 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization Shortcomings for Continual Learning
Paper and Code
Dec 06, 2019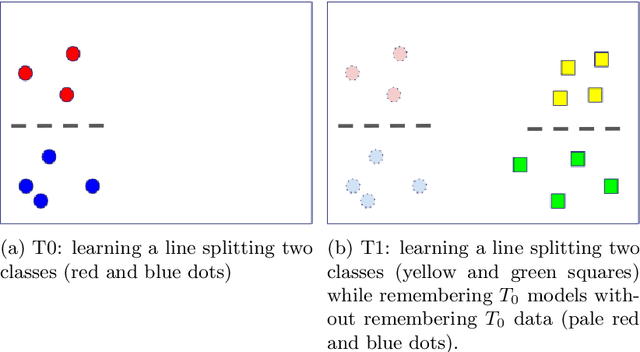
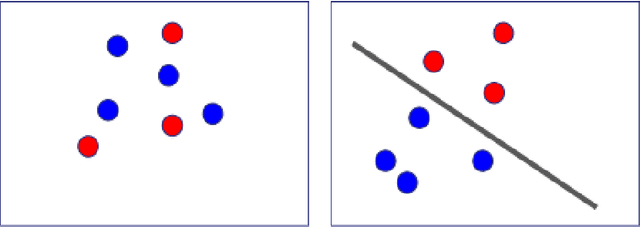
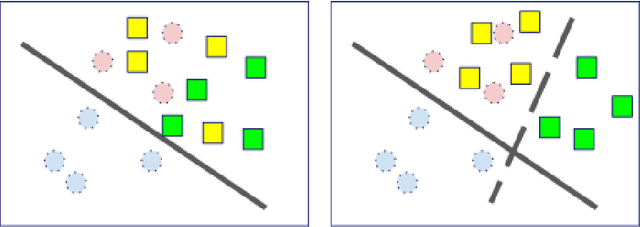

In classical machine learning, the data streamed to the algorithms is assumed to be independent and identically distributed. Otherwise, if the data distribution changes through time, the algorithm risks to remember only the data from the current state of the distribution and forget everything else. Continual learning is a sub-field of machine learning that aims to find automatic learning processes to solve non-iid problems. The main challenges of continual learning are two-fold. Firstly, to detect concept-drift in the distribution and secondly to remember what happened before a concept-drift. In this article, we study a specific case of continual learning approaches: \textit{the regularization method}. It consists of finding a smart regularization term that will protect important parameters from being modified to not forget. We show in this article, that in the context of multi-task learning for classification, this process does not learn to discriminate classes from different tasks. We propose theoretical reasoning to prove this shortcoming and illustrate it with examples and experiments with the "MNIST Fellowship" dataset.