 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVaR-Optimal Arm Identification in Bandits
Oct 06, 2025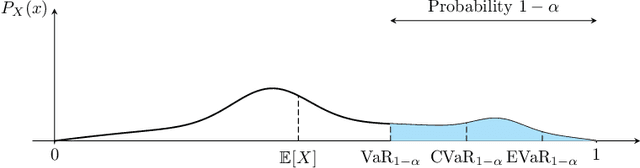
We study the fixed-confidence best arm identification (BAI) problem within the multi-armed bandit (MAB) framework under the Entropic Value-at-Risk (EVaR) criterion. Our analysis considers a nonparametric setting, allowing for general reward distributions bounded in [0,1]. This formulation addresses the critical need for risk-averse decision-making in high-stakes environments, such as finance, moving beyond simple expected value optimization. We propose a $\delta$-correct, Track-and-Stop based algorithm and derive a corresponding lower bound on the expected sample complexity, which we prove is asymptotically matched. The implementation of our algorithm and the characterization of the lower bound both require solving a complex convex optimization problem and a related, simpler non-convex one.
Efficient Risk-sensitive Planning via Entropic Risk Measures
Feb 27, 2025Risk-sensitive planning aims to identify policies maximizing some tail-focused metrics in Markov Decision Processes (MDPs). Such an optimization task can be very costly for the most widely used and interpretable metrics such as threshold probabilities or (Conditional) Values at Risk. Indeed, previous work showed that only Entropic Risk Measures (EntRM) can be efficiently optimized through dynamic programming, leaving a hard-to-interpret parameter to choose. We show that the computation of the full set of optimal policies for EntRM across parameter values leads to tight approximations for the metrics of interest. We prove that this optimality front can be computed effectively thanks to a novel structural analysis and smoothness properties of entropic risks. Empirical results demonstrate that our approach achieves strong performance in a variety of decision-making scenarios.
Identifying the Best Transition Law
Feb 17, 2025Motivated by recursive learning in Markov Decision Processes, this paper studies best-arm identification in bandit problems where each arm's reward is drawn from a multinomial distribution with a known support. We compare the performance { reached by strategies including notably LUCB without and with use of this knowledge. } In the first case, we use classical non-parametric approaches for the confidence intervals. In the second case, where a probability distribution is to be estimated, we first use classical deviation bounds (Hoeffding and Bernstein) on each dimension independently, and then the Empirical Likelihood method (EL-LUCB) on the joint probability vector. The effectiveness of these methods is demonstrated through simulations on scenarios with varying levels of structural complexity.
Sequential Learning of the Pareto Front for Multi-objective Bandits
Jan 29, 2025



We study the problem of sequential learning of the Pareto front in multi-objective multi-armed bandits. An agent is faced with K possible arms to pull. At each turn she picks one, and receives a vector-valued reward. When she thinks she has enough information to identify the Pareto front of the different arm means, she stops the game and gives an answer. We are interested in designing algorithms such that the answer given is correct with probability at least 1-$\delta$. Our main contribution is an efficient implementation of an algorithm achieving the optimal sample complexity when the risk $\delta$ is small. With K arms in d dimensions p of which are in the Pareto set, the algorithm runs in time O(Kp^d) per round.
Beyond Average Return in Markov Decision Processes
Oct 31, 2023What are the functionals of the reward that can be computed and optimized exactly in Markov Decision Processes? In the finite-horizon, undiscounted setting, Dynamic Programming (DP) can only handle these operations efficiently for certain classes of statistics. We summarize the characterization of these classes for policy evaluation, and give a new answer for the planning problem. Interestingly, we prove that only generalized means can be optimized exactly, even in the more general framework of Distributional Reinforcement Learning (DistRL).DistRL permits, however, to evaluate other functionals approximately. We provide error bounds on the resulting estimators, and discuss the potential of this approach as well as its limitations.These results contribute to advancing the theory of Markov Decision Processes by examining overall characteristics of the return, and particularly risk-conscious strategies.
About the Cost of Global Privacy in Density Estimation
Jun 26, 2023
We study non-parametric density estimation for densities in Lipschitz and Sobolev spaces, and under global privacy. In particular, we investigate regimes where the privacy budget is not supposed to be constant. We consider the classical definition of global differential privacy, but also the more recent notion of global concentrated differential privacy. We recover the result of Barber \& Duchi (2014) stating that histogram estimators are optimal against Lipschitz distributions for the L2 risk, and under regular differential privacy, and we extend it to other norms and notions of privacy. Then, we investigate higher degrees of smoothness, drawing two conclusions: First, and contrary to what happens with constant privacy budget (Wasserman \& Zhou, 2010), there are regimes where imposing privacy degrades the regular minimax risk of estimation on Sobolev densities. Second, so-called projection estimators are near-optimal against the same classes of densities in this new setup with pure differential privacy, but contrary to the constant privacy budget case, it comes at the cost of relaxation. With zero concentrated differential privacy, there is no need for relaxation, and we prove that the estimation is optimal.
Private Statistical Estimation of Many Quantiles
Feb 14, 2023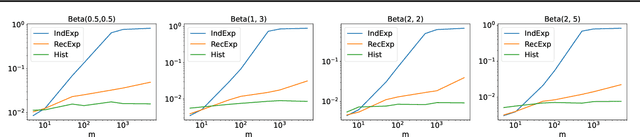
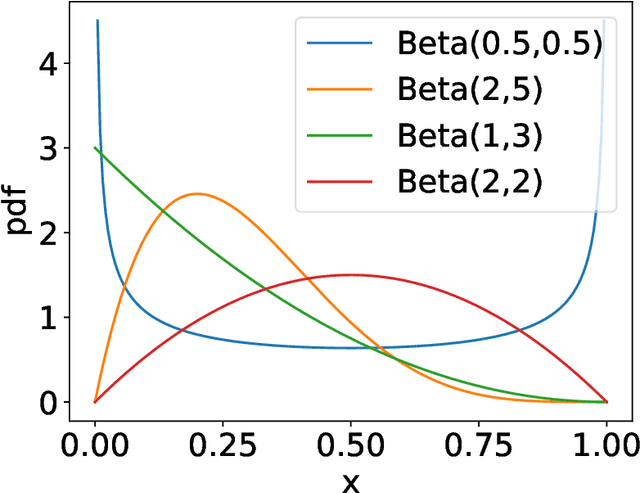
This work studies the estimation of many statistical quantiles under differential privacy. More precisely, given a distribution and access to i.i.d. samples from it, we study the estimation of the inverse of its cumulative distribution function (the quantile function) at specific points. For instance, this task is of key importance in private data generation. We present two different approaches. The first one consists in privately estimating the empirical quantiles of the samples and using this result as an estimator of the quantiles of the distribution. In particular, we study the statistical properties of the recently published algorithm introduced by Kaplan et al. 2022 that privately estimates the quantiles recursively. The second approach is to use techniques of density estimation in order to uniformly estimate the quantile function on an interval. In particular, we show that there is a tradeoff between the two methods. When we want to estimate many quantiles, it is better to estimate the density rather than estimating the quantile function at specific points.
Regret Analysis of the Stochastic Direct Search Method for Blind Resource Allocation
Oct 11, 2022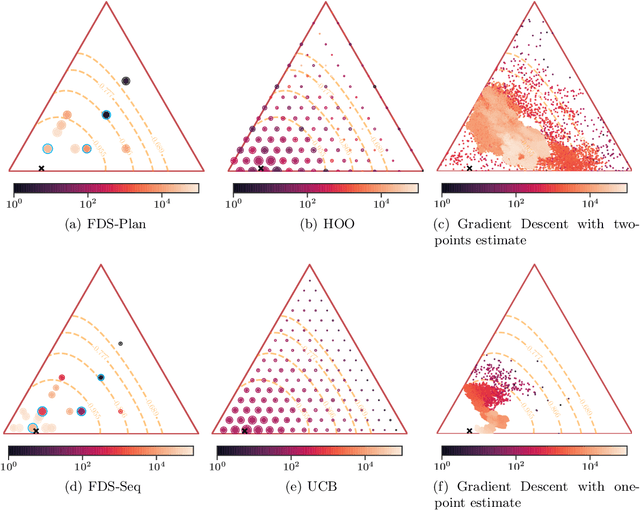
Motivated by programmatic advertising optimization, we consider the task of sequentially allocating budget across a set of resources. At every time step, a feasible allocation is chosen and only a corresponding random return is observed. The goal is to maximize the cumulative expected sum of returns. This is a realistic model for budget allocation across subdivisions of marketing campaigns, when the objective is to maximize the number of conversions. We study direct search (aka pattern search) methods for linearly constrained and derivative-free optimization in the presence of noise. Those algorithms are easy to implement and particularly suited to constrained optimization. They have not yet been analyzed from the perspective of cumulative regret. We provide a regret upper-bound of the order of T 2/3 in the general case. Our mathematical analysis also establishes, as a by-product, time-independent regret bounds in the deterministic, unconstrained case. We also propose an improved version of the method relying on sequential tests to accelerate the identification of descent directions.
On the Statistical Complexity of Estimation and Testing under Privacy Constraints
Oct 05, 2022Producing statistics that respect the privacy of the samples while still maintaining their accuracy is an important topic of research. We study minimax lower bounds when the class of estimators is restricted to the differentially private ones. In particular, we show that characterizing the power of a distributional test under differential privacy can be done by solving a transport problem. With specific coupling constructions, this observation allows us to derivate Le Cam-type and Fano-type inequalities for both regular definitions of differential privacy and for divergence-based ones (based on Renyi divergence). We then proceed to illustrate our results on three simple, fully worked out examples. In particular, we show that the problem class has a huge importance on the provable degradation of utility due to privacy. For some problems, privacy leads to a provable degradation only when the rate of the privacy parameters is small enough whereas for other problem, the degradation systematically occurs under much looser hypotheses on the privacy parametters. Finally, we show that the known privacy guarantees of DP-SGLD, a private convex solver, when used to perform maximum likelihood, leads to an algorithm that is near-minimax optimal in both the sample size and the privacy tuning parameters of the problem for a broad class of parametric estimation procedures that includes exponential families.
On Best-Arm Identification with a Fixed Budget in Non-Parametric Multi-Armed Bandits
Sep 30, 2022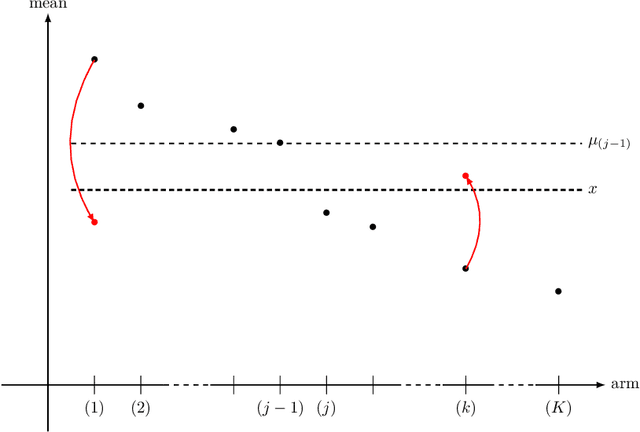
We lay the foundations of a non-parametric theory of best-arm identification in multi-armed bandits with a fixed budget T. We consider general, possibly non-parametric, models D for distributions over the arms; an overarching example is the model D = P(0,1) of all probability distributions over [0,1]. We propose upper bounds on the average log-probability of misidentifying the optimal arm based on information-theoretic quantities that correspond to infima over Kullback-Leibler divergences between some distributions in D and a given distribution. This is made possible by a refined analysis of the successive-rejects strategy of Audibert, Bubeck, and Munos (2010). We finally provide lower bounds on the same average log-probability, also in terms of the same new information-theoretic quantities; these lower bounds are larger when the (natural) assumptions on the considered strategies are stronger. All these new upper and lower bounds generalize existing bounds based, e.g., on gaps between distributions.