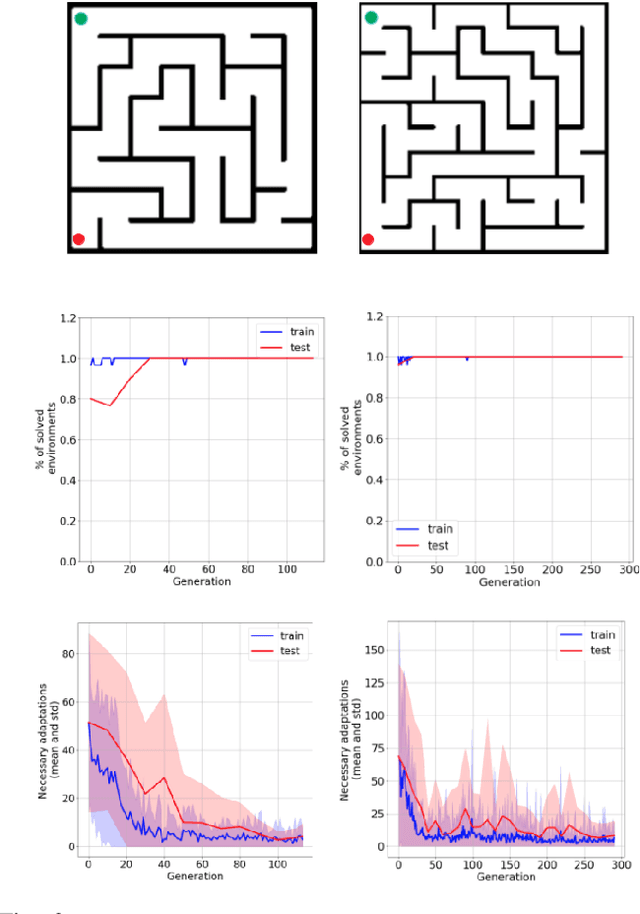
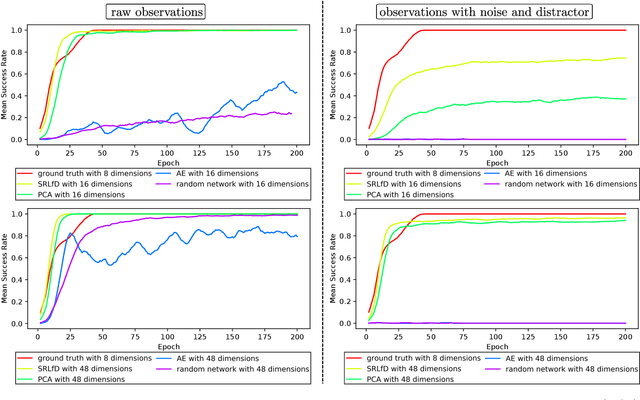
Not having access to compact and meaningful representations is known to significantly increase the complexity of reinforcement learning (RL). For this reason, it can be useful to perform state representation learning (SRL) before tackling RL tasks. However, obtaining a good state representation can only be done if a large diversity of transitions is observed, which can require a difficult exploration, especially if the environment is initially reward-free. To solve the problems of exploration and SRL in parallel, we propose a new approach called XSRL (eXploratory State Representation Learning). On one hand, it jointly learns compact state representations and a state transition estimator which is used to remove unexploitable information from the representations. On the other hand, it continuously trains an inverse model, and adds to the prediction error of this model a $k$-step learning progress bonus to form the maximization objective of a discovery policy. This results in a policy that seeks complex transitions from which the trained models can effectively learn. Our experimental results show that the approach leads to efficient exploration in challenging environments with image observations, and to state representations that significantly accelerate learning in RL tasks.
Few-shot Quality-Diversity Optimisation
Sep 14, 2021

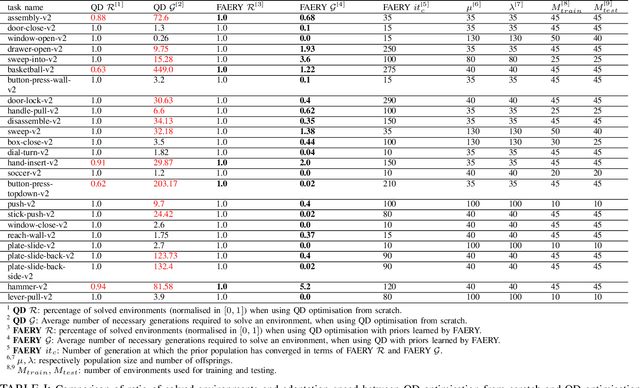
In the past few years, a considerable amount of research has been dedicated to the exploitation of previous learning experiences and the design of Few-shot and Meta Learning approaches, in problem domains ranging from Computer Vision to Reinforcement Learning based control. A notable exception, where to the best of our knowledge, little to no effort has been made in this direction is Quality-Diversity (QD) optimisation. QD methods have been shown to be effective tools in dealing with deceptive minima and sparse rewards in Reinforcement Learning. However, they remain costly due to their reliance on inherently sample inefficient evolutionary processes. We show that, given examples from a task distribution, information about the paths taken by optimisation in parameter space can be leveraged to build a prior population, which when used to initialise QD methods in unseen environments, allows for few-shot adaptation. Our proposed method does not require backpropagation. It is simple to implement and scale, and furthermore, it is agnostic to the underlying models that are being trained. Experiments carried in both sparse and dense reward settings using robotic manipulation and navigation benchmarks show that it considerably reduces the number of generations that are required for QD optimisation in these environments.
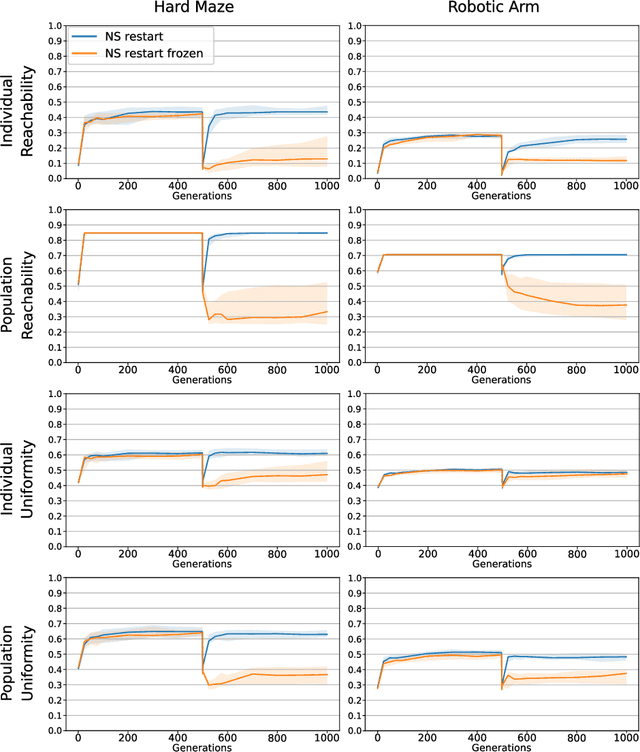
BR-NS: an Archive-less Approach to Novelty Search
Apr 08, 2021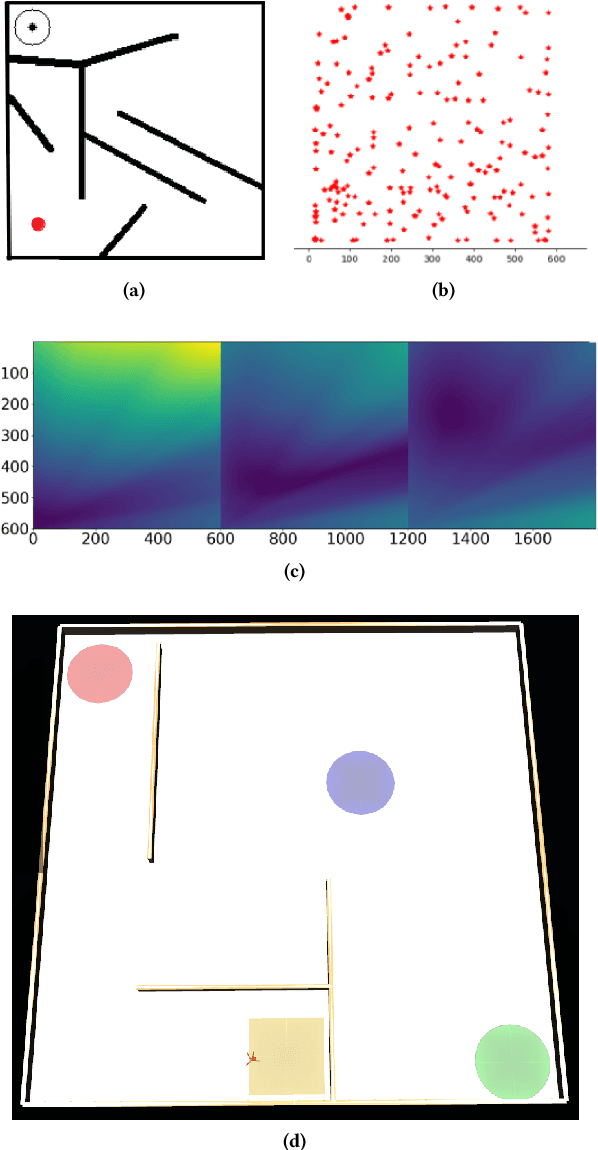
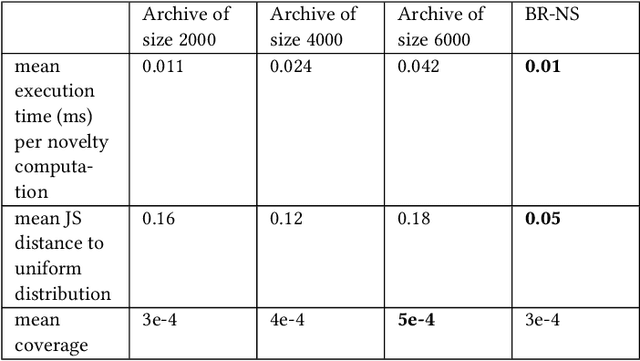
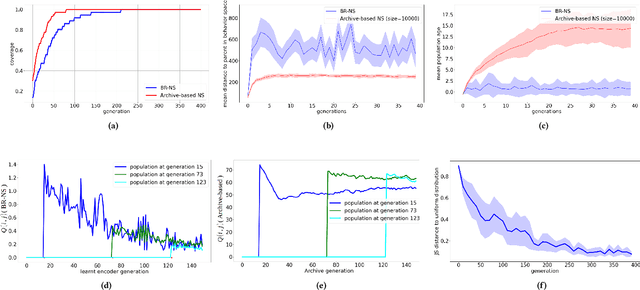
As open-ended learning based on divergent search algorithms such as Novelty Search (NS) draws more and more attention from the research community, it is natural to expect that its application to increasingly complex real-world problems will require the exploration to operate in higher dimensional Behavior Spaces which will not necessarily be Euclidean. Novelty Search traditionally relies on k-nearest neighbours search and an archive of previously visited behavior descriptors which are assumed to live in a Euclidean space. This is problematic because of a number of issues. On one hand, Euclidean distance and Nearest-neighbour search are known to behave differently and become less meaningful in high dimensional spaces. On the other hand, the archive has to be bounded since, memory considerations aside, the computational complexity of finding nearest neighbours in that archive grows linearithmically with its size. A sub-optimal bound can result in "cycling" in the behavior space, which inhibits the progress of the exploration. Furthermore, the performance of NS depends on a number of algorithmic choices and hyperparameters, such as the strategies to add or remove elements to the archive and the number of neighbours to use in k-nn search. In this paper, we discuss an alternative approach to novelty estimation, dubbed Behavior Recognition based Novelty Search (BR-NS), which does not require an archive, makes no assumption on the metrics that can be defined in the behavior space and does not rely on nearest neighbours search. We conduct experiments to gain insight into its feasibility and dynamics as well as potential advantages over archive-based NS in terms of time complexity.
Sparse Reward Exploration via Novelty Search and Emitters
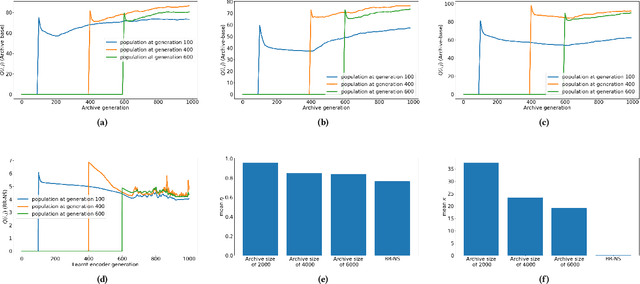
Feb 05, 2021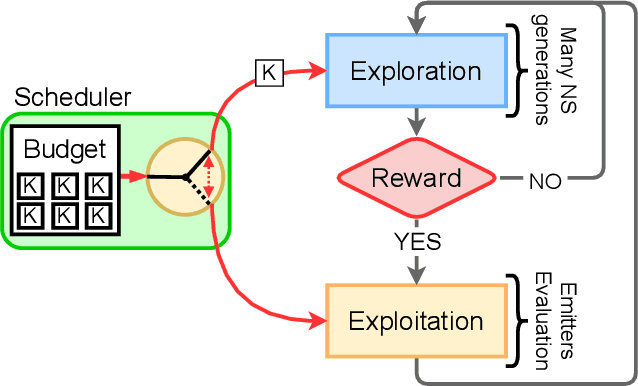

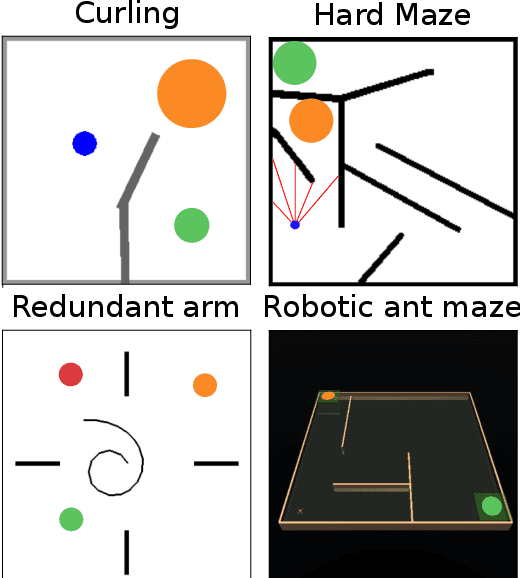
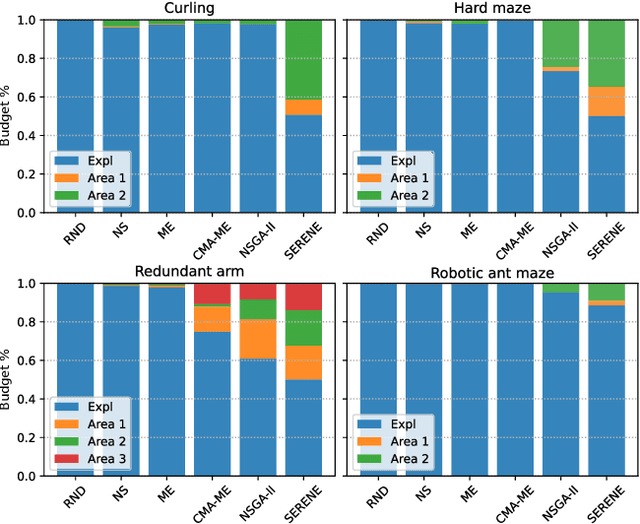
Reward-based optimization algorithms require both exploration, to find rewards, and exploitation, to maximize performance. The need for efficient exploration is even more significant in sparse reward settings, in which performance feedback is given sparingly, thus rendering it unsuitable for guiding the search process. In this work, we introduce the SparsE Reward Exploration via Novelty and Emitters (SERENE) algorithm, capable of efficiently exploring a search space, as well as optimizing rewards found in potentially disparate areas. Contrary to existing emitters-based approaches, SERENE separates the search space exploration and reward exploitation into two alternating processes. The first process performs exploration through Novelty Search, a divergent search algorithm. The second one exploits discovered reward areas through emitters, i.e. local instances of population-based optimization algorithms. A meta-scheduler allocates a global computational budget by alternating between the two processes, ensuring the discovery and efficient exploitation of disjoint reward areas. SERENE returns both a collection of diverse solutions covering the search space and a collection of high-performing solutions for each distinct reward area. We evaluate SERENE on various sparse reward environments and show it compares favorably to existing baselines.
Novelty Search makes Evolvability Inevitable
May 13, 2020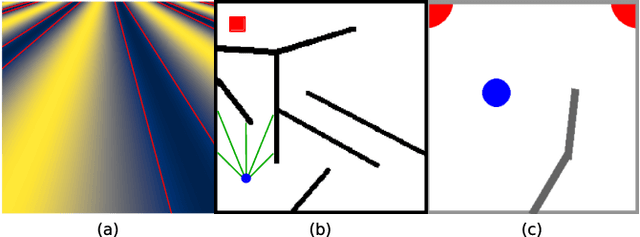

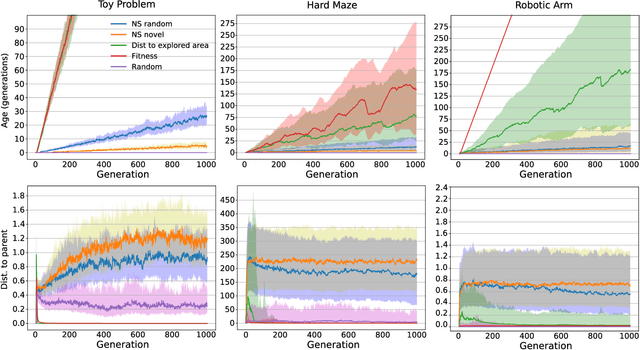
Evolvability is an important feature that impacts the ability of evolutionary processes to find interesting novel solutions and to deal with changing conditions of the problem to solve. The estimation of evolvability is not straightforward and is generally too expensive to be directly used as selective pressure in the evolutionary process. Indirectly promoting evolvability as a side effect of other easier and faster to compute selection pressures would thus be advantageous. In an unbounded behavior space, it has already been shown that evolvable individuals naturally appear and tend to be selected as they are more likely to invade empty behavior niches. Evolvability is thus a natural byproduct of the search in this context. However, practical agents and environments often impose limits on the reach-able behavior space. How do these boundaries impact evolvability? In this context, can evolvability still be promoted without explicitly rewarding it? We show that Novelty Search implicitly creates a pressure for high evolvability even in bounded behavior spaces, and explore the reasons for such a behavior. More precisely we show that, throughout the search, the dynamic evaluation of novelty rewards individuals which are very mobile in the behavior space, which in turn promotes evolvability.
DREAM Architecture: a Developmental Approach to Open-Ended Learning in Robotics
May 13, 2020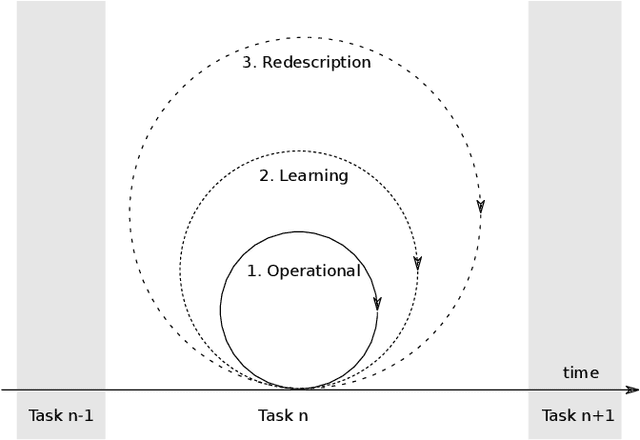
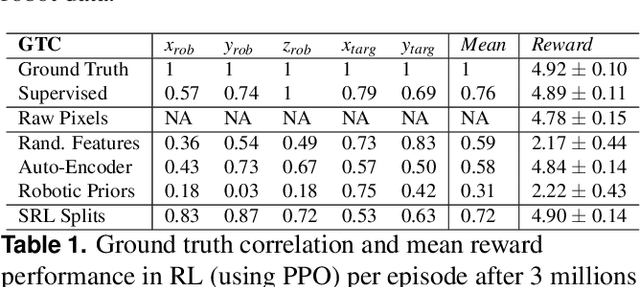
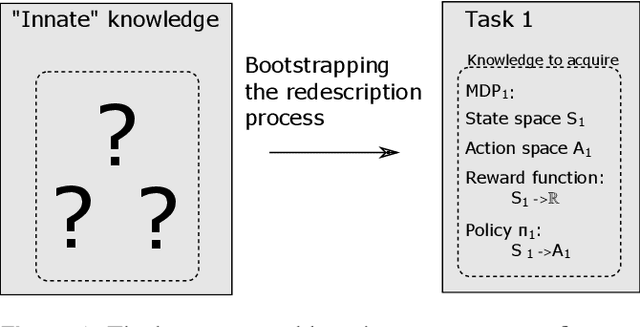
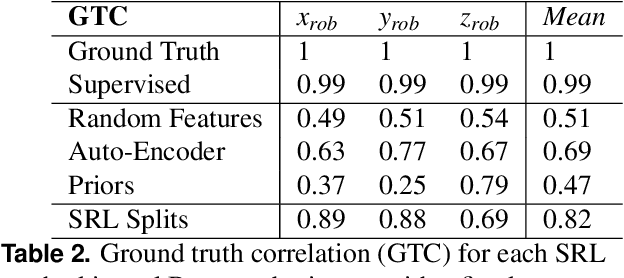
Robots are still limited to controlled conditions, that the robot designer knows with enough details to endow the robot with the appropriate models or behaviors. Learning algorithms add some flexibility with the ability to discover the appropriate behavior given either some demonstrations or a reward to guide its exploration with a reinforcement learning algorithm. Reinforcement learning algorithms rely on the definition of state and action spaces that define reachable behaviors. Their adaptation capability critically depends on the representations of these spaces: small and discrete spaces result in fast learning while large and continuous spaces are challenging and either require a long training period or prevent the robot from converging to an appropriate behavior. Beside the operational cycle of policy execution and the learning cycle, which works at a slower time scale to acquire new policies, we introduce the redescription cycle, a third cycle working at an even slower time scale to generate or adapt the required representations to the robot, its environment and the task. We introduce the challenges raised by this cycle and we present DREAM (Deferred Restructuring of Experience in Autonomous Machines), a developmental cognitive architecture to bootstrap this redescription process stage by stage, build new state representations with appropriate motivations, and transfer the acquired knowledge across domains or tasks or even across robots. We describe results obtained so far with this approach and end up with a discussion of the questions it raises in Neuroscience.
State Representation Learning from Demonstration
Sep 15, 2019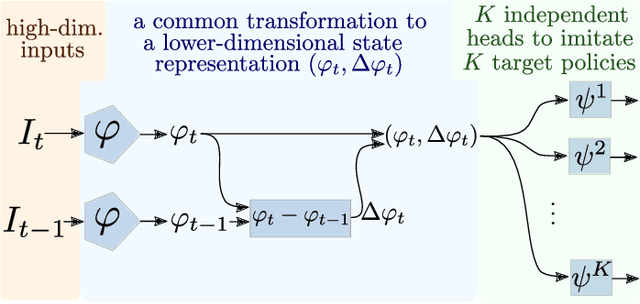
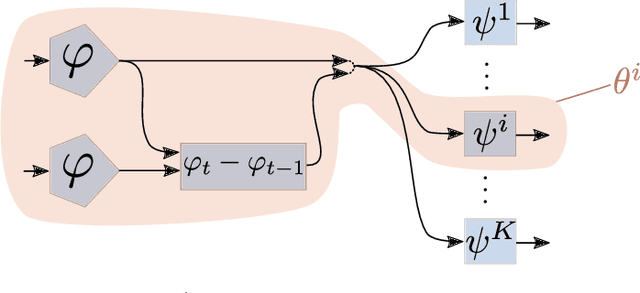

In a context where several policies can be observed as black boxes on different instances of a control task, we propose a method to derive a state representation that can be relied on to reproduce any of the observed policies. We do so via imitation learning on a multi-head neural network consisting of a first part that outputs a common state representation and then one head per policy to imitate. If the demonstrations contain enough diversity, the state representation is general and can be transferred to learn new instances of the task. We present a proof of concept with experimental results on a simulated 2D robotic arm performing a reaching task, with noisy image inputs containing a distractor, and show that the state representations learned provide a greater speed up to end-to-end reinforcement learning on new instances of the task than with other classical representations.
Unsupervised Learning and Exploration of Reachable Outcome Space
Sep 13, 2019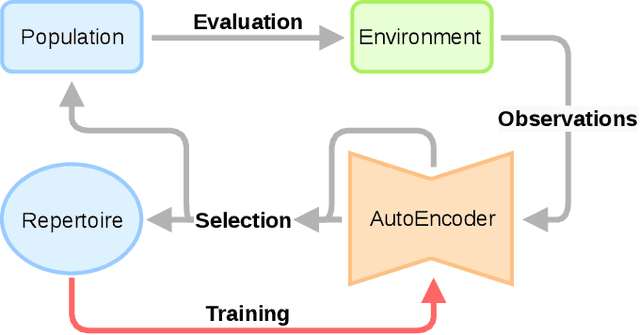
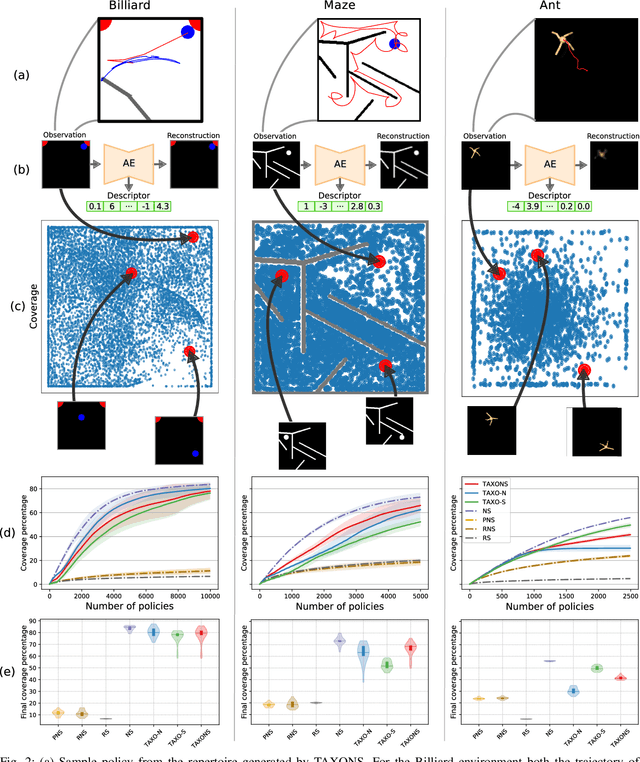
Performing Reinforcement Learning in sparse rewards settings, with very little prior knowledge, is a challenging problem since there is no signal to properly guide the learning process. In such situations, a good search strategy is fundamental. At the same time, not having to adapt the algorithm to every single problem is very desirable. Here we introduce TAXONS, a Task Agnostic eXploration of Outcome spaces through Novelty and Surprise algorithm. Based on a population-based divergent-search approach, it learns a set of diverse policies directly from high-dimensional observations, without any task-specific information. TAXONS builds a repertoire of policies while training an autoencoder on the high-dimensional observation of the final state of the system to build a low-dimensional outcome space. The learned outcome space, combined with the reconstruction error, is used to drive the search for new policies. Results show that TAXONS can find a diverse set of controllers, covering a good part of the ground-truth outcome space, while having no information about such space.