 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating swarms through morphology handling design contingencies: from the sweet spot to a rich expressivity
Jan 12, 2026Morphological computing, the use of the physical design of a robot to ease the realization of a given task has been proven to be a relevant concept in the context of swarm robotics. Here we demonstrate both experimentally and numerically, that the success of such a strategy may heavily rely on the type of policy adopted by the robots, as well as on the details of the physical design. To do so, we consider a swarm of robots, composed of Kilobots embedded in an exoskeleton, the design of which controls the propensity of the robots to align or anti-align with the direction of the external force they experience. We find experimentally that the contrast that was observed between the two morphologies in the success rate of a simple phototactic task, where the robots were programmed to stop when entering a light region, becomes dramatic, if the robots are not allowed to stop, and can only slow down. Building on a faithful physical model of the self-aligning dynamics of the robots, we perform numerical simulations and demonstrate on one hand that a precise tuning of the self-aligning strength around a sweet spot is required to achieve an efficient phototactic behavior, on the other hand that exploring a range of self-alignment strength allows for a rich expressivity of collective behaviors.
Pobogot -- An Open-Hardware Open-Source Low Cost Robot for Swarm Robotics
Apr 11, 2025This paper describes the Pogobot, an open-source and open-hardware platform specifically designed for research involving swarm robotics. Pogobot features vibration-based locomotion, infrared communication, and an array of sensors in a cost-effective package (approx. 250~euros/unit). The platform's modular design, comprehensive API, and extensible architecture facilitate the implementation of swarm intelligence algorithms and distributed online reinforcement learning algorithms. Pogobots offer an accessible alternative to existing platforms while providing advanced capabilities including directional communication between units. More than 200 Pogobots are already being used on a daily basis at Sorbonne Universit\'e and PSL to study self-organizing systems, programmable active matter, discrete reaction-diffusion-advection systems as well as models of social learning and evolution.
Signaling and Social Learning in Swarms of Robots
Nov 19, 2024This paper investigates the role of communication in improving coordination within robot swarms, focusing on a paradigm where learning and execution occur simultaneously in a decentralized manner. We highlight the role communication can play in addressing the credit assignment problem (individual contribution to the overall performance), and how it can be influenced by it. We propose a taxonomy of existing and future works on communication, focusing on information selection and physical abstraction as principal axes for classification: from low-level lossless compression with raw signal extraction and processing to high-level lossy compression with structured communication models. The paper reviews current research from evolutionary robotics, multi-agent (deep) reinforcement learning, language models, and biophysics models to outline the challenges and opportunities of communication in a collective of robots that continuously learn from one another through local message exchanges, illustrating a form of social learning.
Hearing the shape of an arena with spectral swarm robotics
Mar 25, 2024Swarm robotics promises adaptability to unknown situations and robustness against failures. However, it still struggles with global tasks that require understanding the broader context in which the robots operate, such as identifying the shape of the arena in which the robots are embedded. Biological swarms, such as shoals of fish, flocks of birds, and colonies of insects, routinely solve global geometrical problems through the diffusion of local cues. This paradigm can be explicitly described by mathematical models that could be directly computed and exploited by a robotic swarm. Diffusion over a domain is mathematically encapsulated by the Laplacian, a linear operator that measures the local curvature of a function. Crucially the geometry of a domain can generally be reconstructed from the eigenspectrum of its Laplacian. Here we introduce spectral swarm robotics where robots diffuse information to their neighbors to emulate the Laplacian operator - enabling them to "hear" the spectrum of their arena. We reveal a universal scaling that links the optimal number of robots (a global parameter) with their optimal radius of interaction (a local parameter). We validate experimentally spectral swarm robotics under challenging conditions with the one-shot classification of arena shapes using a sparse swarm of Kilobots. Spectral methods can assist with challenging tasks where robots need to build an emergent consensus on their environment, such as adaptation to unknown terrains, division of labor, or quorum sensing. Spectral methods may extend beyond robotics to analyze and coordinate swarms of agents of various natures, such as traffic or crowds, and to better understand the long-range dynamics of natural systems emerging from short-range interactions.
Joint Intrinsic Motivation for Coordinated Exploration in Multi-Agent Deep Reinforcement Learning
Feb 06, 2024Multi-agent deep reinforcement learning (MADRL) problems often encounter the challenge of sparse rewards. This challenge becomes even more pronounced when coordination among agents is necessary. As performance depends not only on one agent's behavior but rather on the joint behavior of multiple agents, finding an adequate solution becomes significantly harder. In this context, a group of agents can benefit from actively exploring different joint strategies in order to determine the most efficient one. In this paper, we propose an approach for rewarding strategies where agents collectively exhibit novel behaviors. We present JIM (Joint Intrinsic Motivation), a multi-agent intrinsic motivation method that follows the centralized learning with decentralized execution paradigm. JIM rewards joint trajectories based on a centralized measure of novelty designed to function in continuous environments. We demonstrate the strengths of this approach both in a synthetic environment designed to reveal shortcomings of state-of-the-art MADRL methods, and in simulated robotic tasks. Results show that joint exploration is crucial for solving tasks where the optimal strategy requires a high level of coordination.
Reactive Stepping for Humanoid Robots using Reinforcement Learning: Application to Standing Push Recovery on the Exoskeleton Atalante
Mar 02, 2022
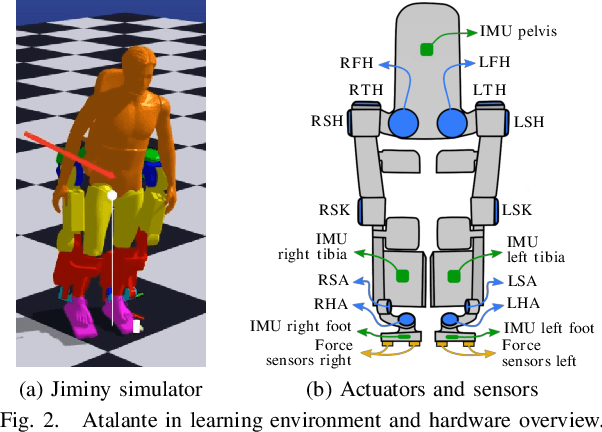


State-of-the-art reinforcement learning is now able to learn versatile locomotion, balancing and push-recovery capabilities for bipedal robots in simulation. Yet, the reality gap has mostly been overlooked and the simulated results hardly transfer to real hardware. Either it is unsuccessful in practice because the physics is over-simplified and hardware limitations are ignored, or regularity is not guaranteed and unexpected hazardous motions can occur. This paper presents a reinforcement learning framework capable of learning robust standing push recovery for bipedal robots with a smooth out-of-the-box transfer to reality, requiring only instantaneous proprioceptive observations. By combining original termination conditions and policy smoothness conditioning, we achieve stable learning, sim-to-real transfer and safety using a policy without memory nor observation history. Reward shaping is then used to give insights into how to keep balance. We demonstrate its performance in reality on the lower-limb medical exoskeleton Atalante.
Meta-control of social learning strategies
Jun 18, 2021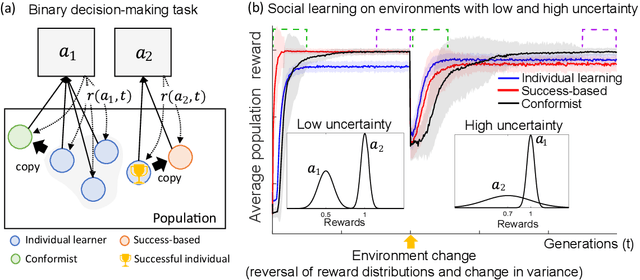

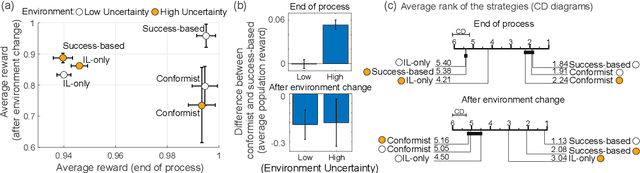

Social learning, copying other's behavior without actual experience, offers a cost-effective means of knowledge acquisition. However, it raises the fundamental question of which individuals have reliable information: successful individuals versus the majority. The former and the latter are known respectively as success-based and conformist social learning strategies. We show here that while the success-based strategy fully exploits the benign environment of low uncertainly, it fails in uncertain environments. On the other hand, the conformist strategy can effectively mitigate this adverse effect. Based on these findings, we hypothesized that meta-control of individual and social learning strategies provides effective and sample-efficient learning in volatile and uncertain environments. Simulations on a set of environments with various levels of volatility and uncertainty confirmed our hypothesis. The results imply that meta-control of social learning affords agents the leverage to resolve environmental uncertainty with minimal exploration cost, by exploiting others' learning as an external knowledge base.
Policy Search with Rare Significant Events: Choosing the Right Partner to Cooperate with
Mar 11, 2021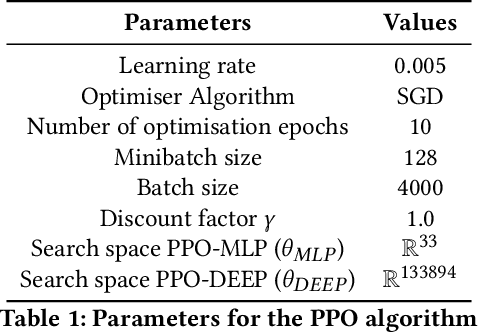
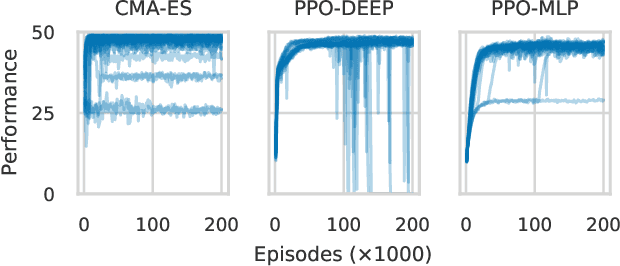
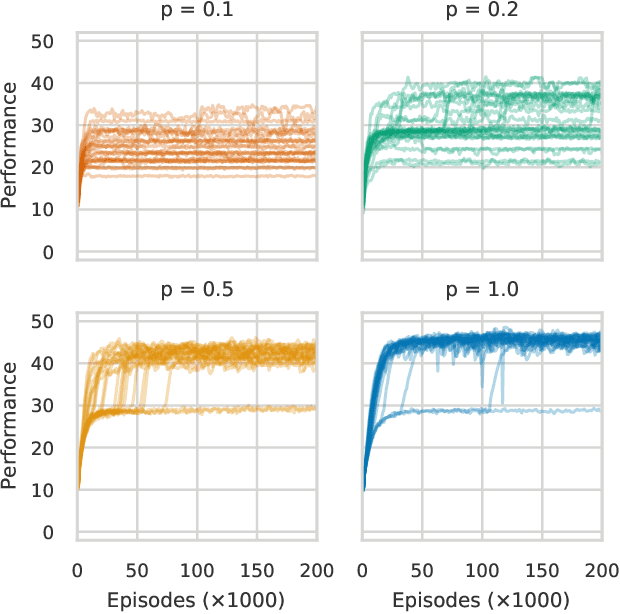

This paper focuses on a class of reinforcement learning problems where significant events are rare and limited to a single positive reward per episode. A typical example is that of an agent who has to choose a partner to cooperate with, while a large number of partners are simply not interested in cooperating, regardless of what the agent has to offer. We address this problem in a continuous state and action space with two different kinds of search methods: a gradient policy search method and a direct policy search method using an evolution strategy. We show that when significant events are rare, gradient information is also scarce, making it difficult for policy gradient search methods to find an optimal policy, with or without a deep neural architecture. On the other hand, we show that direct policy search methods are invariant to the rarity of significant events, which is yet another confirmation of the unique role evolutionary algorithms has to play as a reinforcement learning method.
DREAM Architecture: a Developmental Approach to Open-Ended Learning in Robotics
May 13, 2020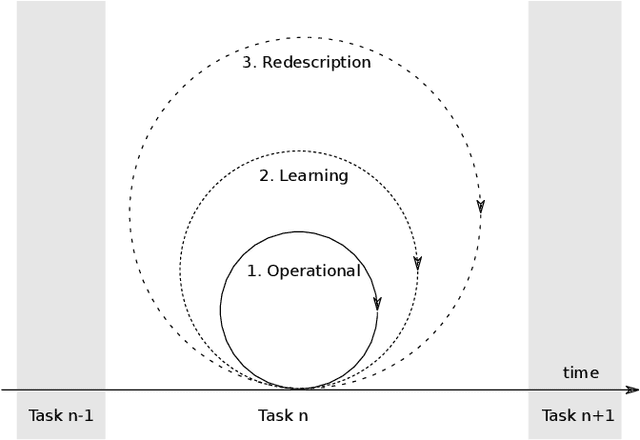
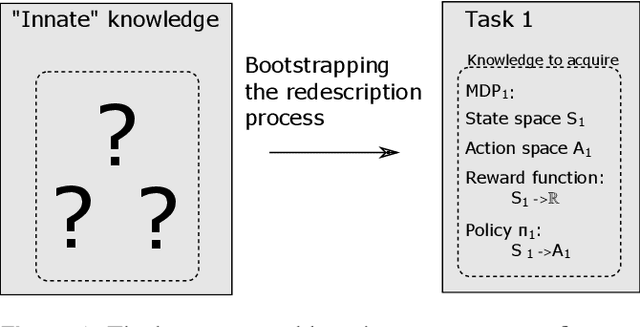
Robots are still limited to controlled conditions, that the robot designer knows with enough details to endow the robot with the appropriate models or behaviors. Learning algorithms add some flexibility with the ability to discover the appropriate behavior given either some demonstrations or a reward to guide its exploration with a reinforcement learning algorithm. Reinforcement learning algorithms rely on the definition of state and action spaces that define reachable behaviors. Their adaptation capability critically depends on the representations of these spaces: small and discrete spaces result in fast learning while large and continuous spaces are challenging and either require a long training period or prevent the robot from converging to an appropriate behavior. Beside the operational cycle of policy execution and the learning cycle, which works at a slower time scale to acquire new policies, we introduce the redescription cycle, a third cycle working at an even slower time scale to generate or adapt the required representations to the robot, its environment and the task. We introduce the challenges raised by this cycle and we present DREAM (Deferred Restructuring of Experience in Autonomous Machines), a developmental cognitive architecture to bootstrap this redescription process stage by stage, build new state representations with appropriate motivations, and transfer the acquired knowledge across domains or tasks or even across robots. We describe results obtained so far with this approach and end up with a discussion of the questions it raises in Neuroscience.
Online Trajectory Planning Through Combined Trajectory Optimization and Function Approximation: Application to the Exoskeleton Atalante
Oct 02, 2019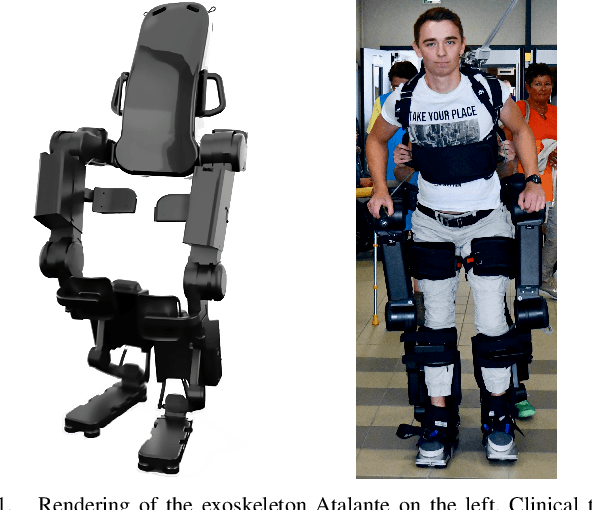
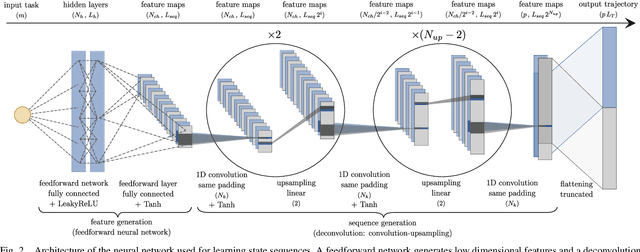
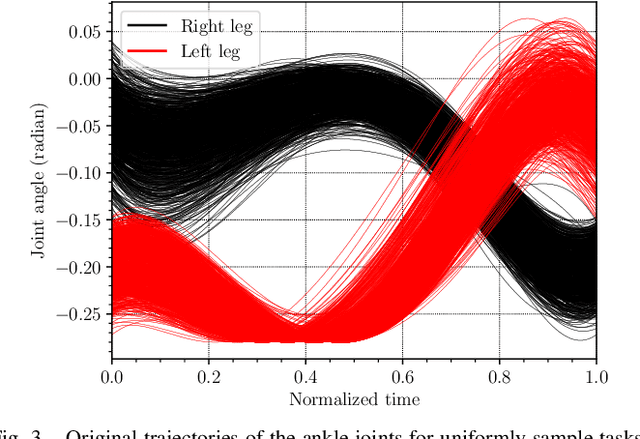

Autonomous robots require online trajectory planning capability to operate in the real world. Efficient offline trajectory planning methods already exist, but are computationally demanding, preventing their use online. In this paper, we present a novel algorithm called Guided Trajectory Learning that learns a function approximation of solutions computed through trajectory optimization while ensuring accurate and reliable predictions. This function approximation is then used online to generate trajectories. This algorithm is designed to be easy to implement, and practical since it does not require massive computing power. It is readily applicable to any robotics systems and effortless to set up on real hardware since robust control strategies are usually already available. We demonstrate the performance of our algorithm on flat-foot walking with the self-balanced exoskeleton Atalante.