 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate LoRA Fine-tuning of Open-Source LLMs with Homomorphic Encryption
May 12, 2025Preserving data confidentiality during the fine-tuning of open-source Large Language Models (LLMs) is crucial for sensitive applications. This work introduces an interactive protocol adapting the Low-Rank Adaptation (LoRA) technique for private fine-tuning. Homomorphic Encryption (HE) protects the confidentiality of training data and gradients handled by remote worker nodes performing the bulk of computations involving the base model weights. The data owner orchestrates training, requiring minimal local computing power and memory, thus alleviating the need for expensive client-side GPUs. We demonstrate feasibility by fine-tuning a Llama-3.2-1B model, presenting convergence results using HE-compatible quantization and performance benchmarks for HE computations on GPU hardware. This approach enables applications such as confidential knowledge base question answering, private codebase fine-tuning for AI code assistants, AI agents for drafting emails based on a company's email archive, and adapting models to analyze sensitive legal or healthcare documents.
Neural Network Training on Encrypted Data with TFHE
Jan 29, 2024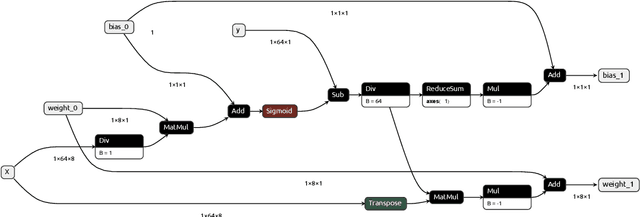

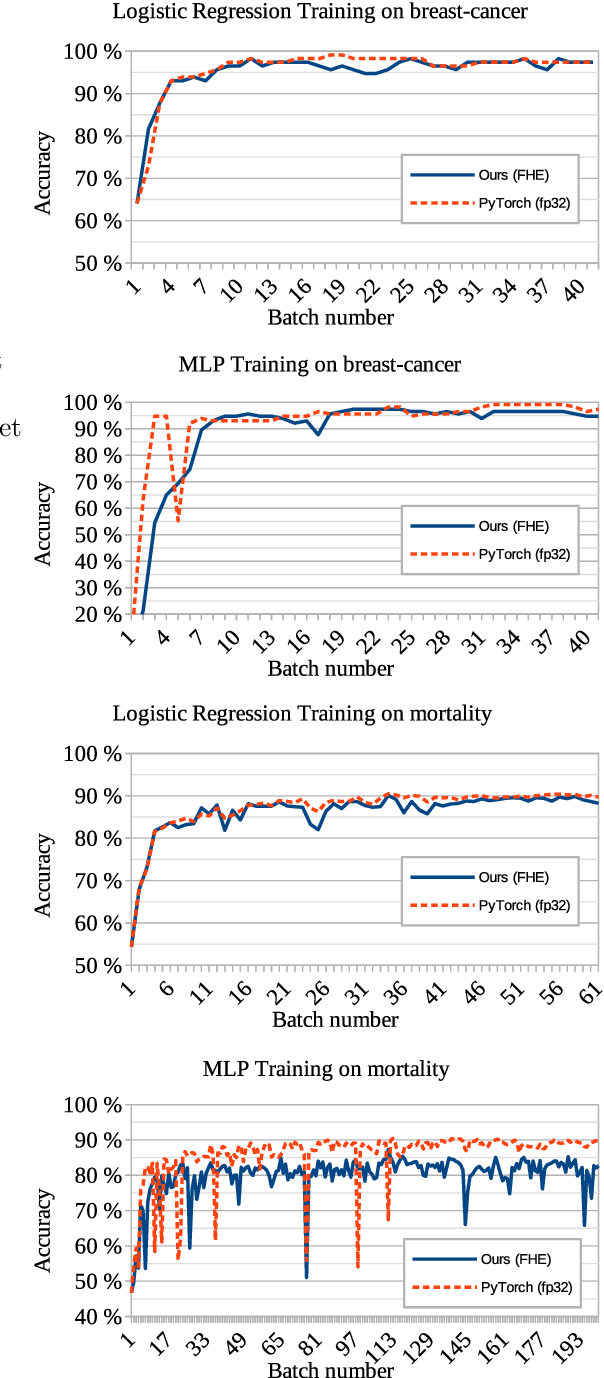
We present an approach to outsourcing of training neural networks while preserving data confidentiality from malicious parties. We use fully homomorphic encryption to build a unified training approach that works on encrypted data and learns quantized neural network models. The data can be horizontally or vertically split between multiple parties, enabling collaboration on confidential data. We train logistic regression and multi-layer perceptrons on several datasets.
Deep Neural Networks for Encrypted Inference with TFHE
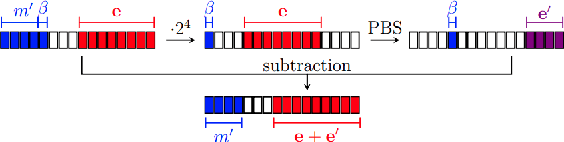
Feb 13, 2023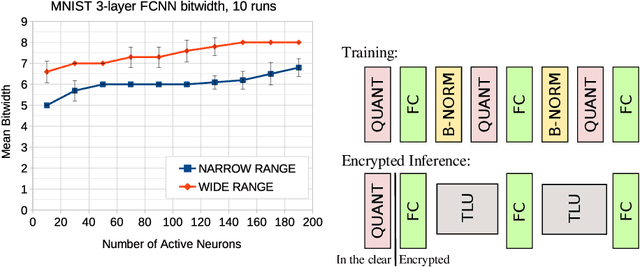
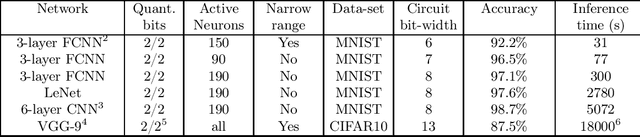
Fully homomorphic encryption (FHE) is an encryption method that allows to perform computation on encrypted data, without decryption. FHE preserves the privacy of the users of online services that handle sensitive data, such as health data, biometrics, credit scores and other personal information. A common way to provide a valuable service on such data is through machine learning and, at this time, Neural Networks are the dominant machine learning model for unstructured data. In this work we show how to construct Deep Neural Networks (DNN) that are compatible with the constraints of TFHE, an FHE scheme that allows arbitrary depth computation circuits. We discuss the constraints and show the architecture of DNNs for two computer vision tasks. We benchmark the architectures using the Concrete stack, an open-source implementation of TFHE.
Privacy-Preserving Tree-Based Inference with Fully Homomorphic Encryption
Feb 13, 2023Privacy enhancing technologies (PETs) have been proposed as a way to protect the privacy of data while still allowing for data analysis. In this work, we focus on Fully Homomorphic Encryption (FHE), a powerful tool that allows for arbitrary computations to be performed on encrypted data. FHE has received lots of attention in the past few years and has reached realistic execution times and correctness. More precisely, we explain in this paper how we apply FHE to tree-based models and get state-of-the-art solutions over encrypted tabular data. We show that our method is applicable to a wide range of tree-based models, including decision trees, random forests, and gradient boosted trees, and has been implemented within the Concrete-ML library, which is open-source at https://github.com/zama-ai/concrete-ml. With a selected set of use-cases, we demonstrate that our FHE version is very close to the unprotected version in terms of accuracy.
Active learning for interactive satellite image change detection
Oct 08, 2021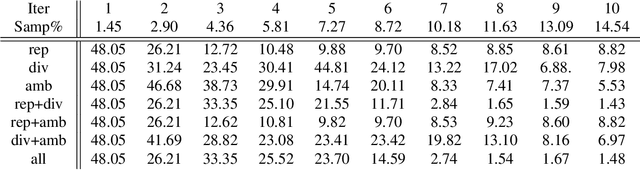
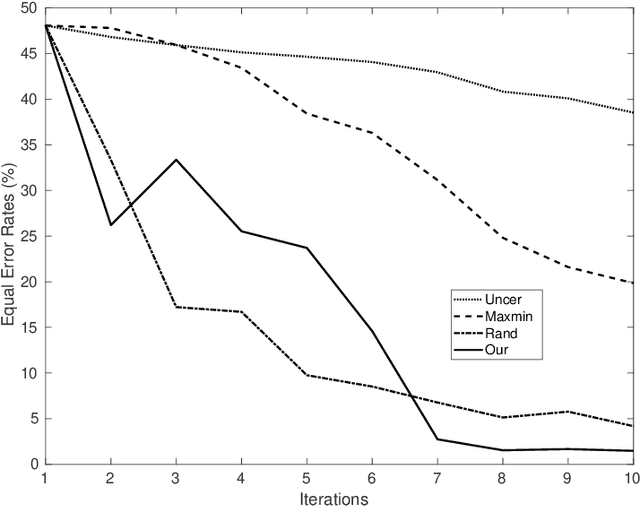
We introduce in this paper a novel active learning algorithm for satellite image change detection. The proposed solution is interactive and based on a question and answer model, which asks an oracle (annotator) the most informative questions about the relevance of sampled satellite image pairs, and according to the oracle's responses, updates a decision function iteratively. We investigate a novel framework which models the probability that samples are relevant; this probability is obtained by minimizing an objective function capturing representativity, diversity and ambiguity. Only data with a high probability according to these criteria are selected and displayed to the oracle for further annotation. Extensive experiments on the task of satellite image change detection after natural hazards (namely tornadoes) show the relevance of the proposed method against the related work.
Regularization Shortcomings for Continual Learning
Dec 06, 2019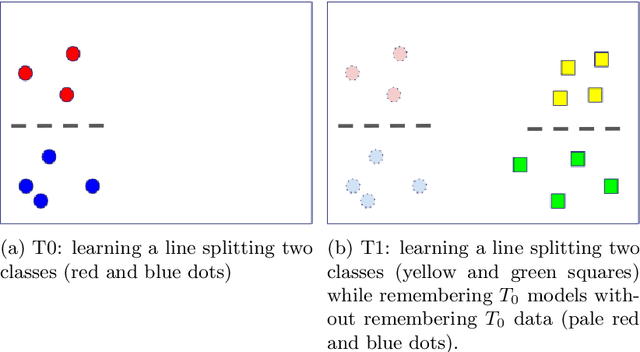
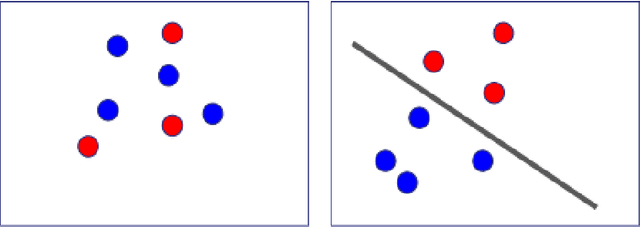
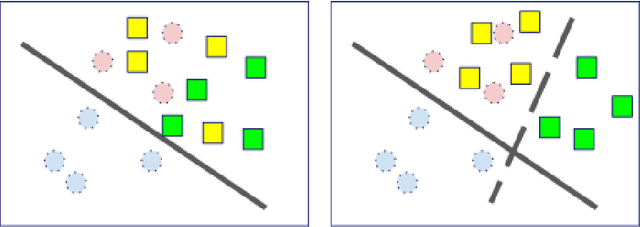

In classical machine learning, the data streamed to the algorithms is assumed to be independent and identically distributed. Otherwise, if the data distribution changes through time, the algorithm risks to remember only the data from the current state of the distribution and forget everything else. Continual learning is a sub-field of machine learning that aims to find automatic learning processes to solve non-iid problems. The main challenges of continual learning are two-fold. Firstly, to detect concept-drift in the distribution and secondly to remember what happened before a concept-drift. In this article, we study a specific case of continual learning approaches: \textit{the regularization method}. It consists of finding a smart regularization term that will protect important parameters from being modified to not forget. We show in this article, that in the context of multi-task learning for classification, this process does not learn to discriminate classes from different tasks. We propose theoretical reasoning to prove this shortcoming and illustrate it with examples and experiments with the "MNIST Fellowship" dataset.
Continual Learning for Robotics
Jun 29, 2019
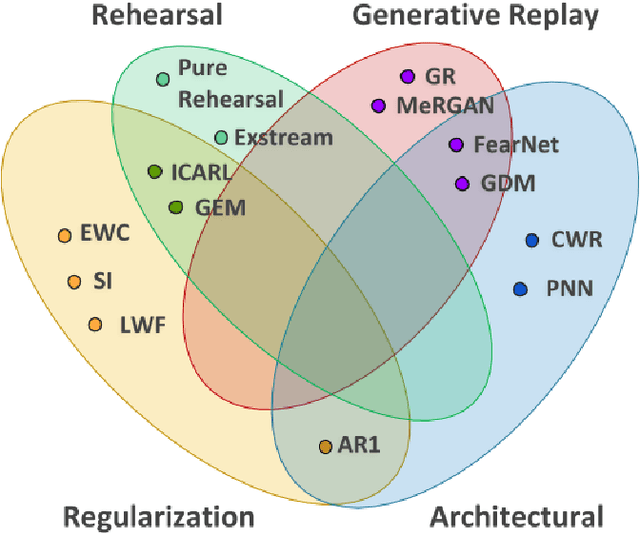
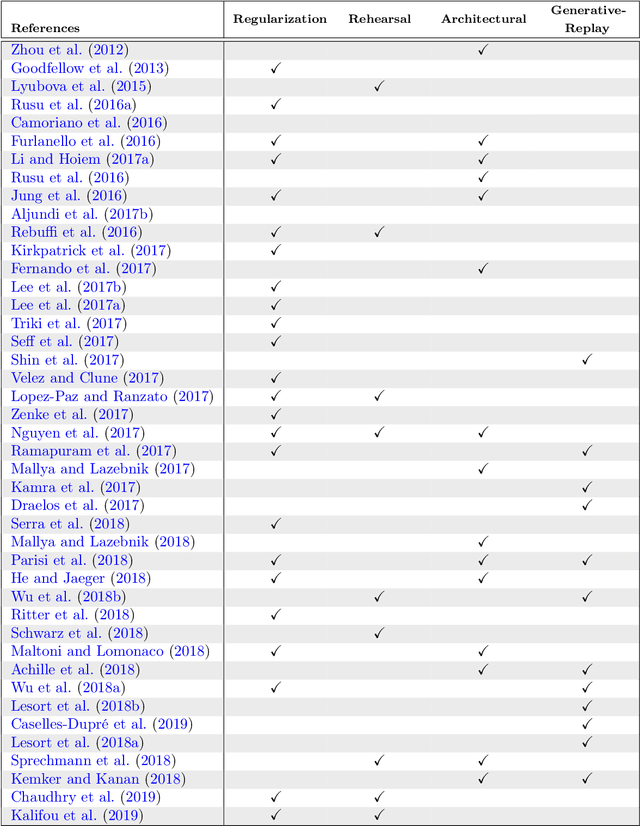

Continual learning (CL) is a particular machine learning paradigm where the data distribution and learning objective changes through time, or where all the training data and objective criteria are never available at once. The evolution of the learning process is modeled by a sequence of learning experiences where the goal is to be able to learn new skills all along the sequence without forgetting what has been previously learned. Continual learning also aims at the same time at optimizing the memory, the computation power and the speed during the learning process. An important challenge for machine learning is not necessarily finding solutions that work in the real world but rather finding stable algorithms that can learn in real world. Hence, the ideal approach would be tackling the real world in a embodied platform: an autonomous agent. Continual learning would then be effective in an autonomous agent or robot, which would learn autonomously through time about the external world, and incrementally develop a set of complex skills and knowledge. Robotic agents have to learn to adapt and interact with their environment using a continuous stream of observations. Some recent approaches aim at tackling continual learning for robotics, but most recent papers on continual learning only experiment approaches in simulation or with static datasets. Unfortunately, the evaluation of those algorithms does not provide insights on whether their solutions may help continual learning in the context of robotics. This paper aims at reviewing the existing state of the art of continual learning, summarizing existing benchmarks and metrics, and proposing a framework for presenting and evaluating both robotics and non robotics approaches in a way that makes transfer between both fields easier.
Generative Models from the perspective of Continual Learning
Dec 21, 2018
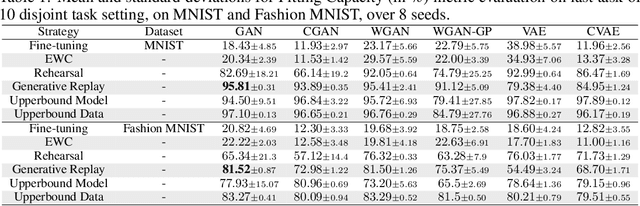


Which generative model is the most suitable for Continual Learning? This paper aims at evaluating and comparing generative models on disjoint sequential image generation tasks. We investigate how several models learn and forget, considering various strategies: rehearsal, regularization, generative replay and fine-tuning. We used two quantitative metrics to estimate the generation quality and memory ability. We experiment with sequential tasks on three commonly used benchmarks for Continual Learning (MNIST, Fashion MNIST and CIFAR10). We found that among all models, the original GAN performs best and among Continual Learning strategies, generative replay outperforms all other methods. Even if we found satisfactory combinations on MNIST and Fashion MNIST, training generative models sequentially on CIFAR10 is particularly instable, and remains a challenge. Our code is available online \footnote{\url{https://github.com/TLESORT/Generative\_Continual\_Learning}}.
Marginal Replay vs Conditional Replay for Continual Learning
Oct 29, 2018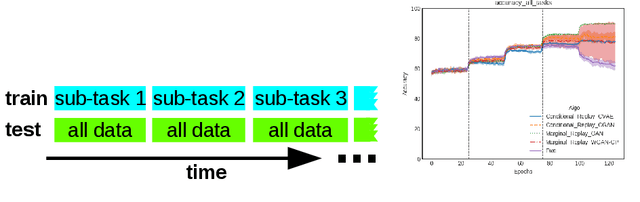



We present a new replay-based method of continual classification learning that we term "conditional replay" which generates samples and labels together by sampling from a distribution conditioned on the class. We compare conditional replay to another replay-based continual learning paradigm (which we term "marginal replay") that generates samples independently of their class and assigns labels in a separate step. The main improvement in conditional replay is that labels for generated samples need not be inferred, which reduces the margin for error in complex continual classification learning tasks. We demonstrate the effectiveness of this approach using novel and standard benchmarks constructed from MNIST and FashionMNIST data, and compare to the regularization-based EWC method.