 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Compositional Neural Programs with Recursive Tree Search and Planning
May 30, 2019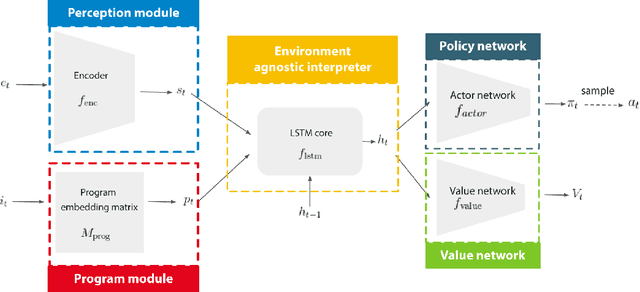



We propose a novel reinforcement learning algorithm, AlphaNPI, that incorporates the strengths of Neural Programmer-Interpreters (NPI) and AlphaZero. NPI contributes structural biases in the form of modularity, hierarchy and recursion, which are helpful to reduce sample complexity, improve generalization and increase interpretability. AlphaZero contributes powerful neural network guided search algorithms, which we augment with recursion. AlphaNPI only assumes a hierarchical program specification with sparse rewards: 1 when the program execution satisfies the specification, and 0 otherwise. Using this specification, AlphaNPI is able to train NPI models effectively with RL for the first time, completely eliminating the need for strong supervision in the form of execution traces. The experiments show that AlphaNPI can sort as well as previous strongly supervised NPI variants. The AlphaNPI agent is also trained on a Tower of Hanoi puzzle with two disks and is shown to generalize to puzzles with an arbitrary number of disk