 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Ballbot Navigation in Uneven Terrain
May 23, 2025Ballbot (i.e. Ball balancing robot) navigation usually relies on methods rooted in control theory (CT), and works that apply Reinforcement learning (RL) to the problem remain rare while generally being limited to specific subtasks (e.g. balance recovery). Unlike CT based methods, RL does not require (simplifying) assumptions about environment dynamics (e.g. the absence of slippage between the ball and the floor). In addition to this increased accuracy in modeling, RL agents can easily be conditioned on additional observations such as depth-maps without the need for explicit formulations from first principles, leading to increased adaptivity. Despite those advantages, there has been little to no investigation into the capabilities, data-efficiency and limitations of RL based methods for ballbot control and navigation. Furthermore, there is a notable absence of an open-source, RL-friendly simulator for this task. In this paper, we present an open-source ballbot simulation based on MuJoCo, and show that with appropriate conditioning on exteroceptive observations as well as reward shaping, policies learned by classical model-free RL methods are capable of effectively navigating through randomly generated uneven terrain, using a reasonable amount of data (four to five hours on a system operating at 500hz).
Integrating LLMs and Decision Transformers for Language Grounded Generative Quality-Diversity
Aug 25, 2023Quality-Diversity is a branch of stochastic optimization that is often applied to problems from the Reinforcement Learning and control domains in order to construct repertoires of well-performing policies/skills that exhibit diversity with respect to a behavior space. Such archives are usually composed of a finite number of reactive agents which are each associated to a unique behavior descriptor, and instantiating behavior descriptors outside of that coarsely discretized space is not straight-forward. While a few recent works suggest solutions to that issue, the trajectory that is generated is not easily customizable beyond the specification of a target behavior descriptor. We propose to jointly solve those problems in environments where semantic information about static scene elements is available by leveraging a Large Language Model to augment the repertoire with natural language descriptions of trajectories, and training a policy conditioned on those descriptions. Thus, our method allows a user to not only specify an arbitrary target behavior descriptor, but also provide the model with a high-level textual prompt to shape the generated trajectory. We also propose an LLM-based approach to evaluating the performance of such generative agents. Furthermore, we develop a benchmark based on simulated robot navigation in a 2d maze that we use for experimental validation.
Data-efficient, Explainable and Safe Payload Manipulation: An Illustration of the Advantages of Physical Priors in Model-Predictive Control
Mar 02, 2023Machine Learning methods, such as those from the Reinforcement Learning (RL) literature, have increasingly been applied to robot control problems. However, such control methods, even when learning environment dynamics (e.g. as in Model-Based RL/control) often remain data-inefficient. Furthermore, the decisions made by learned policies or the estimations made by learned dynamic models, unlike those made by their hand-designed counterparts, are not readily interpretable by a human user without the use of Explainable AI techniques. This has several disadvantages, such as increased difficulty both in debugging and integration in safety-critical systems. On the other hand, in many robotic systems, prior knowledge of environment kinematics and dynamics is at least partially available (e.g. from classical mechanics). Arguably, incorporating such priors to the environment model or decision process can help address the aforementioned problems: it reduces problem complexity and the needs in terms of exploration, while also facilitating the expression of the decisions taken by the agent in terms of physically meaningful entities. Our aim with this paper is to illustrate and support this point of view. We model a payload manipulation problem based on a real robotic system, and show that leveraging prior knowledge about the dynamics of the environment can lead to improved explainability and an increase in both safety and data-efficiency,leading to satisfying generalization properties with less data.
Meta Neural Ordinary Differential Equations For Adaptive Asynchronous Control
Jul 25, 2022

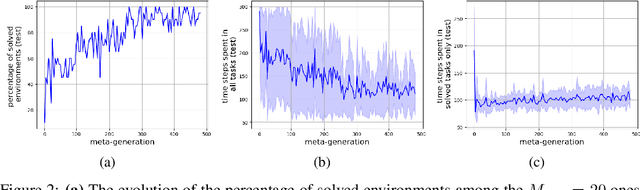
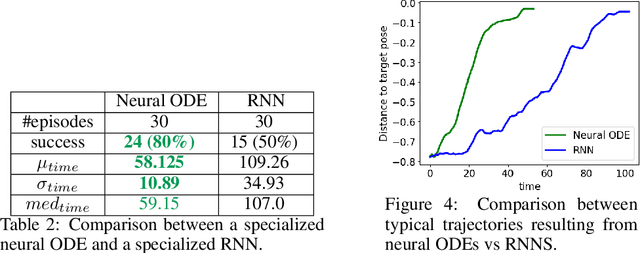
Model-based Reinforcement Learning and Control have demonstrated great potential in various sequential decision making problem domains, including in robotics settings. However, real-world robotics systems often present challenges that limit the applicability of those methods. In particular, we note two problems that jointly happen in many industrial systems: 1) Irregular/asynchronous observations and actions and 2) Dramatic changes in environment dynamics from an episode to another (e.g. varying payload inertial properties). We propose a general framework that overcomes those difficulties by meta-learning adaptive dynamics models for continuous-time prediction and control. We evaluate the proposed approach on a simulated industrial robot. Evaluations on real robotic systems will be added in future iterations of this pre-print.
Towards QD-suite: developing a set of benchmarks for Quality-Diversity algorithms
May 06, 2022



While the field of Quality-Diversity (QD) has grown into a distinct branch of stochastic optimization, a few problems, in particular locomotion and navigation tasks, have become de facto standards. Are such benchmarks sufficient? Are they representative of the key challenges faced by QD algorithms? Do they provide the ability to focus on one particular challenge by properly disentangling it from others? Do they have much predictive power in terms of scalability and generalization? Existing benchmarks are not standardized, and there is currently no MNIST equivalent for QD. Inspired by recent works on Reinforcement Learning benchmarks, we argue that the identification of challenges faced by QD methods and the development of targeted, challenging, scalable but affordable benchmarks is an important step. As an initial effort, we identify three problems that are challenging in sparse reward settings, and propose associated benchmarks: (1) Behavior metric bias, which can result from the use of metrics that do not match the structure of the behavior space. (2) Behavioral Plateaus, with varying characteristics, such that escaping them would require adaptive QD algorithms and (3) Evolvability Traps, where small variations in genotype result in large behavioral changes. The environments that we propose satisfy the properties listed above.
Geodesics, Non-linearities and the Archive of Novelty Search
May 06, 2022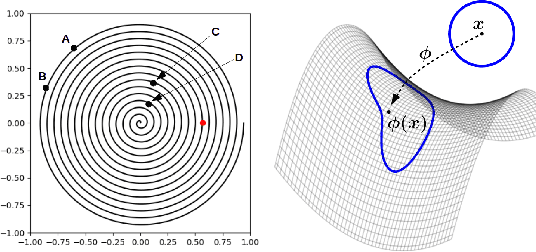


The Novelty Search (NS) algorithm was proposed more than a decade ago. However, the mechanisms behind its empirical success are still not well formalized/understood. This short note focuses on the effects of the archive on exploration. Experimental evidence from a few application domains suggests that archive-based NS performs in general better than when Novelty is solely computed with respect to the population. An argument that is often encountered in the literature is that the archive prevents exploration from backtracking or cycling, i.e. from revisiting previously encountered areas in the behavior space. We argue that this is not a complete or accurate explanation as backtracking - beside often being desirable - can actually be enabled by the archive. Through low-dimensional/analytical examples, we show that a key effect of the archive is that it counterbalances the exploration biases that result, among other factors, from the use of inadequate behavior metrics and the non-linearities of the behavior mapping. Our observations seem to hint that attributing a more active role to the archive in sampling can be beneficial.
* 4 pages, 3 figures
Few-shot Quality-Diversity Optimisation
Sep 14, 2021
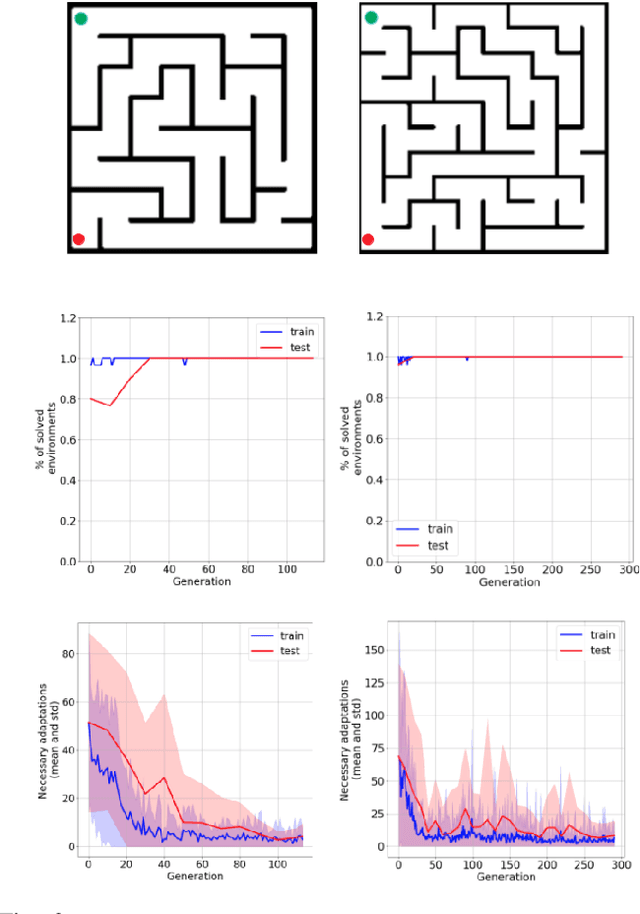

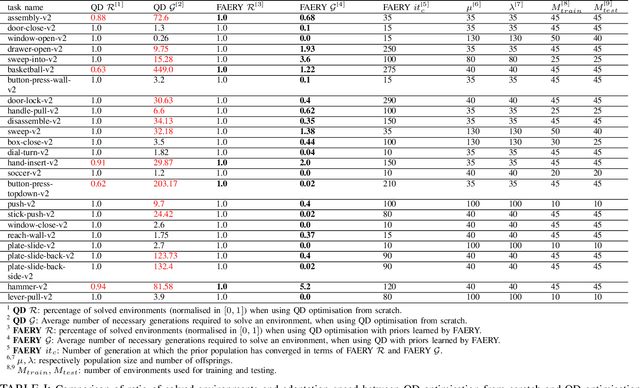
In the past few years, a considerable amount of research has been dedicated to the exploitation of previous learning experiences and the design of Few-shot and Meta Learning approaches, in problem domains ranging from Computer Vision to Reinforcement Learning based control. A notable exception, where to the best of our knowledge, little to no effort has been made in this direction is Quality-Diversity (QD) optimisation. QD methods have been shown to be effective tools in dealing with deceptive minima and sparse rewards in Reinforcement Learning. However, they remain costly due to their reliance on inherently sample inefficient evolutionary processes. We show that, given examples from a task distribution, information about the paths taken by optimisation in parameter space can be leveraged to build a prior population, which when used to initialise QD methods in unseen environments, allows for few-shot adaptation. Our proposed method does not require backpropagation. It is simple to implement and scale, and furthermore, it is agnostic to the underlying models that are being trained. Experiments carried in both sparse and dense reward settings using robotic manipulation and navigation benchmarks show that it considerably reduces the number of generations that are required for QD optimisation in these environments.
BR-NS: an Archive-less Approach to Novelty Search
Apr 08, 2021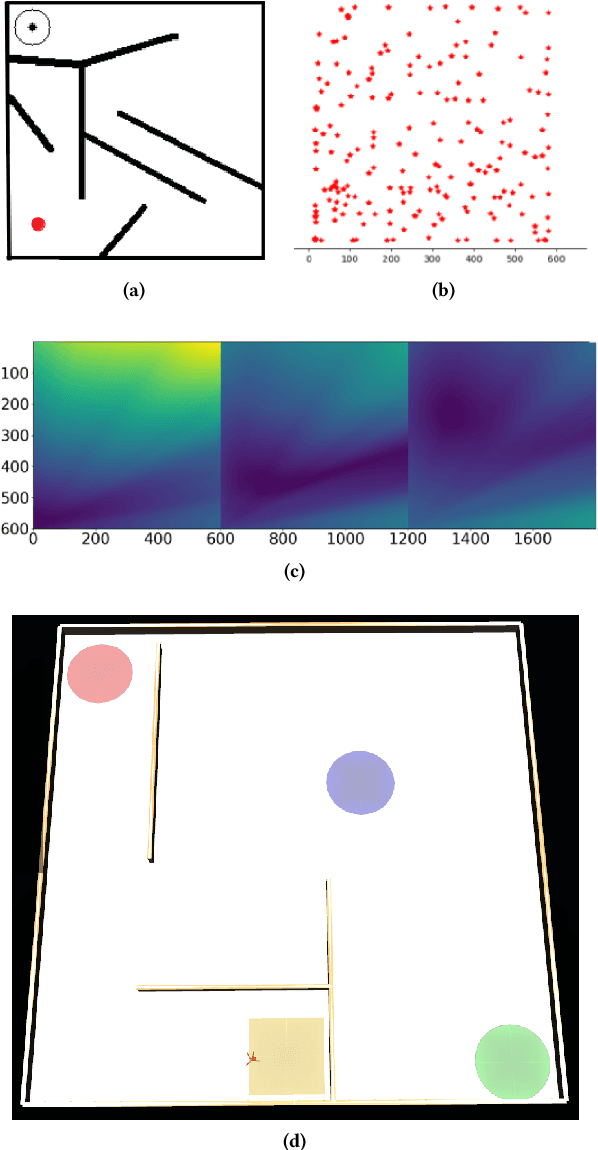
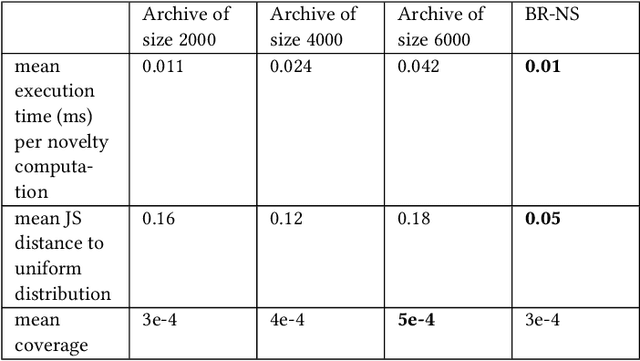
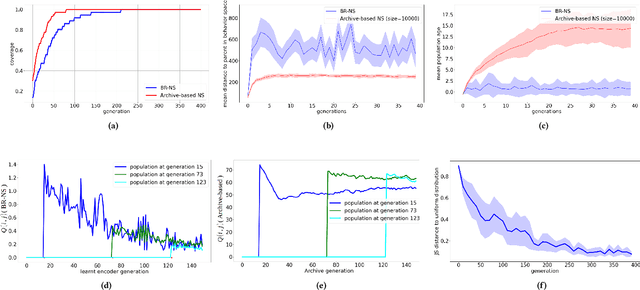
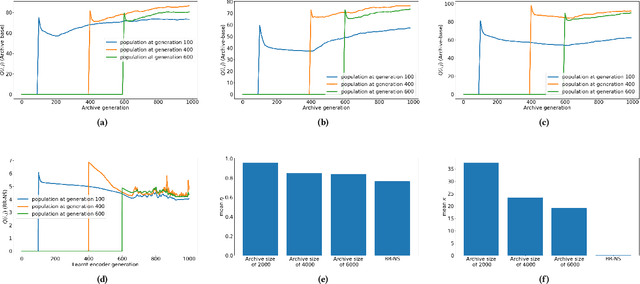
As open-ended learning based on divergent search algorithms such as Novelty Search (NS) draws more and more attention from the research community, it is natural to expect that its application to increasingly complex real-world problems will require the exploration to operate in higher dimensional Behavior Spaces which will not necessarily be Euclidean. Novelty Search traditionally relies on k-nearest neighbours search and an archive of previously visited behavior descriptors which are assumed to live in a Euclidean space. This is problematic because of a number of issues. On one hand, Euclidean distance and Nearest-neighbour search are known to behave differently and become less meaningful in high dimensional spaces. On the other hand, the archive has to be bounded since, memory considerations aside, the computational complexity of finding nearest neighbours in that archive grows linearithmically with its size. A sub-optimal bound can result in "cycling" in the behavior space, which inhibits the progress of the exploration. Furthermore, the performance of NS depends on a number of algorithmic choices and hyperparameters, such as the strategies to add or remove elements to the archive and the number of neighbours to use in k-nn search. In this paper, we discuss an alternative approach to novelty estimation, dubbed Behavior Recognition based Novelty Search (BR-NS), which does not require an archive, makes no assumption on the metrics that can be defined in the behavior space and does not rely on nearest neighbours search. We conduct experiments to gain insight into its feasibility and dynamics as well as potential advantages over archive-based NS in terms of time complexity.