 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQD-RL: Efficient Mixing of Quality and Diversity in Reinforcement Learning
Paper and Code
Jun 15, 2020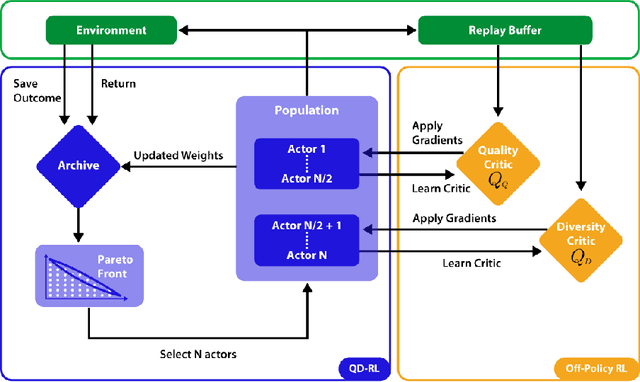
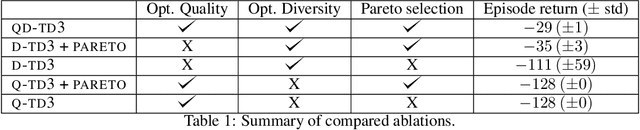
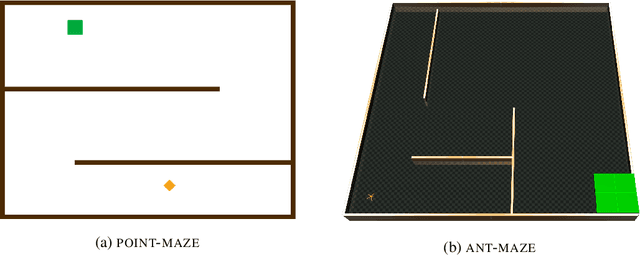
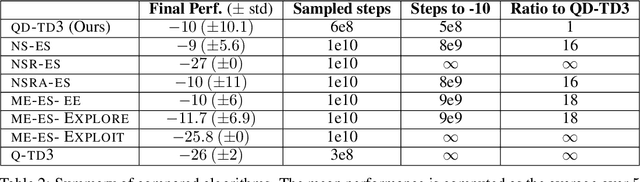
We propose a novel reinforcement learning algorithm,QD-RL, that incorporates the strengths of off-policy RL algorithms into Quality Diversity (QD) approaches. Quality-Diversity methods contribute structural biases by decoupling the search for diversity from the search for high return, resulting in efficient management of the exploration-exploitation trade-off. However, these approaches generally suffer from sample inefficiency as they call upon evolutionary techniques. QD-RL removes this limitation by relying on off-policy RL algorithms. More precisely, we train a population of off-policy deep RL agents to simultaneously maximize diversity inside the population and the return of the agents. QD-RL selects agents from the diversity-return Pareto Front, resulting in stable and efficient population updates. Our experiments on the Ant-Maze environment show that QD-RL can solve challenging exploration and control problems with deceptive rewards while being more than 15 times more sample efficient than its evolutionary counterparts.