 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance mixing: Improving sample reuse in evolutionary policy search methods
Paper and Code

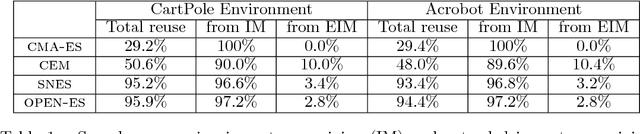
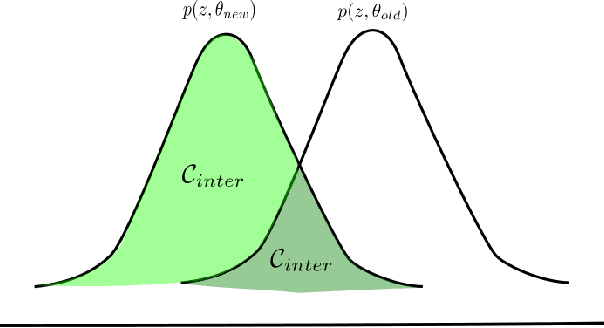
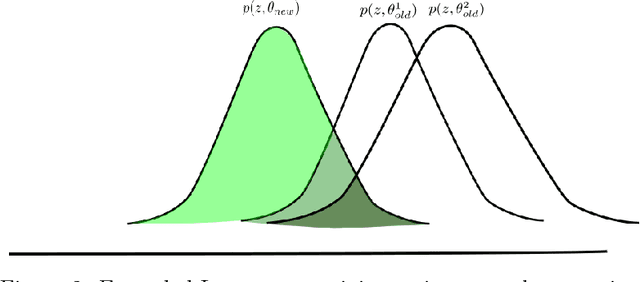
Deep neuroevolution, that is evolutionary policy search methods based on deep neural networks, have recently emerged as a competitor to deep reinforcement learning algorithms due to their better parallelization capabilities. However, these methods still suffer from a far worse sample efficiency. In this paper we investigate whether a mechanism known as "importance mixing" can significantly improve their sample efficiency. We provide a didactic presentation of importance mixing and we explain how it can be extended to reuse more samples. Then, from an empirical comparison based on a simple benchmark, we show that, though it actually provides better sample efficiency, it is still far from the sample efficiency of deep reinforcement learning, though it is more stable.