 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Share or Not To Share: A Comprehensive Appraisal of Weight-Sharing
Feb 11, 2020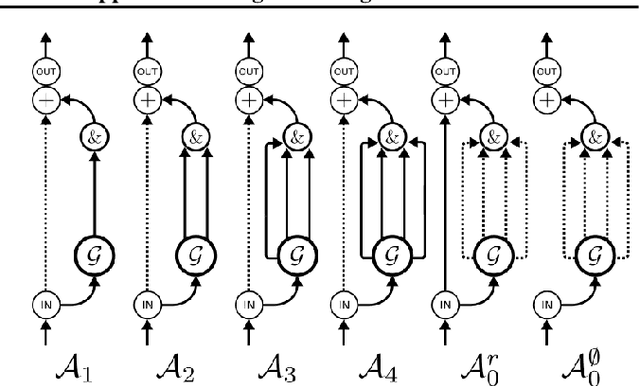
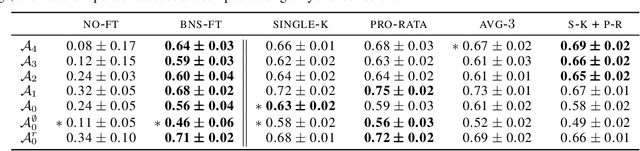
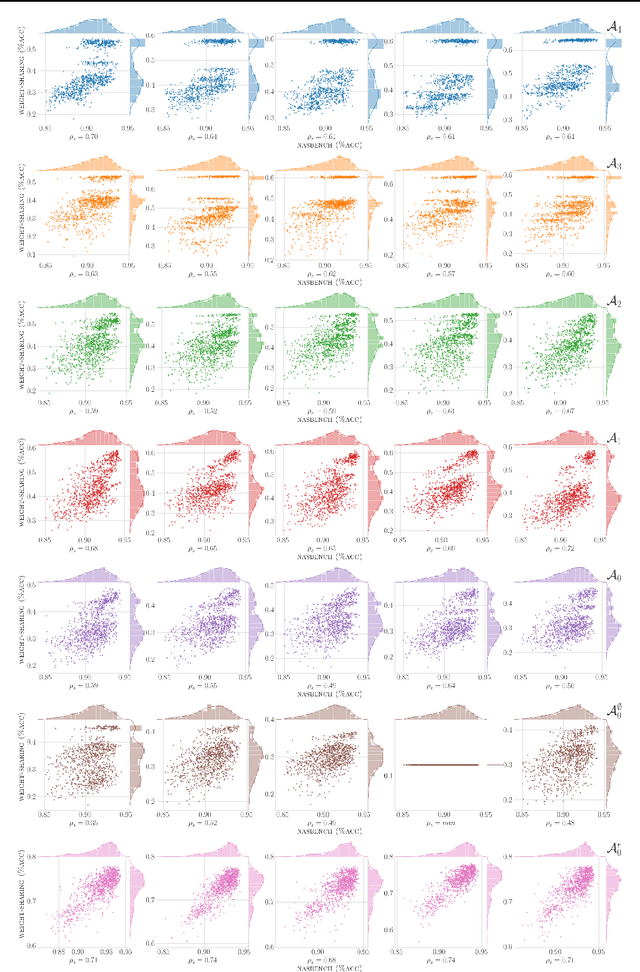
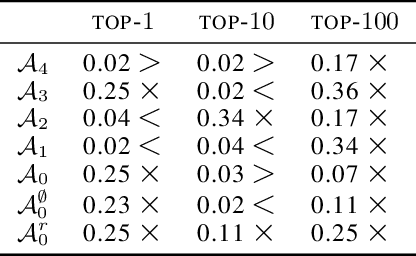
Weight-sharing (WS) has recently emerged as a paradigm to accelerate the automated search for efficient neural architectures, a process dubbed Neural Architecture Search (NAS). Although very appealing, this framework is not without drawbacks and several works have started to question its capabilities on small hand-crafted benchmarks. In this paper, we take advantage of the NASBench-101 dataset to challenge the efficiency of WS on a representative search space. By comparing a SOTA WS approach to a plain random search we show that, despite decent correlations between evaluations using weight-sharing and standalone ones, WS is only rarely helpful to NAS. We highlight in particular the reliance of the benefits on the search space itself.
CEM-RL: Combining evolutionary and gradient-based methods for policy search
Oct 02, 2018



Deep neuroevolution and deep reinforcement learning (deep RL) algorithms are two popular approaches to policy search. The former is widely applicable and rather stable, but suffers from low sample efficiency. By contrast, the latter is more sample efficient, but the most sample efficient variants are also rather unstable and highly sensitive to hyper-parameter setting. So far, these families of methods have mostly been compared as competing tools. However, an emerging approach consists in combining them so as to get the best of both worlds. Two previously existing combinations use either a standard evolutionary algorithm or a goal exploration process together with the DDPG algorithm, a sample efficient off-policy deep RL algorithm. In this paper, we propose a different combination scheme using the simple cross-entropy method (CEM) and TD3, another off-policy deep RL algorithm which improves over DDPG. We evaluate the resulting algorithm, CEM-RL, on a set of benchmarks classically used in deep RL. We show that CEM-RL benefits from several advantages over its competitors and offers a satisfactory trade-off between performance and sample efficiency.
Importance mixing: Improving sample reuse in evolutionary policy search methods
Aug 17, 2018
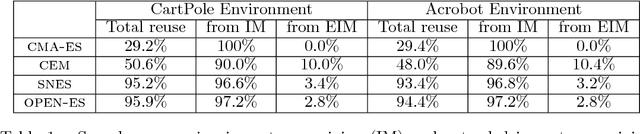
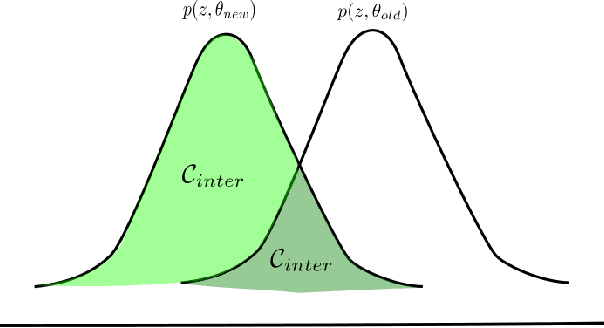
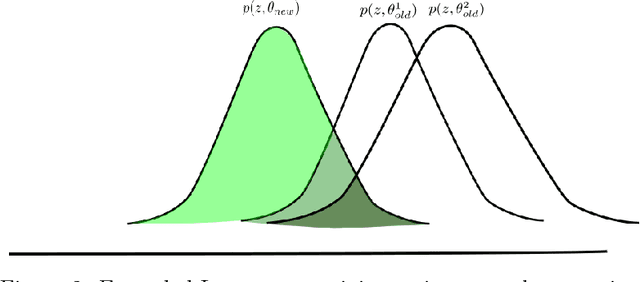
Deep neuroevolution, that is evolutionary policy search methods based on deep neural networks, have recently emerged as a competitor to deep reinforcement learning algorithms due to their better parallelization capabilities. However, these methods still suffer from a far worse sample efficiency. In this paper we investigate whether a mechanism known as "importance mixing" can significantly improve their sample efficiency. We provide a didactic presentation of importance mixing and we explain how it can be extended to reuse more samples. Then, from an empirical comparison based on a simple benchmark, we show that, though it actually provides better sample efficiency, it is still far from the sample efficiency of deep reinforcement learning, though it is more stable.