 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compositional Neural Programs for Continuous Control
Jul 27, 2020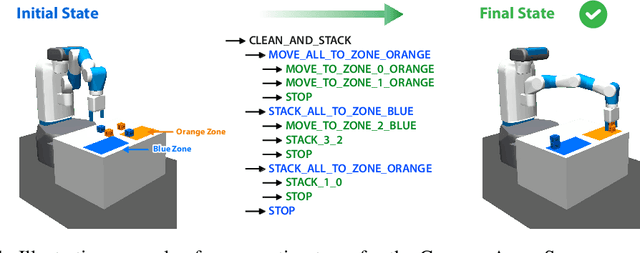

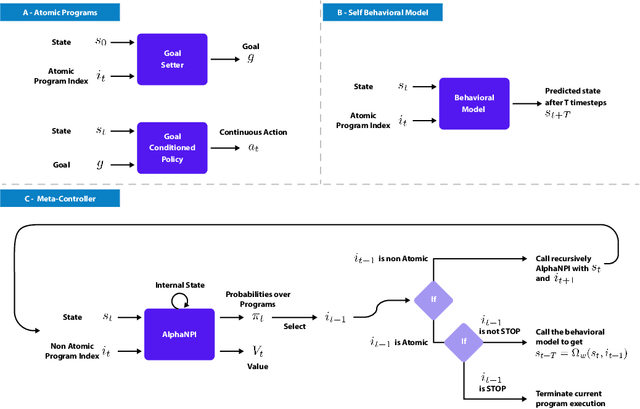
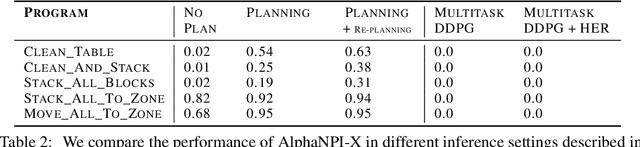
We propose a novel solution to challenging sparse-reward, continuous control problems that require hierarchical planning at multiple levels of abstraction. Our solution, dubbed AlphaNPI-X, involves three separate stages of learning. First, we use off-policy reinforcement learning algorithms with experience replay to learn a set of atomic goal-conditioned policies, which can be easily repurposed for many tasks. Second, we learn self-models describing the effect of the atomic policies on the environment. Third, the self-models are harnessed to learn recursive compositional programs with multiple levels of abstraction. The key insight is that the self-models enable planning by imagination, obviating the need for interaction with the world when learning higher-level compositional programs. To accomplish the third stage of learning, we extend the AlphaNPI algorithm, which applies AlphaZero to learn recursive neural programmer-interpreters. We empirically show that AlphaNPI-X can effectively learn to tackle challenging sparse manipulation tasks, such as stacking multiple blocks, where powerful model-free baselines fail.
QD-RL: Efficient Mixing of Quality and Diversity in Reinforcement Learning
Jun 15, 2020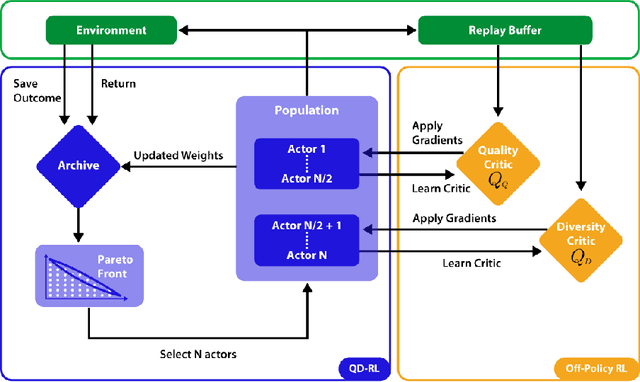
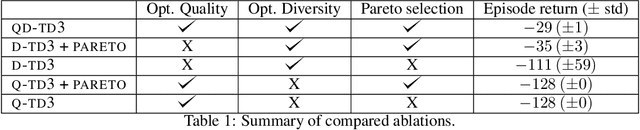
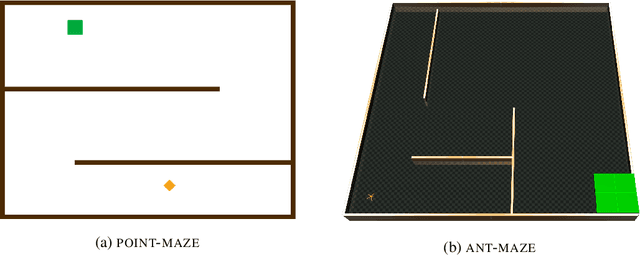
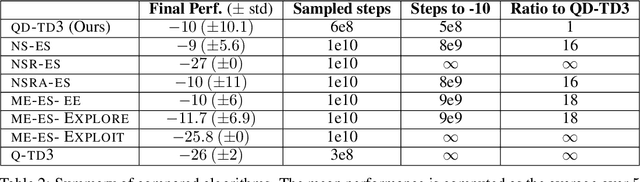
We propose a novel reinforcement learning algorithm,QD-RL, that incorporates the strengths of off-policy RL algorithms into Quality Diversity (QD) approaches. Quality-Diversity methods contribute structural biases by decoupling the search for diversity from the search for high return, resulting in efficient management of the exploration-exploitation trade-off. However, these approaches generally suffer from sample inefficiency as they call upon evolutionary techniques. QD-RL removes this limitation by relying on off-policy RL algorithms. More precisely, we train a population of off-policy deep RL agents to simultaneously maximize diversity inside the population and the return of the agents. QD-RL selects agents from the diversity-return Pareto Front, resulting in stable and efficient population updates. Our experiments on the Ant-Maze environment show that QD-RL can solve challenging exploration and control problems with deceptive rewards while being more than 15 times more sample efficient than its evolutionary counterparts.
Recurrent Neural Networks for Stochastic Control in Real-Time Bidding
Jun 12, 2020
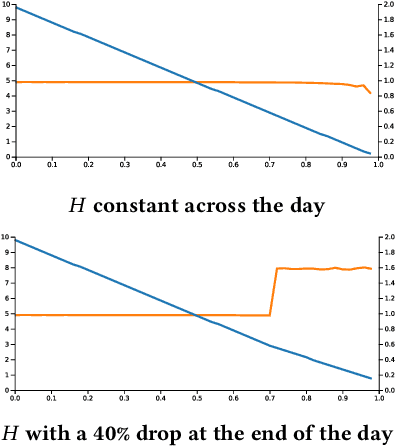
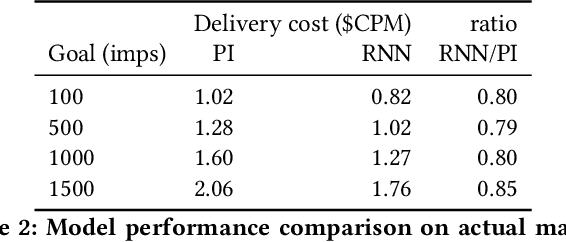
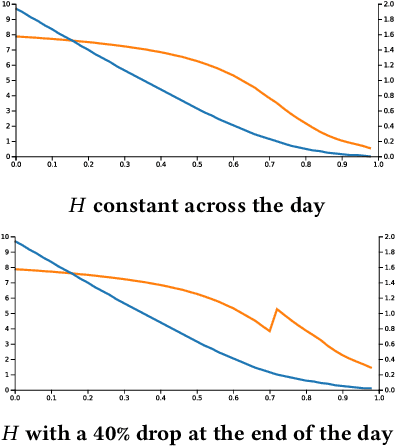
Bidding in real-time auctions can be a difficult stochastic control task; especially if underdelivery incurs strong penalties and the market is very uncertain. Most current works and implementations focus on optimally delivering a campaign given a reasonable forecast of the market. Practical implementations have a feedback loop to adjust and be robust to forecasting errors, but no implementation, to the best of our knowledge, uses a model of market risk and actively anticipates market shifts. Solving such stochastic control problems in practice is actually very challenging. This paper proposes an approximate solution based on a Recurrent Neural Network (RNN) architecture that is both effective and practical for implementation in a production environment. The RNN bidder provisions everything it needs to avoid missing its goal. It also deliberately falls short of its goal when buying the missing impressions would cost more than the penalty for not reaching it.
PBCS : Efficient Exploration and Exploitation Using a Synergy between Reinforcement Learning and Motion Planning
Apr 24, 2020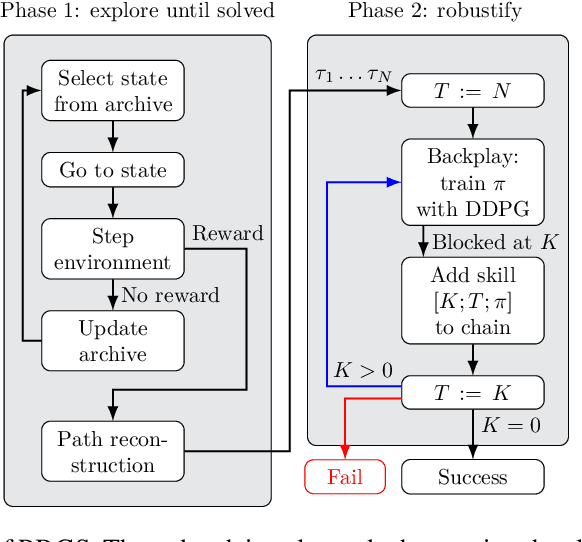
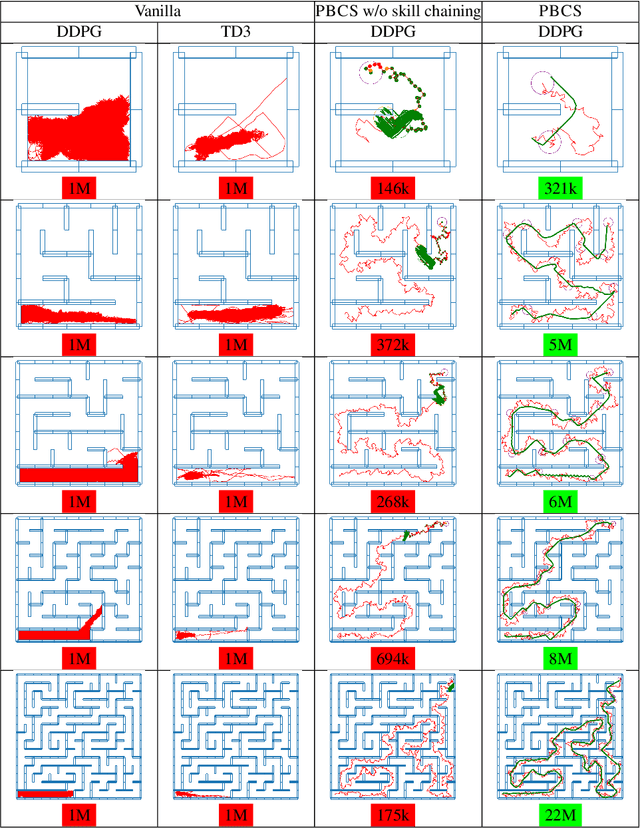
The exploration-exploitation trade-off is at the heart of reinforcement learning (RL). However, most continuous control benchmarks used in recent RL research only require local exploration. This led to the development of algorithms that have basic exploration capabilities, and behave poorly in benchmarks that require more versatile exploration. For instance, as demonstrated in our empirical study, state-of-the-art RL algorithms such as DDPG and TD3 are unable to steer a point mass in even small 2D mazes. In this paper, we propose a new algorithm called "Plan, Backplay, Chain Skills" (PBCS) that combines motion planning and reinforcement learning to solve hard exploration environments. In a first phase, a motion planning algorithm is used to find a single good trajectory, then an RL algorithm is trained using a curriculum derived from the trajectory, by combining a variant of the Backplay algorithm and skill chaining. We show that this method outperforms state-of-the-art RL algorithms in 2D maze environments of various sizes, and is able to improve on the trajectory obtained by the motion planning phase.
The problem with DDPG: understanding failures in deterministic environments with sparse rewards
Nov 26, 2019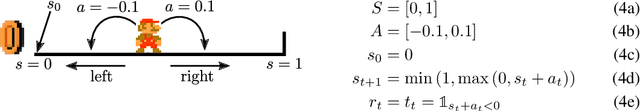

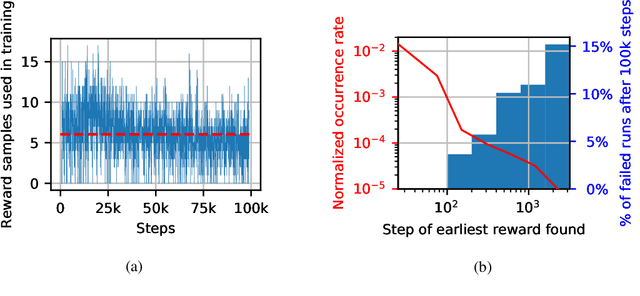

In environments with continuous state and action spaces, state-of-the-art actor-critic reinforcement learning algorithms can solve very complex problems, yet can also fail in environments that seem trivial, but the reason for such failures is still poorly understood. In this paper, we contribute a formal explanation of these failures in the particular case of sparse reward and deterministic environments. First, using a very elementary control problem, we illustrate that the learning process can get stuck into a fixed point corresponding to a poor solution. Then, generalizing from the studied example, we provide a detailed analysis of the underlying mechanisms which results in a new understanding of one of the convergence regimes of these algorithms. The resulting perspective casts a new light on already existing solutions to the issues we have highlighted, and suggests other potential approaches.
State Representation Learning from Demonstration
Sep 15, 2019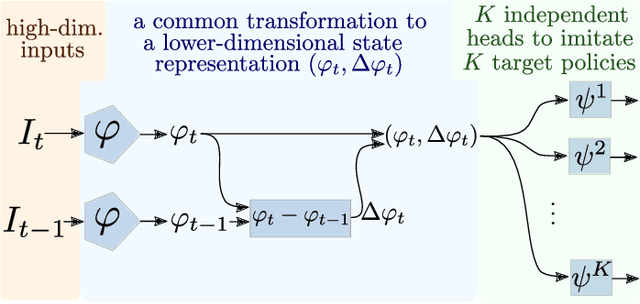
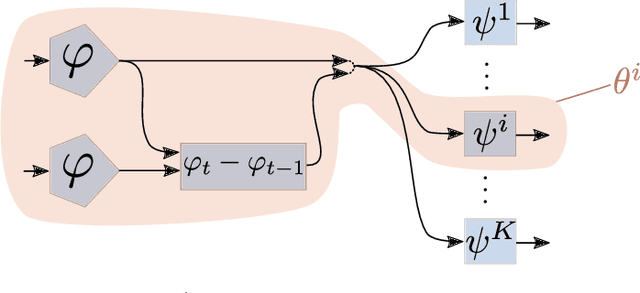

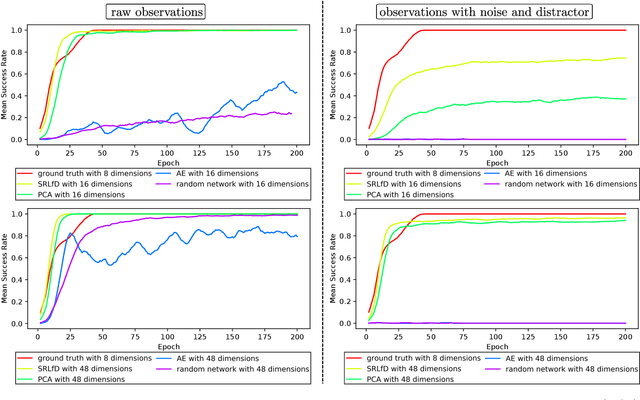
In a context where several policies can be observed as black boxes on different instances of a control task, we propose a method to derive a state representation that can be relied on to reproduce any of the observed policies. We do so via imitation learning on a multi-head neural network consisting of a first part that outputs a common state representation and then one head per policy to imitate. If the demonstrations contain enough diversity, the state representation is general and can be transferred to learn new instances of the task. We present a proof of concept with experimental results on a simulated 2D robotic arm performing a reaching task, with noisy image inputs containing a distractor, and show that the state representations learned provide a greater speed up to end-to-end reinforcement learning on new instances of the task than with other classical representations.
Learning Compositional Neural Programs with Recursive Tree Search and Planning
May 30, 2019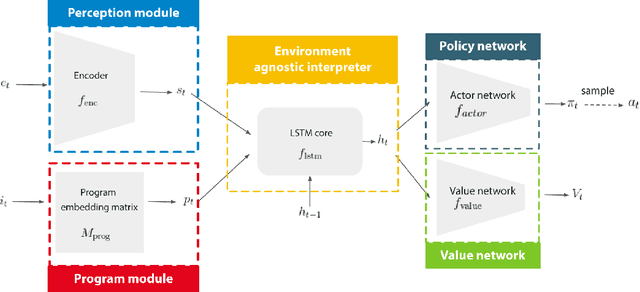



We propose a novel reinforcement learning algorithm, AlphaNPI, that incorporates the strengths of Neural Programmer-Interpreters (NPI) and AlphaZero. NPI contributes structural biases in the form of modularity, hierarchy and recursion, which are helpful to reduce sample complexity, improve generalization and increase interpretability. AlphaZero contributes powerful neural network guided search algorithms, which we augment with recursion. AlphaNPI only assumes a hierarchical program specification with sparse rewards: 1 when the program execution satisfies the specification, and 0 otherwise. Using this specification, AlphaNPI is able to train NPI models effectively with RL for the first time, completely eliminating the need for strong supervision in the form of execution traces. The experiments show that AlphaNPI can sort as well as previous strongly supervised NPI variants. The AlphaNPI agent is also trained on a Tower of Hanoi puzzle with two disks and is shown to generalize to puzzles with an arbitrary number of disk
First-order and second-order variants of the gradient descent: a unified framework
Oct 18, 2018


In this paper, we provide an overview of first-order and second-order variants of the gradient descent methods commonly used in machine learning. We propose a general framework in which 6 of these methods can be interpreted as different instances of the same approach. These methods are the vanilla gradient descent, the classical and generalized Gauss-Newton methods, the natural gradient descent method, the gradient covariance matrix approach, and Newton's method. Besides interpreting these methods within a single framework, we explain their specificities and show under which conditions some of them coincide.
Importance mixing: Improving sample reuse in evolutionary policy search methods
Aug 17, 2018
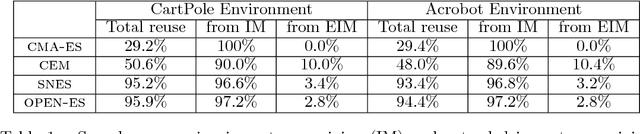
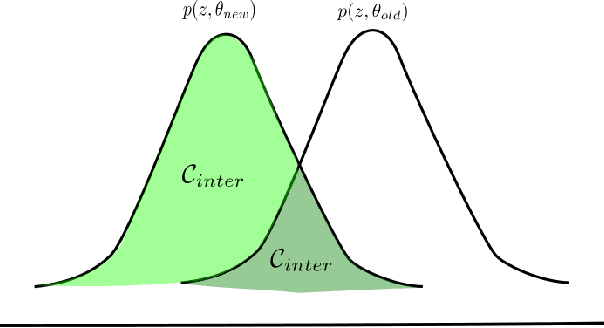
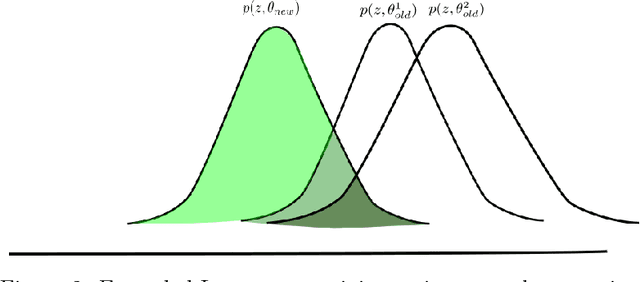
Deep neuroevolution, that is evolutionary policy search methods based on deep neural networks, have recently emerged as a competitor to deep reinforcement learning algorithms due to their better parallelization capabilities. However, these methods still suffer from a far worse sample efficiency. In this paper we investigate whether a mechanism known as "importance mixing" can significantly improve their sample efficiency. We provide a didactic presentation of importance mixing and we explain how it can be extended to reuse more samples. Then, from an empirical comparison based on a simple benchmark, we show that, though it actually provides better sample efficiency, it is still far from the sample efficiency of deep reinforcement learning, though it is more stable.