 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre standard Object Segmentation models sufficient for Learning Affordance Segmentation?
Paper and Code
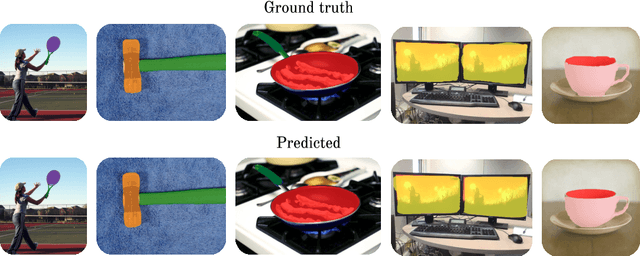
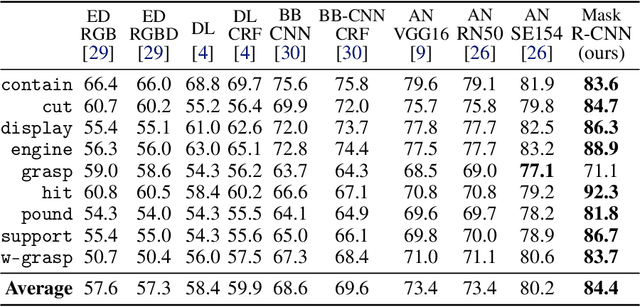
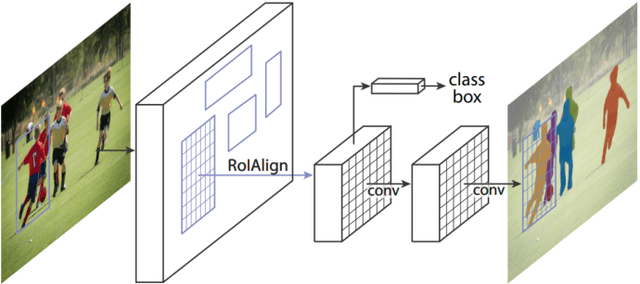
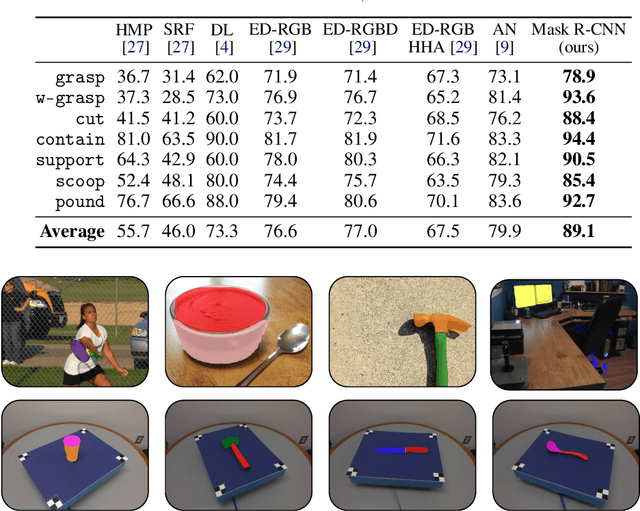
Affordances are the possibilities of actions the environment offers to the individual. Ordinary objects (hammer, knife) usually have many affordances (grasping, pounding, cutting), and detecting these allow artificial agents to understand what are their possibilities in the environment, with obvious application in Robotics. Proposed benchmarks and state-of-the-art prediction models for supervised affordance segmentation are usually modifications of popular object segmentation models such as Mask R-CNN. We observe that theoretically, these popular object segmentation methods should be sufficient for detecting affordances masks. So we ask the question: is it necessary to tailor new architectures to the problem of learning affordances? We show that applying the out-of-the-box Mask R-CNN to the problem of affordances segmentation outperforms the current state-of-the-art. We conclude that the problem of supervised affordance segmentation is included in the problem of object segmentation and argue that better benchmarks for affordance learning should include action capacities.