 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG with Differential Privacy
Dec 26, 2024



Retrieval-Augmented Generation (RAG) has emerged as the dominant technique to provide *Large Language Models* (LLM) with fresh and relevant context, mitigating the risk of hallucinations and improving the overall quality of responses in environments with large and fast moving knowledge bases. However, the integration of external documents into the generation process raises significant privacy concerns. Indeed, when added to a prompt, it is not possible to guarantee a response will not inadvertently expose confidential data, leading to potential breaches of privacy and ethical dilemmas. This paper explores a practical solution to this problem suitable to general knowledge extraction from personal data. It shows *differentially private token generation* is a viable approach to private RAG.
Qrlew: Rewriting SQL into Differentially Private SQL
Jan 11, 2024This paper introduces Qrlew, an open source library that can parse SQL queries into Relations -- an intermediate representation -- that keeps track of rich data types, value ranges, and row ownership; so that they can easily be rewritten into differentially-private equivalent and turned back into SQL queries for execution in a variety of standard data stores. With Qrlew, a data practitioner can express their data queries in standard SQL; the data owner can run the rewritten query without any technical integration and with strong privacy guarantees on the output; and the query rewriting can be operated by a privacy-expert who must be trusted by the owner, but may belong to a separate organization.
Private Quantiles Estimation in the Presence of Atoms
Feb 15, 2022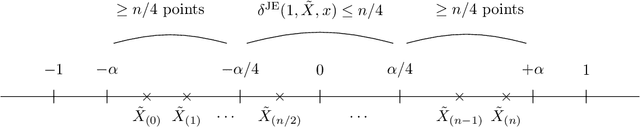


We address the differentially private estimation of multiple quantiles (MQ) of a dataset, a key building block in modern data analysis. We apply the recent non-smoothed Inverse Sensitivity (IS) mechanism to this specific problem and establish that the resulting method is closely related to the current state-of-the-art, the JointExp algorithm, sharing in particular the same computational complexity and a similar efficiency. However, we demonstrate both theoretically and empirically that (non-smoothed) JointExp suffers from an important lack of performance in the case of peaked distributions, with a potentially catastrophic impact in the presence of atoms. While its smoothed version would allow to leverage the performance guarantees of IS, it remains an open challenge to implement. As a proxy to fix the problem we propose a simple and numerically efficient method called Heuristically Smoothed JointExp (HSJointExp), which is endowed with performance guarantees for a broad class of distributions and achieves results that are orders of magnitude better on problematic datasets.
Generative Modeling of Complex Data
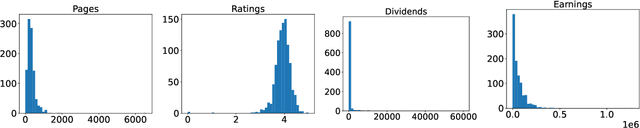
Feb 04, 2022In recent years, several models have improved the capacity to generate synthetic tabular datasets. However, such models focus on synthesizing simple columnar tables and are not useable on real-life data with complex structures. This paper puts forward a generic framework to synthesize more complex data structures with composite and nested types. It then proposes one practical implementation, built with causal transformers, for struct (mappings of types) and lists (repeated instances of a type). The results on standard benchmark datasets show that such implementation consistently outperforms current state-of-the-art models both in terms of machine learning utility and statistical similarity. Moreover, it shows very strong results on two complex hierarchical datasets with multiple nesting and sparse data, that were previously out of reach.
DP-XGBoost: Private Machine Learning at Scale
Oct 25, 2021



The big-data revolution announced ten years ago does not seem to have fully happened at the expected scale. One of the main obstacle to this, has been the lack of data circulation. And one of the many reasons people and organizations did not share as much as expected is the privacy risk associated with data sharing operations. There has been many works on practical systems to compute statistical queries with Differential Privacy (DP). There have also been practical implementations of systems to train Neural Networks with DP, but relatively little efforts have been dedicated to designing scalable classical Machine Learning (ML) models providing DP guarantees. In this work we describe and implement a DP fork of a battle tested ML model: XGBoost. Our approach beats by a large margin previous attempts at the task, in terms of accuracy achieved for a given privacy budget. It is also the only DP implementation of boosted trees that scales to big data and can run in distributed environments such as: Kubernetes, Dask or Apache Spark.
Composable Generative Models
Feb 18, 2021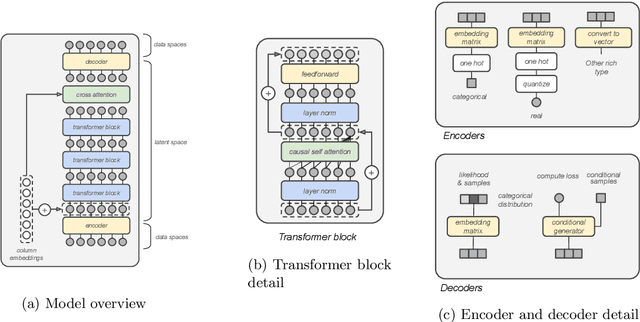
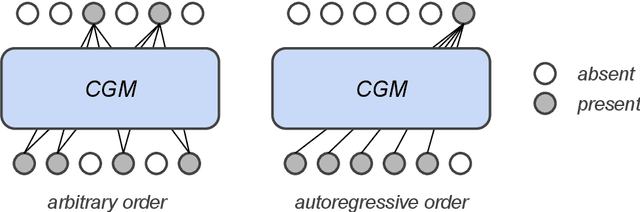
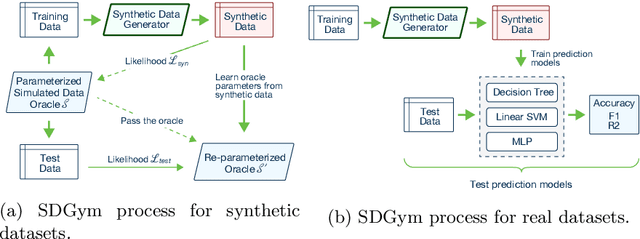
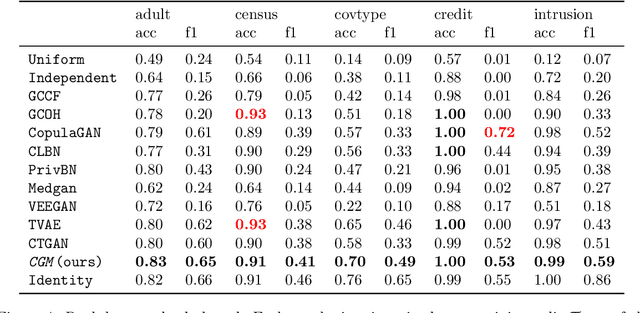
Generative modeling has recently seen many exciting developments with the advent of deep generative architectures such as Variational Auto-Encoders (VAE) or Generative Adversarial Networks (GAN). The ability to draw synthetic i.i.d. observations with the same joint probability distribution as a given dataset has a wide range of applications including representation learning, compression or imputation. It appears that it also has many applications in privacy preserving data analysis, especially when used in conjunction with differential privacy techniques. This paper focuses on synthetic data generation models with privacy preserving applications in mind. It introduces a novel architecture, the Composable Generative Model (CGM) that is state-of-the-art in tabular data generation. Any conditional generative model can be used as a sub-component of the CGM, including CGMs themselves, allowing the generation of numerical, categorical data as well as images, text, or time series. The CGM has been evaluated on 13 datasets (6 standard datasets and 7 simulated) and compared to 14 recent generative models. It beats the state of the art in tabular data generation by a significant margin.
Real-Time Optimization Of Web Publisher RTB Revenues
Jun 12, 2020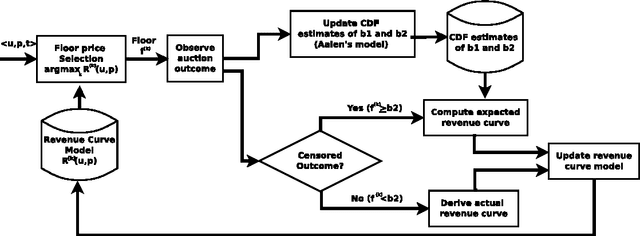
This paper describes an engine to optimize web publisher revenues from second-price auctions. These auctions are widely used to sell online ad spaces in a mechanism called real-time bidding (RTB). Optimization within these auctions is crucial for web publishers, because setting appropriate reserve prices can significantly increase revenue. We consider a practical real-world setting where the only available information before an auction occurs consists of a user identifier and an ad placement identifier. The real-world challenges we had to tackle consist mainly of tracking the dependencies on both the user and placement in an highly non-stationary environment and of dealing with censored bid observations. These challenges led us to make the following design choices: (i) we adopted a relatively simple non-parametric regression model of auction revenue based on an incremental time-weighted matrix factorization which implicitly builds adaptive users' and placements' profiles; (ii) we jointly used a non-parametric model to estimate the first and second bids' distribution when they are censored, based on an on-line extension of the Aalen's Additive model. Our engine is a component of a deployed system handling hundreds of web publishers across the world, serving billions of ads a day to hundreds of millions of visitors. The engine is able to predict, for each auction, an optimal reserve price in approximately one millisecond and yields a significant revenue increase for the web publishers.
Optimal Allocation of Real-Time-Bidding and Direct Campaigns
Jun 12, 2020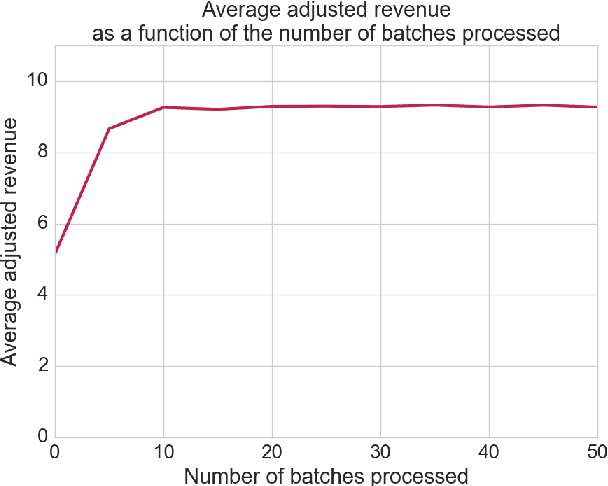
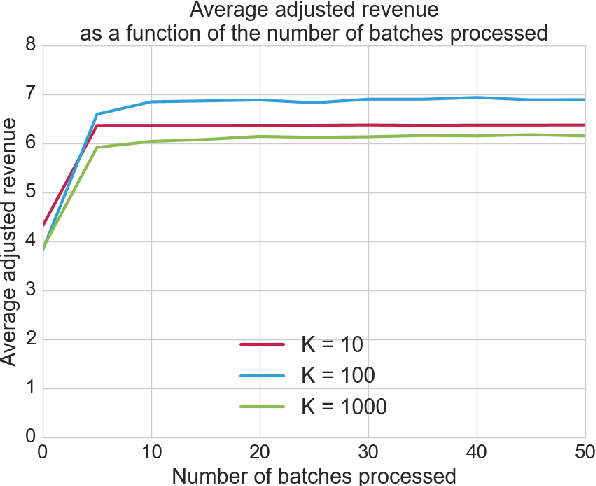
In this paper, we consider the problem of optimizing the revenue a web publisher gets through real-time bidding (i.e. from ads sold in real-time auctions) and direct (i.e. from ads sold through contracts agreed in advance). We consider a setting where the publisher is able to bid in the real-time bidding auction for each impression. If it wins the auction, it chooses a direct campaign to deliver and displays the corresponding ad. This paper presents an algorithm to build an optimal strategy for the publisher to deliver its direct campaigns while maximizing its real-time bidding revenue. The optimal strategy gives a formula to determine the publisher bid as well as a way to choose the direct campaign being delivered if the publisher bidder wins the auction, depending on the impression characteristics. The optimal strategy can be estimated on past auctions data. The algorithm scales with the number of campaigns and the size of the dataset. This is a very important feature, as in practice a publisher may have thousands of active direct campaigns at the same time and would like to estimate an optimal strategy on billions of auctions. The algorithm is a key component of a system which is being developed, and which will be deployed on thousands of web publishers worldwide, helping them to serve efficiently billions of ads a day to hundreds of millions of visitors.
Recurrent Neural Networks for Stochastic Control in Real-Time Bidding
Jun 12, 2020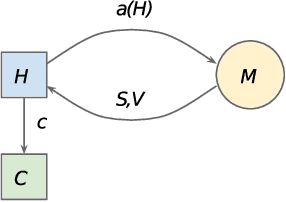
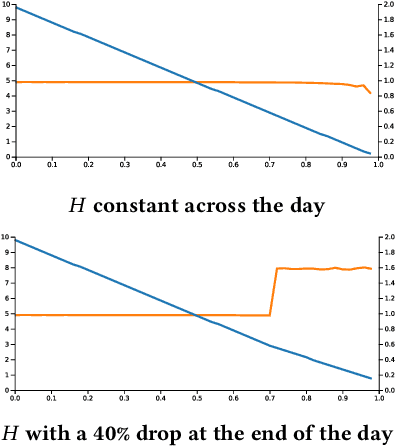
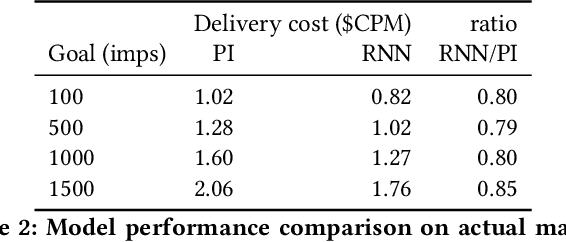
Bidding in real-time auctions can be a difficult stochastic control task; especially if underdelivery incurs strong penalties and the market is very uncertain. Most current works and implementations focus on optimally delivering a campaign given a reasonable forecast of the market. Practical implementations have a feedback loop to adjust and be robust to forecasting errors, but no implementation, to the best of our knowledge, uses a model of market risk and actively anticipates market shifts. Solving such stochastic control problems in practice is actually very challenging. This paper proposes an approximate solution based on a Recurrent Neural Network (RNN) architecture that is both effective and practical for implementation in a production environment. The RNN bidder provisions everything it needs to avoid missing its goal. It also deliberately falls short of its goal when buying the missing impressions would cost more than the penalty for not reaching it.
Optimization of a SSP's Header Bidding Strategy using Thompson Sampling
Jul 09, 2018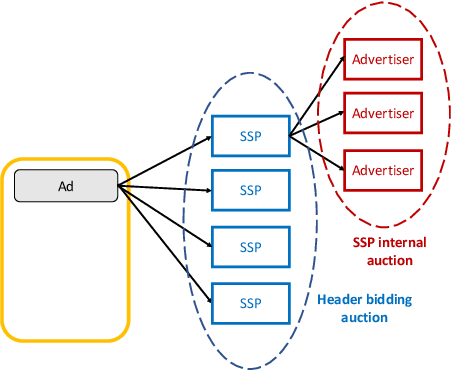

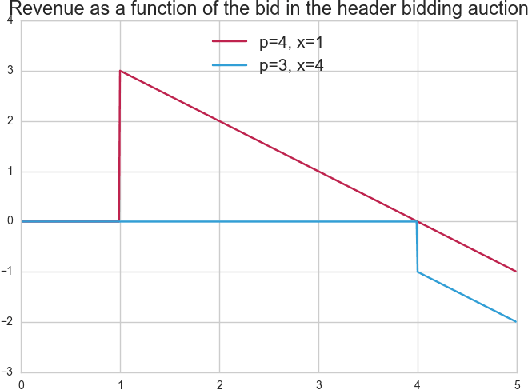
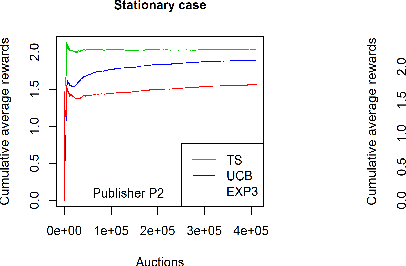
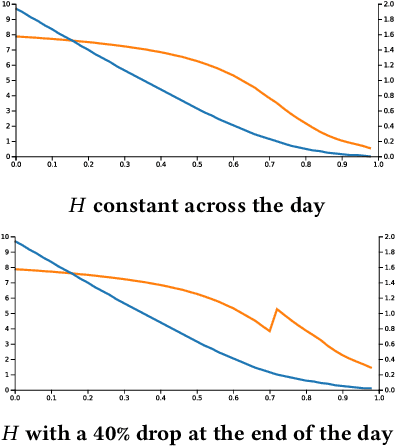
Over the last decade, digital media (web or app publishers) generalized the use of real time ad auctions to sell their ad spaces. Multiple auction platforms, also called Supply-Side Platforms (SSP), were created. Because of this multiplicity, publishers started to create competition between SSPs. In this setting, there are two successive auctions: a second price auction in each SSP and a secondary, first price auction, called header bidding auction, between SSPs.In this paper, we consider an SSP competing with other SSPs for ad spaces. The SSP acts as an intermediary between an advertiser wanting to buy ad spaces and a web publisher wanting to sell its ad spaces, and needs to define a bidding strategy to be able to deliver to the advertisers as many ads as possible while spending as little as possible. The revenue optimization of this SSP can be written as a contextual bandit problem, where the context consists of the information available about the ad opportunity, such as properties of the internet user or of the ad placement.Using classical multi-armed bandit strategies (such as the original versions of UCB and EXP3) is inefficient in this setting and yields a low convergence speed, as the arms are very correlated. In this paper we design and experiment a version of the Thompson Sampling algorithm that easily takes this correlation into account. We combine this bayesian algorithm with a particle filter, which permits to handle non-stationarity by sequentially estimating the distribution of the highest bid to beat in order to win an auction. We apply this methodology on two real auction datasets, and show that it significantly outperforms more classical approaches.The strategy defined in this paper is being developed to be deployed on thousands of publishers worldwide.