 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compositional Neural Programs for Continuous Control
Paper and Code
Jul 27, 2020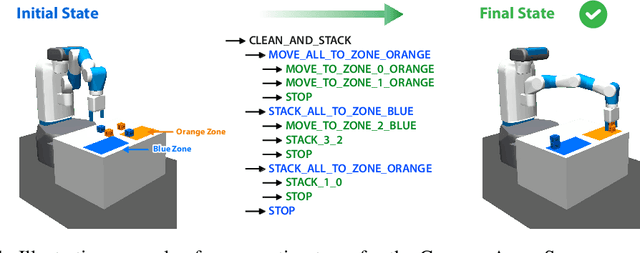

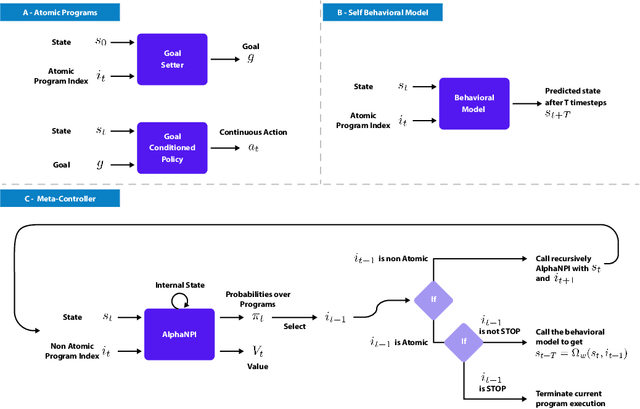
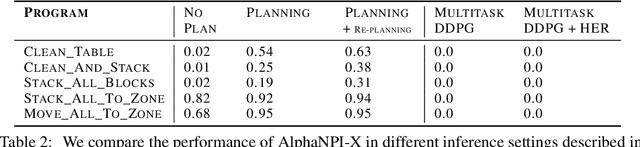
We propose a novel solution to challenging sparse-reward, continuous control problems that require hierarchical planning at multiple levels of abstraction. Our solution, dubbed AlphaNPI-X, involves three separate stages of learning. First, we use off-policy reinforcement learning algorithms with experience replay to learn a set of atomic goal-conditioned policies, which can be easily repurposed for many tasks. Second, we learn self-models describing the effect of the atomic policies on the environment. Third, the self-models are harnessed to learn recursive compositional programs with multiple levels of abstraction. The key insight is that the self-models enable planning by imagination, obviating the need for interaction with the world when learning higher-level compositional programs. To accomplish the third stage of learning, we extend the AlphaNPI algorithm, which applies AlphaZero to learn recursive neural programmer-interpreters. We empirically show that AlphaNPI-X can effectively learn to tackle challenging sparse manipulation tasks, such as stacking multiple blocks, where powerful model-free baselines fail.