 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Geometric Discounts: An Alternative Criterion for Reinforcement Learning
Sep 26, 2022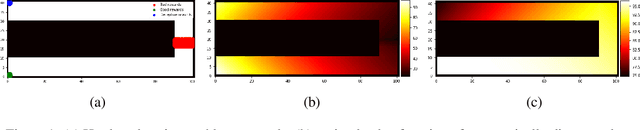

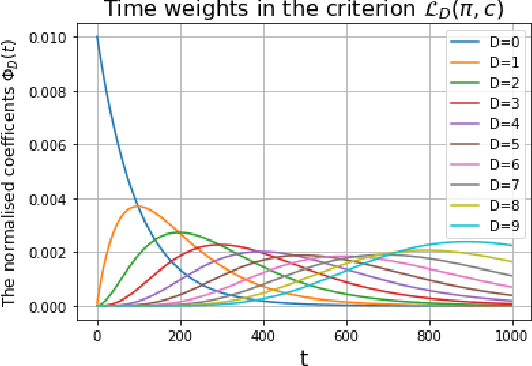
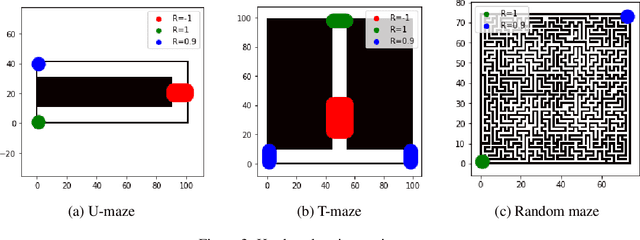
The endeavor of artificial intelligence (AI) is to design autonomous agents capable of achieving complex tasks. Namely, reinforcement learning (RL) proposes a theoretical background to learn optimal behaviors. In practice, RL algorithms rely on geometric discounts to evaluate this optimality. Unfortunately, this does not cover decision processes where future returns are not exponentially less valuable. Depending on the problem, this limitation induces sample-inefficiency (as feed-backs are exponentially decayed) and requires additional curricula/exploration mechanisms (to deal with sparse, deceptive or adversarial rewards). In this paper, we tackle these issues by generalizing the discounted problem formulation with a family of delayed objective functions. We investigate the underlying RL problem to derive: 1) the optimal stationary solution and 2) an approximation of the optimal non-stationary control. The devised algorithms solved hard exploration problems on tabular environment and improved sample-efficiency on classic simulated robotics benchmarks.
Unsupervised Neural Hidden Markov Models with a Continuous latent state space
Jun 10, 2021
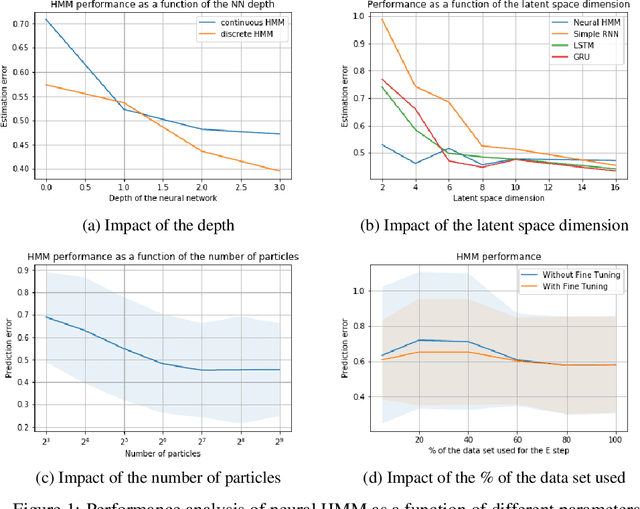
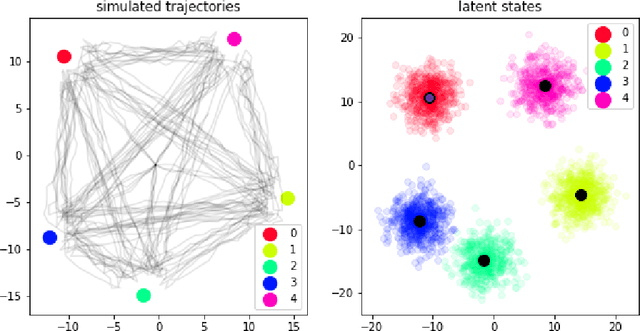
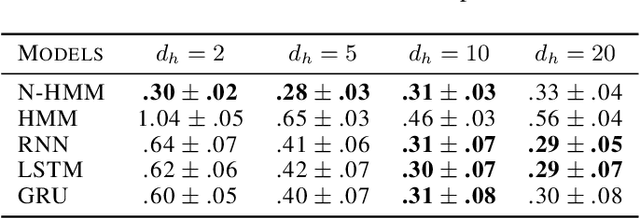
We introduce a new procedure to neuralize unsupervised Hidden Markov Models in the continuous case. This provides higher flexibility to solve problems with underlying latent variables. This approach is evaluated on both synthetic and real data. On top of generating likely model parameters with comparable performances to off-the-shelf neural architecture (LSTMs, GRUs,..), the obtained results are easily interpretable.
Offline Inverse Reinforcement Learning
Jun 09, 2021



The objective of offline RL is to learn optimal policies when a fixed exploratory demonstrations data-set is available and sampling additional observations is impossible (typically if this operation is either costly or rises ethical questions). In order to solve this problem, off the shelf approaches require a properly defined cost function (or its evaluation on the provided data-set), which are seldom available in practice. To circumvent this issue, a reasonable alternative is to query an expert for few optimal demonstrations in addition to the exploratory data-set. The objective is then to learn an optimal policy w.r.t. the expert's latent cost function. Current solutions either solve a behaviour cloning problem (which does not leverage the exploratory data) or a reinforced imitation learning problem (using a fixed cost function that discriminates available exploratory trajectories from expert ones). Inspired by the success of IRL techniques in achieving state of the art imitation performances in online settings, we exploit GAN based data augmentation procedures to construct the first offline IRL algorithm. The obtained policies outperformed the aforementioned solutions on multiple OpenAI gym environments.
Quickest change detection with unknown parameters: Constant complexity and near optimality
Jun 09, 2021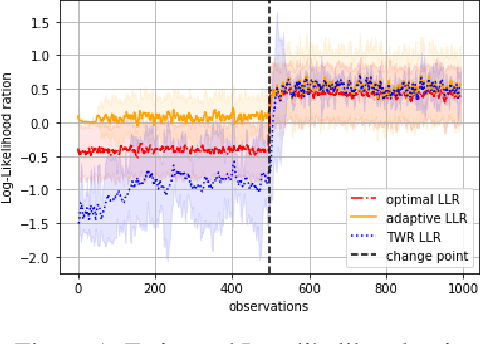
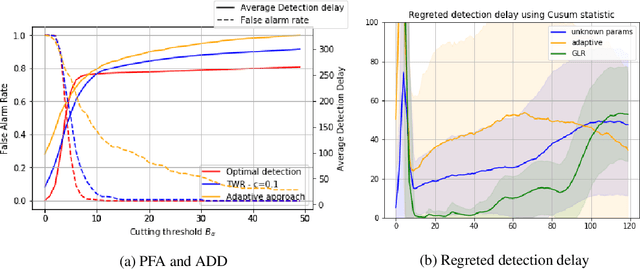
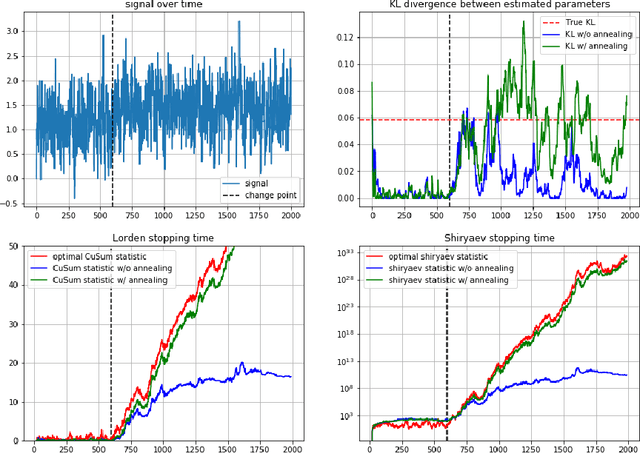
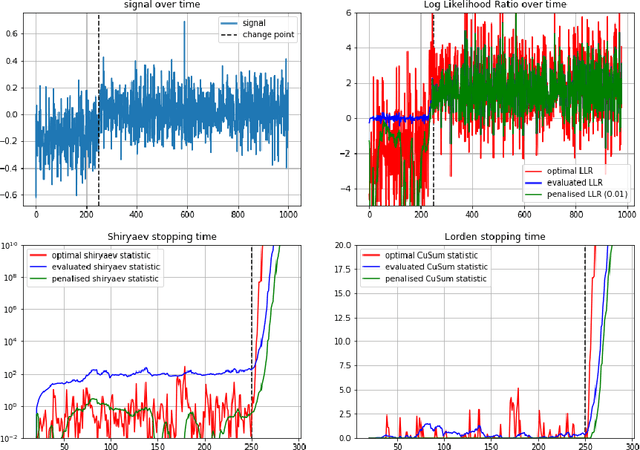
We consider the quickest change detection problem where both the parameters of pre- and post- change distributions are unknown, which prevents the use of classical simple hypothesis testing. Without additional assumptions, optimal solutions are not tractable as they rely on some minimax and robust variant of the objective. As a consequence, change points might be detected too late for practical applications (in economics, health care or maintenance for instance). Available constant complexity techniques typically solve a relaxed version of the problem, deeply relying on very specific probability distributions and/or some very precise additional knowledge. We consider a totally different approach that leverages the theoretical asymptotic properties of optimal solutions to derive a new scalable approximate algorithm with near optimal performance that runs~in~$\mathcal{O}(1)$, adapted to even more complex Markovian settings.
A Generalised Inverse Reinforcement Learning Framework
May 25, 2021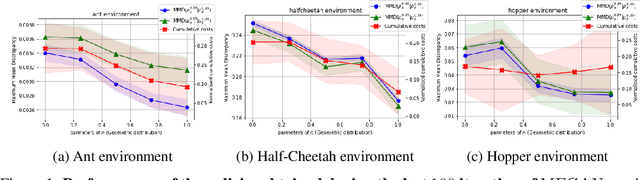
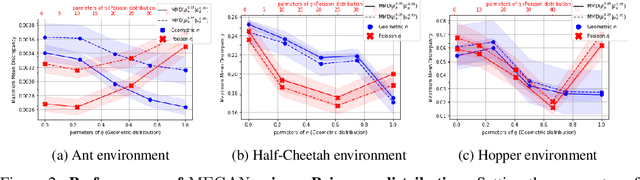
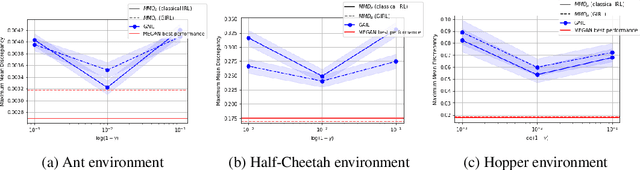
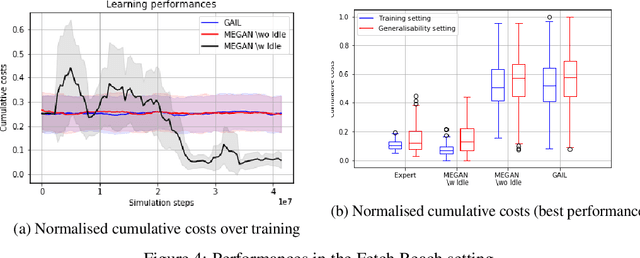
The gloabal objective of inverse Reinforcement Learning (IRL) is to estimate the unknown cost function of some MDP base on observed trajectories generated by (approximate) optimal policies. The classical approach consists in tuning this cost function so that associated optimal trajectories (that minimise the cumulative discounted cost, i.e. the classical RL loss) are 'similar' to the observed ones. Prior contributions focused on penalising degenerate solutions and improving algorithmic scalability. Quite orthogonally to them, we question the pertinence of characterising optimality with respect to the cumulative discounted cost as it induces an implicit bias against policies with longer mixing times. State of the art value based RL algorithms circumvent this issue by solving for the fixed point of the Bellman optimality operator, a stronger criterion that is not well defined for the inverse problem. To alleviate this bias in IRL, we introduce an alternative training loss that puts more weights on future states which yields a reformulation of the (maximum entropy) IRL problem. The algorithms we devised exhibit enhanced performances (and similar tractability) than off-the-shelf ones in multiple OpenAI gym environments.
Markov Decision Process for MOOC users behavioral inference
Jul 10, 2019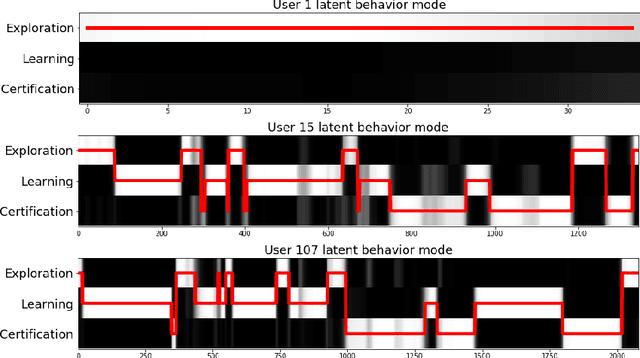
Studies on massive open online courses (MOOCs) users discuss the existence of typical profiles and their impact on the learning process of the students. However defining the typical behaviors as well as classifying the users accordingly is a difficult task. In this paper we suggest two methods to model MOOC users behaviour given their log data. We mold their behavior into a Markov Decision Process framework. We associate the user's intentions with the MDP reward and argue that this allows us to classify them.